De POC à Production : Industrialiser votre Prompt Engineering
Votre prompt fonctionne en local… mais comment le déployer à l’échelle ? Gérer les versions ? Monitorer ? Rollback si problème ?
Cet article couvre le passage de POC à Production : architecture, CI/CD, monitoring, et best practices pour opérer des prompts comme du code classique.
POC vs Production : Le Gouffre
| Aspect | POC (Prototype) | Production |
|---|---|---|
| Code | Script Python unique | Architecture multi-couches |
| Prompts | Hardcodés dans code | Versionnés, externalisés (YAML) |
| Tests | Manuels | Automatisés (CI/CD) |
| Déploiement | Copy-paste | Pipeline automatisé |
| Monitoring | print() statements | Prometheus + Grafana |
| Erreurs | Crash complet | Graceful degradation + fallbacks |
| Versions | Aucune | Semantic versioning + changelog |
| Coûts | Inconnus | Trackés temps réel |
La vallée de la mort : 78% des POCs IA n’atteignent jamais la production. La raison #1 : sous-estimation de l’infrastructure nécessaire (versioning, monitoring, fallbacks). Planifiez 3-5x plus de temps pour l’industrialisation que pour le POC initial.
Objectif : Transformer vos prompts en actif industriel scalable et maintenable.
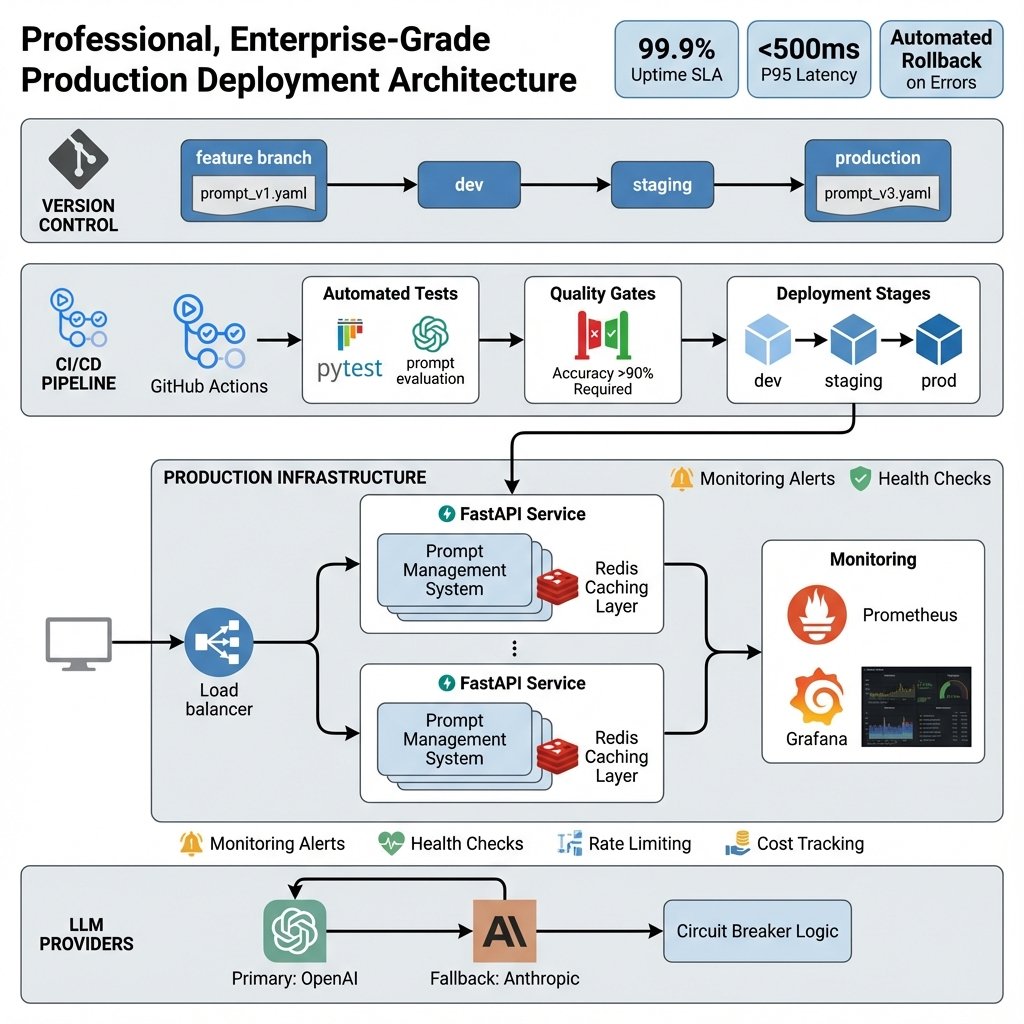
Architecture Production
Stack Technique Recommandée
┌─────────────────────────────────────────────────┐
│ Frontend │
│ (React, Vue, Mobile App, etc.) │
└──────────────────┬──────────────────────────────┘
│ HTTPS / WSS
┌──────────────────▼──────────────────────────────┐
│ API Layer │
│ (FastAPI, Express, Django) │
│ • Authentication (JWT, OAuth) │
│ • Rate Limiting (per user/IP) │
│ • Input Validation │
│ • Logging (requests) │
└──────────────────┬──────────────────────────────┘
│
┌──────────────────▼──────────────────────────────┐
│ Prompt Manager │
│ • Versioning (YAML/JSON) │
│ • Template Engine (Jinja2) │
│ • A/B Testing (traffic split) │
│ • Validation (schema) │
└──────────────────┬──────────────────────────────┘
│
┌──────────────────▼──────────────────────────────┐
│ LLM Gateway │
│ (LiteLLM, Portkey, Custom) │
│ • Model Routing (intelligent) │
│ • Load Balancing (multi-providers) │
│ • Caching (Redis) │
│ • Fallbacks (GPT-4→GPT-3.5→Claude) │
│ • Circuit Breakers │
└──────────────────┬──────────────────────────────┘
│
┌─────────────┼─────────────┬─────────────┐
│ │ │ │
┌────▼────┐ ┌────▼────┐ ┌────▼────┐ ┌────▼────┐
│ OpenAI │ │Anthropic│ │ Google │ │ Local │
│ API │ │ API │ │ Gemini │ │ Model │
└─────────┘ └─────────┘ └─────────┘ └─────────┘
┌─────────────────────────────────────────────────┐
│ Observability Layer │
│ • Logging (LangSmith, Phoenix) │
│ • Metrics (Prometheus) │
│ • Tracing (OpenTelemetry) │
│ • Dashboards (Grafana) │
│ • Alerting (PagerDuty, Slack) │
└─────────────────────────────────────────────────┘
Implémentation API Layer (FastAPI)
from fastapi import FastAPI, HTTPException, Depends, Header
from pydantic import BaseModel, Field
from typing import Optional, Dict
import time
from datetime import datetime
app = FastAPI(title="Prompt Engineering API", version="1.0.0")
# Models
class PromptRequest(BaseModel):
prompt_id: str = Field(..., description="ID du prompt (ex: 'summarization')")
version: str = Field(default="latest", description="Version (ex: '1.2.0' ou 'latest')")
variables: Dict = Field(..., description="Variables pour template")
user_id: str = Field(..., description="ID utilisateur pour analytics")
model: Optional[str] = Field(default=None, description="Modèle LLM (auto si None)")
stream: bool = Field(default=False, description="Streaming response")
class PromptResponse(BaseModel):
output: str
model_used: str
version_used: str
latency_ms: float
tokens: Dict[str, int]
cost_usd: float
cache_hit: bool
# Dépendances
def verify_api_key(x_api_key: str = Header(...)):
"""Vérifier clé API"""
# En production: vérifier en DB/cache
valid_keys = {"sk_test_123", "sk_prod_456"}
if x_api_key not in valid_keys:
raise HTTPException(status_code=401, detail="Invalid API key")
return x_api_key
# Singletons (initialisés au startup)
prompt_manager = None
llm_gateway = None
analytics = None
@app.on_event("startup")
async def startup():
"""Initialiser services"""
global prompt_manager, llm_gateway, analytics
prompt_manager = PromptManager(prompts_dir="./prompts")
llm_gateway = LLMGateway(cache_enabled=True)
analytics = PromptAnalytics(db_path="analytics.db")
# Endpoints
@app.post("/v1/prompt/execute", response_model=PromptResponse)
async def execute_prompt(
request: PromptRequest,
api_key: str = Depends(verify_api_key)
):
"""
Exécuter un prompt géré.
Workflow :
1. Charger template (avec version)
2. Formater avec variables
3. Exécuter via LLM Gateway (routing + caching + fallbacks)
4. Logger analytics
5. Retourner résultat
"""
start_time = time.time()
try:
# 1. Charger prompt template
prompt = prompt_manager.get(
prompt_id=request.prompt_id,
version=request.version
)
# 2. Valider variables
required_vars = [v['name'] for v in prompt.variables if v.get('required', True)]
missing = set(required_vars) - set(request.variables.keys())
if missing:
raise HTTPException(
status_code=400,
detail=f"Missing required variables: {missing}"
)
# 3. Formater template
formatted_prompt = prompt.template.format(**request.variables)
# 4. Exécuter via Gateway
result = await llm_gateway.execute(
prompt=formatted_prompt,
model=request.model, # None = auto-routing
user_id=request.user_id,
stream=request.stream
)
# 5. Logger analytics
latency_ms = (time.time() - start_time) * 1000
analytics.log_execution(PromptExecution(
prompt_id=request.prompt_id,
prompt_version=prompt.version,
model=result['model_used'],
input_text=formatted_prompt,
output_text=result['output'],
input_tokens=result['tokens']['input'],
output_tokens=result['tokens']['output'],
latency_ms=latency_ms,
cost_usd=result['cost'],
user_id=request.user_id,
timestamp=datetime.now(),
metadata={
'cache_hit': result['cache_hit'],
'api_key': api_key[:10] + "..."
}
))
# 6. Retourner
return PromptResponse(
output=result['output'],
model_used=result['model_used'],
version_used=prompt.version,
latency_ms=latency_ms,
tokens=result['tokens'],
cost_usd=result['cost'],
cache_hit=result['cache_hit']
)
except Exception as e:
# Logger erreur
logger.error(f"Error executing prompt: {e}", exc_info=True)
raise HTTPException(status_code=500, detail=str(e))
@app.get("/v1/prompts")
async def list_prompts(api_key: str = Depends(verify_api_key)):
"""Lister tous les prompts disponibles"""
prompts = prompt_manager.list_all()
return {"prompts": prompts}
@app.get("/v1/prompts/{prompt_id}/versions")
async def list_versions(prompt_id: str, api_key: str = Depends(verify_api_key)):
"""Lister versions d'un prompt"""
versions = prompt_manager.list_versions(prompt_id)
return {"prompt_id": prompt_id, "versions": versions}
@app.get("/health")
async def health_check():
"""Health check pour load balancer"""
return {
"status": "healthy",
"timestamp": datetime.now().isoformat(),
"version": "1.0.0"
}
Gestion des Versions
Structure de Répertoire
Semantic versioning obligatoire : Utilisez MAJOR.MINOR.PATCH (ex: 2.1.3). MAJOR = breaking change, MINOR = nouvelle feature rétrocompatible, PATCH = bugfix. Un versioning clair évite 90% des incidents de déploiement (rollback instantané si problème).
prompts/
├── README.md
├── summarization/
│ ├── v1.0.0.yaml (initial release)
│ ├── v1.1.0.yaml (minor: improved instructions)
│ ├── v1.2.0.yaml (minor: added examples)
│ ├── v2.0.0.yaml (major: complete rewrite)
│ └── CHANGELOG.md
├── classification/
│ ├── v1.0.0.yaml
│ ├── v1.1.0.yaml
│ └── CHANGELOG.md
└── translation/
├── v1.0.0.yaml
└── CHANGELOG.md
Format YAML (Standardisé)
# prompts/summarization/v1.2.0.yaml
# Metadata
id: summarization
version: 1.2.0
description: "Summarize articles concisely while preserving key information"
author: "[email protected]"
created_at: "2025-01-15"
tags: ["text-processing", "summarization", "content"]
# Performance metadata (from tests)
metadata:
tested: true
test_date: "2025-01-15"
performance_score: 0.82 # Quality score
avg_cost_usd: 0.015
avg_latency_ms: 1200
recommended_model: "gpt-4-turbo"
# Template (Jinja2 syntax)
template: |
You are an expert summarizer with a talent for extracting key information.
Your task is to summarize the following article in {{max_words}} words or less.
Focus on:
- Main arguments and conclusions
- Key data points and statistics
- Important context
{% if tone %}
Tone: {{tone}}
{% endif %}
Article:
{{article_text}}
Summary:
# Variables definition
variables:
- name: article_text
type: string
required: true
description: "Full text of the article to summarize"
- name: max_words
type: integer
required: false
default: 100
description: "Maximum words for summary"
validation:
min: 20
max: 500
- name: tone
type: string
required: false
default: null
description: "Desired tone (formal, casual, technical)"
enum: ["formal", "casual", "technical"]
# Few-shot examples (optional)
examples:
- input:
article_text: "Artificial intelligence is transforming healthcare..."
max_words: 50
output: "AI is revolutionizing healthcare through improved diagnostics, personalized treatment plans, and drug discovery. Machine learning models can now detect diseases earlier and more accurately than traditional methods."
# Automated tests
tests:
- name: "output_length"
description: "Summary should respect max_words constraint"
input:
article_text: "Long article text here..."
max_words: 100
assertions:
- type: "max_word_count"
value: 120 # Allow 20% margin
- name: "key_terms"
description: "Summary should contain key terms from article"
input:
article_text: "Article about quantum computing and AI..."
max_words: 50
assertions:
- type: "contains_keywords"
keywords: ["quantum", "AI", "computing"]
min_matches: 2
Prompt Manager (Python)
from dataclasses import dataclass
from typing import Dict, List, Any, Optional
import yaml
from pathlib import Path
from jinja2 import Template
@dataclass
class PromptVariable:
name: str
type: str
required: bool
default: Any
description: str
@dataclass
class PromptVersion:
id: str
version: str
description: str
template: str
variables: List[PromptVariable]
metadata: Dict
tests: List[Dict]
def format(self, **kwargs) -> str:
"""Format template with variables using Jinja2"""
jinja_template = Template(self.template)
return jinja_template.render(**kwargs)
class PromptManager:
"""Gestionnaire de prompts avec versioning"""
def __init__(self, prompts_dir: str = "./prompts"):
self.prompts_dir = Path(prompts_dir)
self._cache = {}
def get(self, prompt_id: str, version: str = "latest") -> PromptVersion:
"""
Charger prompt par ID et version.
Args:
prompt_id: ID du prompt (ex: 'summarization')
version: Version spécifique ou 'latest'
Returns:
PromptVersion
"""
# Check cache
cache_key = f"{prompt_id}:{version}"
if cache_key in self._cache:
return self._cache[cache_key]
# Trouver fichier version
prompt_dir = self.prompts_dir / prompt_id
if not prompt_dir.exists():
raise ValueError(f"Prompt '{prompt_id}' not found")
if version == "latest":
# Trouver version la plus récente
version_files = sorted(
prompt_dir.glob("v*.yaml"),
key=lambda p: self._parse_version(p.stem)
)
if not version_files:
raise ValueError(f"No versions found for '{prompt_id}'")
version_file = version_files[-1]
else:
version_file = prompt_dir / f"v{version}.yaml"
if not version_file.exists():
raise ValueError(f"Version {version} not found for '{prompt_id}'")
# Charger YAML
with open(version_file, 'r', encoding='utf-8') as f:
data = yaml.safe_load(f)
# Parser variables
variables = [
PromptVariable(
name=v['name'],
type=v['type'],
required=v.get('required', True),
default=v.get('default'),
description=v.get('description', '')
)
for v in data.get('variables', [])
]
# Créer PromptVersion
prompt = PromptVersion(
id=data['id'],
version=data['version'],
description=data['description'],
template=data['template'],
variables=variables,
metadata=data.get('metadata', {}),
tests=data.get('tests', [])
)
# Cache
self._cache[cache_key] = prompt
return prompt
def list_versions(self, prompt_id: str) -> List[str]:
"""Lister toutes les versions d'un prompt"""
prompt_dir = self.prompts_dir / prompt_id
if not prompt_dir.exists():
return []
versions = [
self._parse_version(f.stem)
for f in sorted(prompt_dir.glob("v*.yaml"))
]
return versions
def list_all(self) -> List[Dict]:
"""Lister tous les prompts disponibles"""
prompts = []
for prompt_dir in self.prompts_dir.iterdir():
if prompt_dir.is_dir() and not prompt_dir.name.startswith('.'):
versions = self.list_versions(prompt_dir.name)
if versions:
latest = self.get(prompt_dir.name, "latest")
prompts.append({
'id': prompt_dir.name,
'description': latest.description,
'versions': versions,
'latest_version': versions[-1]
})
return prompts
@staticmethod
def _parse_version(version_str: str) -> tuple:
"""Parser version string vers tuple (major, minor, patch)"""
# "v1.2.3" → (1, 2, 3)
version_str = version_str.lstrip('v')
parts = version_str.split('.')
return tuple(int(p) for p in parts)
# Utilisation
pm = PromptManager("./prompts")
# Charger latest version
prompt = pm.get("summarization", version="latest")
# Formater avec variables
formatted = prompt.format(
article_text="Long article about AI...",
max_words=100,
tone="technical"
)
print(formatted)
CI/CD Pipeline
Tests Automatisés (Pytest)
# tests/test_prompts.py
import pytest
from pathlib import Path
import yaml
from prompt_manager import PromptManager
from llm_gateway import LLMGateway
@pytest.fixture
def prompt_manager():
return PromptManager("./prompts")
@pytest.fixture
def llm_gateway():
return LLMGateway(cache_enabled=False) # Pas de cache pour tests
class TestPromptValidity:
"""Tests de validité des fichiers YAML"""
def test_all_prompts_valid_yaml(self):
"""Tous les fichiers YAML doivent être parsables"""
for yaml_file in Path("./prompts").rglob("*.yaml"):
with open(yaml_file) as f:
data = yaml.safe_load(f)
# Assertions basiques
assert 'id' in data, f"{yaml_file}: missing 'id'"
assert 'version' in data, f"{yaml_file}: missing 'version'"
assert 'template' in data, f"{yaml_file}: missing 'template'"
assert 'variables' in data, f"{yaml_file}: missing 'variables'"
def test_version_format(self):
"""Versions doivent suivre semver (x.y.z)"""
import re
version_pattern = re.compile(r'^\d+\.\d+\.\d+$')
for yaml_file in Path("./prompts").rglob("v*.yaml"):
with open(yaml_file) as f:
data = yaml.safe_load(f)
version = data.get('version')
assert version_pattern.match(version), \
f"{yaml_file}: invalid version '{version}'"
class TestPromptFunctionality:
"""Tests fonctionnels des prompts"""
def test_summarization_prompt(self, prompt_manager, llm_gateway):
"""Test du prompt de summarization"""
# Charger prompt
prompt = prompt_manager.get("summarization", version="latest")
# Cas de test
test_article = """
Artificial intelligence is rapidly transforming the healthcare industry.
Machine learning algorithms can now diagnose diseases with accuracy
rivaling human experts. Recent studies show AI can detect cancer in
medical imaging with 95% accuracy, compared to 88% for radiologists.
"""
# Formater
formatted = prompt.format(
article_text=test_article,
max_words=50
)
# Exécuter (utiliser modèle cheap pour tests)
result = llm_gateway.execute(
prompt=formatted,
model="gpt-3.5-turbo"
)
output = result['output']
# Assertions
word_count = len(output.split())
assert word_count <= 60, f"Summary too long: {word_count} words"
assert word_count >= 20, f"Summary too short: {word_count} words"
# Keywords présents
assert 'AI' in output or 'artificial intelligence' in output.lower()
assert 'healthcare' in output.lower() or 'medical' in output.lower()
@pytest.mark.parametrize("prompt_id,version", [
("summarization", "latest"),
("classification", "latest"),
])
def test_prompt_automated_tests(self, prompt_manager, llm_gateway, prompt_id, version):
"""Exécuter tests automatisés définis dans YAML"""
prompt = prompt_manager.get(prompt_id, version)
for test in prompt.tests:
# Formater prompt avec inputs de test
formatted = prompt.format(**test['input'])
# Exécuter
result = llm_gateway.execute(formatted, model="gpt-3.5-turbo")
output = result['output']
# Vérifier assertions
for assertion in test.get('assertions', []):
if assertion['type'] == 'max_word_count':
word_count = len(output.split())
assert word_count <= assertion['value'], \
f"Test '{test['name']}' failed: {word_count} > {assertion['value']}"
elif assertion['type'] == 'contains_keywords':
keywords = assertion['keywords']
min_matches = assertion.get('min_matches', len(keywords))
matches = sum(1 for kw in keywords if kw.lower() in output.lower())
assert matches >= min_matches, \
f"Test '{test['name']}' failed: only {matches}/{min_matches} keywords found"
GitHub Actions Workflow
# .github/workflows/test-prompts.yml
name: Test Prompts
on:
pull_request:
paths:
- 'prompts/**'
- 'tests/**'
- 'src/**'
push:
branches:
- main
jobs:
lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Install yamllint
run: pip install yamllint
- name: Lint YAML files
run: yamllint prompts/ --strict
test:
runs-on: ubuntu-latest
needs: lint
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Cache dependencies
uses: actions/cache@v3
with:
path: ~/.cache/pip
key: ${{ runner.os }}-pip-${{ hashFiles('requirements.txt') }}
- name: Install dependencies
run: |
pip install -r requirements.txt
pip install pytest pytest-cov
- name: Run tests
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: |
pytest tests/ -v --cov=src --cov-report=xml
- name: Upload coverage
uses: codecov/codecov-action@v3
with:
files: ./coverage.xml
estimate-costs:
runs-on: ubuntu-latest
needs: test
if: github.event_name == 'pull_request'
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Install dependencies
run: pip install -r requirements.txt
- name: Estimate cost impact
run: |
python scripts/estimate_costs.py \
--base-ref origin/${{ github.base_ref }} \
--head-ref ${{ github.sha }} \
--output costs_report.json
- name: Comment PR with costs
uses: actions/github-script@v7
with:
script: |
const fs = require('fs');
const costs = JSON.parse(fs.readFileSync('costs_report.json', 'utf8'));
const body = `## 💰 Cost Impact Analysis
**Changes detected in prompts:**
${costs.changed_prompts.map(p => `- \`${p.id}\` (v${p.version})`).join('\n')}
**Estimated monthly cost impact:**
- Current: $${costs.current_monthly_cost.toFixed(2)}
- Projected: $${costs.projected_monthly_cost.toFixed(2)}
- Delta: ${costs.delta >= 0 ? '+' : ''}$${costs.delta.toFixed(2)} (${costs.delta_percent.toFixed(1)}%)
${costs.delta > 50 ? '⚠️ **Warning:** Significant cost increase detected!' : '✅ Cost impact acceptable'}
`;
github.rest.issues.createComment({
issue_number: context.issue.number,
owner: context.repo.owner,
repo: context.repo.repo,
body: body
});
deploy:
runs-on: ubuntu-latest
needs: [lint, test]
if: github.ref == 'refs/heads/main'
steps:
- uses: actions/checkout@v4
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v4
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: us-east-1
- name: Deploy prompts to S3
run: |
aws s3 sync ./prompts s3://company-prompts/prod/ \
--delete \
--cache-control max-age=300
- name: Invalidate API cache
run: |
curl -X POST https://api.company.com/v1/admin/cache/invalidate \
-H "Authorization: Bearer ${{ secrets.API_ADMIN_TOKEN }}" \
-H "Content-Type: application/json" \
-d '{"scope": "prompts"}'
- name: Create GitHub Release
uses: actions/create-release@v1
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
with:
tag_name: prompts-${{ github.sha }}
release_name: Prompt Release $(date +'%Y-%m-%d')
body: |
Automated prompt deployment
Commit: ${{ github.sha }}
Author: ${{ github.actor }}
Monitoring et Alerting
Métriques Prometheus
from prometheus_client import Counter, Histogram, Gauge, Info
import time
# Metrics
prompt_executions_total = Counter(
'prompt_executions_total',
'Total number of prompt executions',
['prompt_id', 'version', 'model', 'status'] # Labels
)
prompt_latency_seconds = Histogram(
'prompt_latency_seconds',
'Prompt execution latency in seconds',
['prompt_id', 'model'],
buckets=[0.1, 0.5, 1.0, 2.0, 5.0, 10.0]
)
prompt_cost_usd = Histogram(
'prompt_cost_usd',
'Cost per prompt execution in USD',
['prompt_id', 'model'],
buckets=[0.001, 0.005, 0.01, 0.05, 0.1, 0.5, 1.0]
)
prompt_cache_hits_total = Counter(
'prompt_cache_hits_total',
'Total cache hits',
['prompt_id']
)
active_prompts_count = Gauge(
'active_prompts_count',
'Number of active prompt templates'
)
# Instrumentation
async def execute_prompt_monitored(
prompt_id: str,
version: str,
model: str,
variables: dict
):
"""Execute prompt with Prometheus monitoring"""
start_time = time.time()
status = 'success'
try:
# Execute
result = await execute_prompt(prompt_id, version, model, variables)
# Record cache hit
if result.get('cache_hit'):
prompt_cache_hits_total.labels(prompt_id=prompt_id).inc()
# Record cost
prompt_cost_usd.labels(
prompt_id=prompt_id,
model=result['model_used']
).observe(result['cost'])
return result
except Exception as e:
status = 'error'
raise
finally:
# Record latency
latency = time.time() - start_time
prompt_latency_seconds.labels(
prompt_id=prompt_id,
model=model
).observe(latency)
# Record execution
prompt_executions_total.labels(
prompt_id=prompt_id,
version=version,
model=model,
status=status
).inc()
# Expose metrics endpoint
from prometheus_client import generate_latest, CONTENT_TYPE_LATEST
@app.get("/metrics")
async def metrics():
"""Prometheus metrics endpoint"""
return Response(
content=generate_latest(),
media_type=CONTENT_TYPE_LATEST
)
Alertes (Prometheus Rules)
# prometheus/alerts.yml
groups:
- name: prompts
interval: 30s
rules:
- alert: HighPromptErrorRate
expr: |
(
rate(prompt_executions_total{status="error"}[5m])
/
rate(prompt_executions_total[5m])
) > 0.05
for: 5m
labels:
severity: warning
annotations:
summary: "High error rate for prompt {{ $labels.prompt_id }}"
description: "Error rate is {{ $value | humanizePercentage }} (threshold: 5%)"
- alert: HighPromptLatency
expr: |
histogram_quantile(0.95,
rate(prompt_latency_seconds_bucket[5m])
) > 5
for: 5m
labels:
severity: warning
annotations:
summary: "High P95 latency for {{ $labels.prompt_id }}"
description: "P95 latency is {{ $value }}s (threshold: 5s)"
- alert: PromptCostSpike
expr: |
rate(prompt_cost_usd_sum[1h]) > 100
for: 30m
labels:
severity: critical
annotations:
summary: "High cost rate detected"
description: "Spending ${{ $value }}/hour (threshold: $100/h)"
- alert: LowCacheHitRate
expr: |
(
rate(prompt_cache_hits_total[15m])
/
rate(prompt_executions_total[15m])
) < 0.2
for: 15m
labels:
severity: info
annotations:
summary: "Low cache hit rate"
description: "Cache hit rate is {{ $value | humanizePercentage }} (target: >20%)"
Best Practices Production
Graceful Degradation (Fallbacks)
async def execute_with_fallback(
prompt: str,
models: List[str] = ["gpt-4-turbo", "gpt-3.5-turbo", "claude-3-haiku"],
timeout: int = 10
) -> Dict:
"""
Try multiple models until success.
Args:
prompt: Formatted prompt
models: List of models to try (order of preference)
timeout: Timeout per model (seconds)
Returns:
Result dict
"""
last_error = None
for i, model in enumerate(models):
try:
logger.info(f"Trying model {model} (attempt {i+1}/{len(models)})")
result = await call_llm(
model=model,
prompt=prompt,
timeout=timeout
)
logger.info(f"Success with model {model}")
return result
except TimeoutError as e:
logger.warning(f"Model {model} timeout ({timeout}s)")
last_error = e
continue
except RateLimitError as e:
logger.warning(f"Model {model} rate limited")
last_error = e
continue
except Exception as e:
logger.error(f"Model {model} failed: {e}")
last_error = e
continue
# All models failed
raise Exception(
f"All {len(models)} models failed. Last error: {last_error}"
)
Rate Limiting
from slowapi import Limiter, _rate_limit_exceeded_handler
from slowapi.util import get_remote_address
from slowapi.errors import RateLimitExceeded
limiter = Limiter(key_func=get_remote_address)
app.state.limiter = limiter
app.add_exception_handler(RateLimitExceeded, _rate_limit_exceeded_handler)
@app.post("/v1/prompt/execute")
@limiter.limit("100/minute") # 100 requests per minute per IP
async def execute_prompt(
request: Request,
prompt_request: PromptRequest
):
...
# Rate limit différencié par tier
@limiter.limit("1000/hour", key_func=lambda: get_user_tier())
async def execute_prompt_premium(...):
...
Caching Intelligent (Redis)
import redis
import hashlib
import json
from typing import Optional
redis_client = redis.Redis(
host='localhost',
port=6379,
db=0,
decode_responses=True
)
def get_cache_key(prompt: str, model: str) -> str:
"""Generate deterministic cache key"""
content = f"{model}:{prompt}"
return hashlib.sha256(content.encode()).hexdigest()
async def cached_llm_call(
prompt: str,
model: str,
ttl: int = 3600 # 1 hour
) -> Dict:
"""
Call LLM with caching.
Args:
prompt: Formatted prompt
model: Model name
ttl: Time to live in seconds
Returns:
Result dict with 'cache_hit' boolean
"""
cache_key = get_cache_key(prompt, model)
# Check cache
cached = redis_client.get(cache_key)
if cached:
logger.info(f"Cache HIT for {cache_key[:8]}...")
result = json.loads(cached)
result['cache_hit'] = True
return result
logger.info(f"Cache MISS for {cache_key[:8]}...")
# Call LLM
result = await call_llm(model, prompt)
result['cache_hit'] = False
# Store in cache
redis_client.setex(
cache_key,
ttl,
json.dumps(result)
)
return result
Circuit Breaker
from circuitbreaker import circuit
@circuit(failure_threshold=5, recovery_timeout=60, expected_exception=Exception)
async def call_llm_with_circuit_breaker(model: str, prompt: str):
"""
Call LLM with circuit breaker pattern.
- If 5 consecutive failures → circuit opens for 60s
- During open state → immediately raise CircuitBreakerError
- After 60s → try again (half-open state)
"""
return await call_llm(model, prompt)
# Usage
try:
result = await call_llm_with_circuit_breaker("gpt-4-turbo", prompt)
except CircuitBreakerError:
# Circuit is open → use fallback
result = await call_llm("gpt-3.5-turbo", prompt)
6Documentation et Handoff
Template Documentation
Chaque prompt doit avoir sa documentation :
# Prompt: Summarization v1.2.0
## Description {#description}
Summarizes articles concisely (20-500 words) while preserving key information.
Optimized for news articles, blog posts, and research papers.
## Use Cases {#use-cases}
- Blog post summaries for social media
- Newsletter digest generation
- Research paper abstracts
- Content curation
## Parameters {#parameters}
### Required
- `article_text` (string): Full text of the article to summarize
### Optional
- `max_words` (integer, default=100): Maximum summary length
- Min: 20, Max: 500
- `tone` (string, default=null): Desired tone
- Options: "formal", "casual", "technical"
## Example Usage {#example-usage}
\`\`\`python
from prompt_manager import PromptManager
pm = PromptManager()
prompt = pm.get("summarization", version="1.2.0")
result = prompt.format(
article_text="Long article about AI...",
max_words=75,
tone="technical"
)
output = llm.execute(result, model="gpt-4-turbo")
\`\`\`
## Performance (tested on 500 articles) {#performance-tested-on-500-articles}
- **Quality Score**: 0.82 (semantic similarity vs human summaries)
- **Average Latency**: 1200ms (GPT-4 Turbo)
- **Average Cost**: $0.015
- **Cache Hit Rate**: 35%
## Recommended Models {#recommended-models}
1. **GPT-4 Turbo** (best quality)
2. **GPT-3.5 Turbo** (good quality, 5x cheaper)
3. **Claude 3 Haiku** (fastest, cheapest)
## Known Limitations {#known-limitations}
- May struggle with highly technical jargon (medical, legal)
- Optimal for articles 500-5000 words
- Not suitable for poetry or creative writing
- Occasional repetition for very short articles (<200 words)
## Changelog {#changelog}
- **v1.0.0** (2025-01-01): Initial release
- **v1.1.0** (2025-01-10): Improved instructions clarity (+8% quality)
- **v1.2.0** (2025-01-15): Added few-shot examples (+12% quality)
## Maintenance {#maintenance}
- **Owner**: Data Science Team
- **Reviewers**: [email protected], [email protected]
- **Next Review**: 2025-04-01
Checklist Production-Ready
Avant le déploiement
- Architecture : Multi-layer (API→Manager→Gateway→LLM)
- Versioning : Prompts externalisés (YAML), semantic versioning
- Tests : Automatisés (pytest), >80% coverage
- CI/CD : GitHub Actions avec lint + test + deploy
- Monitoring : Prometheus + Grafana + alertes
- Sécurité : API keys, rate limiting, input validation
- Performance : Caching (Redis), fallbacks, circuit breakers
- Documentation : README par prompt, runbooks, architecture diagram
Opérations continues
- Monitoring quotidien : Dashboard Grafana, check alertes
- Review hebdomadaire : Coûts, latence, erreurs
- Review mensuelle : Qualité (A/B tests), optimisations
- Updates trimestriels : Nouveaux modèles, best practices
Points Clés à Retenir
Architecture en couches : Séparation API / Prompt Manager / LLM Gateway
Versioning sémantique : YAML externalisés, changelog, tests automatisés
CI/CD automatisé : Lint → Test → Cost estimate → Deploy → Monitor
Observability complète : Prometheus metrics + alertes + dashboards
Resilience : Graceful degradation, fallbacks, circuit breakers, caching
Documentation : Chaque prompt documenté, runbooks, architecture visible
Conclusion de la Série
Vous avez maintenant tous les outils pour maîtriser le Prompt Engineering :
- Fondamentaux : Zero-Shot, Few-Shot, Chain-of-Thought
- Techniques avancées : ToT, ReAct, Self-Consistency, Constitutional AI
- Cas d’usage : Templates prêts pour copywriting, code, data, support
- Outils : LangChain, marketplaces, versioning, testing, optimisation auto
- Sécurité : Prompt injection, jailbreaking, guardrails, PII protection
- Performance : Métriques, A/B testing, optimisation coûts (-60%), latence
- Production : Architecture, CI/CD, monitoring, best practices
Prochaine étape : Appliquer ces techniques à vos projets, mesurer les résultats, itérer et partager vos learnings !
Retour : Mesurer et Optimiser Performance (KPIs, A/B Testing, Coûts) Index de la série : Prompt Engineering : Guide Complet 2025