Implémenter un système RAG avec LangChain : Guide complet du prototype à la production
Le RAG (Retrieval-Augmented Generation) est devenu la technique incontournable pour créer des systèmes d’IA capables de répondre avec précision à partir de vos propres données. Dans cet article, nous allons construire ensemble un système RAG complet avec LangChain, en couvrant tous les aspects depuis le prototype jusqu’aux optimisations pour la production. Que vous développiez un chatbot documentaire, un assistant de support client, ou un outil de recherche intelligent, ce guide vous donnera toutes les clés.
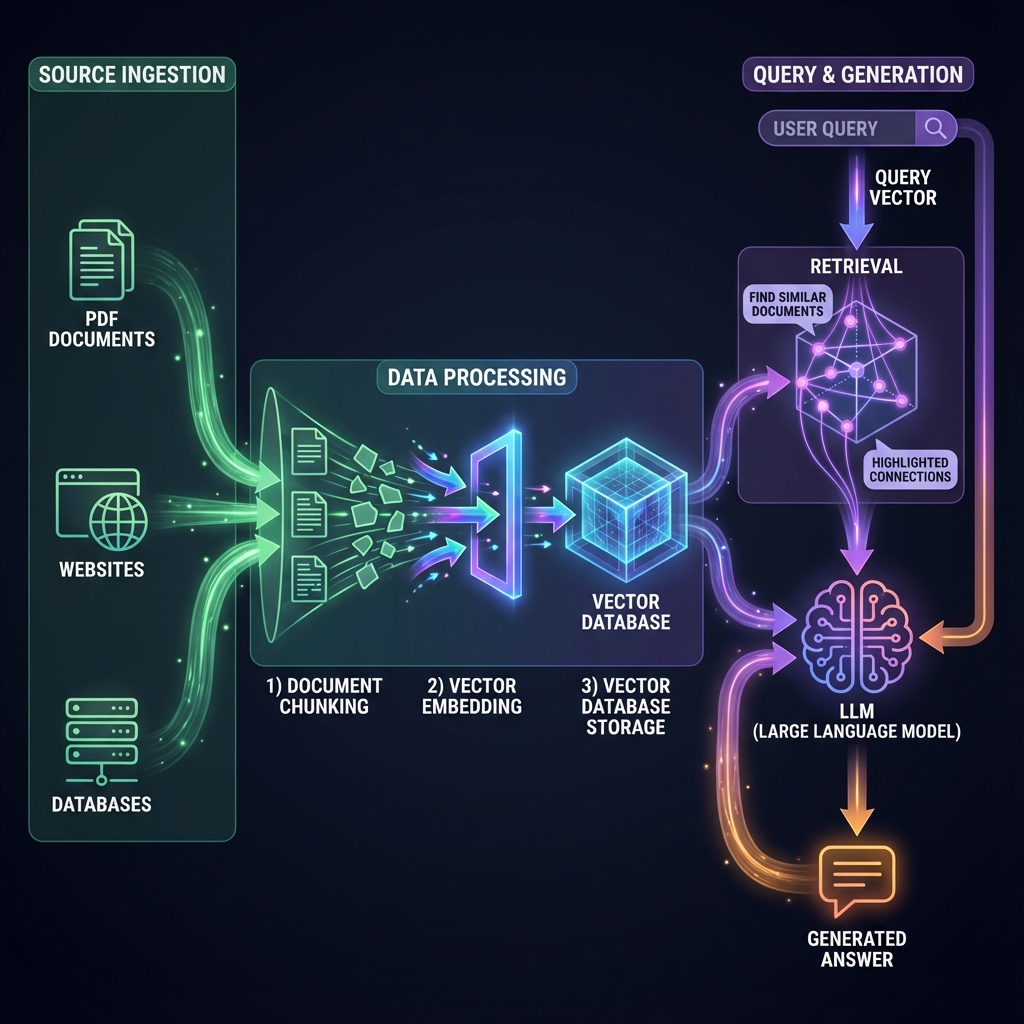
Rappel : Qu’est-ce que le RAG ?
Le RAG combine deux étapes :
- Retrieval (Récupération) : Rechercher les informations pertinentes dans une base de connaissances
- Generation (Génération) : Utiliser ces informations pour générer une réponse précise avec un LLM
Avantages :
- Réponses basées sur vos données actualisées (pas seulement les connaissances du modèle)
- Réduction des hallucinations
- Traçabilité (sources citées)
- Pas besoin de réentraîner le modèle
Pour plus de détails sur le concept, consultez notre article sur le RAG.
Architecture d’un système RAG avec LangChain
Voici les composants d’un pipeline RAG typique :
Documents sources
↓
Document Loaders (chargement)
↓
Text Splitters (découpage)
↓
Embeddings (vectorisation)
↓
Vector Store (stockage)
↓
Retriever (recherche)
↓
LLM + Prompt (génération)
↓
Réponse finale
Nous allons implémenter chaque étape progressivement.
Étape 1 : Chargement des documents
LangChain propose des loaders pour tous types de sources :
Documents PDF
from langchain_community.document_loaders import PyPDFLoader
# Chargement d'un PDF
loader = PyPDFLoader("documentation.pdf")
documents = loader.load()
# Chaque document contient page_content et metadata
print(f"Nombre de pages : {len(documents)}")
print(f"Contenu première page : {documents[0].page_content[:200]}")
print(f"Métadonnées : {documents[0].metadata}")
Sites web
from langchain_community.document_loaders import WebBaseLoader
# Chargement d'une ou plusieurs pages
loader = WebBaseLoader([
"https://naileru.com/ia/rag/",
"https://naileru.com/ia/embedding/"
])
documents = loader.load()
Fichiers texte et Markdown
from langchain_community.document_loaders import TextLoader, UnstructuredMarkdownLoader
# Texte brut
text_loader = TextLoader("notes.txt", encoding="utf-8")
# Markdown avec structure préservée
md_loader = UnstructuredMarkdownLoader("readme.md")
documents = text_loader.load() + md_loader.load()
Bases de données et APIs
# Notion
from langchain_community.document_loaders import NotionDirectoryLoader
loader = NotionDirectoryLoader("./notion_export")
# Google Drive
from langchain_community.document_loaders import GoogleDriveLoader
loader = GoogleDriveLoader(folder_id="your_folder_id")
# Confluence
from langchain_community.document_loaders import ConfluenceLoader
loader = ConfluenceLoader(url="https://your-domain.atlassian.net")
Chargement de répertoires entiers
from langchain_community.document_loaders import DirectoryLoader
# Tous les fichiers .txt d'un dossier
loader = DirectoryLoader(
"./docs",
glob="**/*.txt",
show_progress=True
)
documents = loader.load()
Étape 2 : Découpage intelligent des documents
Les documents sont souvent trop longs pour être traités en une fois. Le découpage est crucial pour la qualité du RAG.
Splitter basique par caractères
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # Taille des chunks en caractères
chunk_overlap=200, # Chevauchement pour conserver le contexte
length_function=len,
separators=["\n\n", "\n", " ", ""] # Ordre de priorité des séparateurs
)
splits = text_splitter.split_documents(documents)
print(f"Documents originaux : {len(documents)}")
print(f"Chunks créés : {len(splits)}")
Conseil : chunk_overlap est essentiel pour éviter de couper des informations au milieu.
Taille de chunk optimale : 500-1000 caractères avec 100-200 de chevauchement fonctionne pour 80% des cas. Trop petit (< 300) = perte de contexte. Trop grand (> 2000) = bruit et coûts élevés. Testez avec vos données !
Splitter optimisé par tokens
Pour éviter de dépasser les limites des modèles d’embedding :
from langchain.text_splitter import TokenTextSplitter
# Découpage basé sur les tokens réels du modèle
token_splitter = TokenTextSplitter(
chunk_size=500, # En tokens
chunk_overlap=50
)
splits = token_splitter.split_documents(documents)
Pour plus de détails sur les tokens, voir notre article sur les tokens.
Splitter spécialisés
# Pour le code Python
from langchain.text_splitter import PythonCodeTextSplitter
python_splitter = PythonCodeTextSplitter(chunk_size=500)
# Pour le Markdown (respecte les titres)
from langchain.text_splitter import MarkdownHeaderTextSplitter
md_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=[
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
)
# Pour HTML (respecte les balises)
from langchain.text_splitter import HTMLHeaderTextSplitter
html_splitter = HTMLHeaderTextSplitter(
headers_to_split_on=[("h1", "Header 1"), ("h2", "Header 2")]
)
Recommandations de tailles
| Type de contenu | chunk_size | chunk_overlap | Justification |
|---|---|---|---|
| Documentation technique | 500-1000 | 100-200 | Garder le contexte des procédures |
| Articles de blog | 1000-1500 | 150-300 | Paragraphes complets |
| Code source | 300-500 | 50-100 | Fonctions entières |
| FAQ/Q&A | 200-400 | 0-50 | Questions indépendantes |
| Données structurées | 100-300 | 0 | Entrées individuelles |
Étape 3 : Création des embeddings
Les embeddings transforment le texte en vecteurs numériques pour la recherche sémantique. Voir notre guide sur les embeddings.
OpenAI Embeddings
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-3-large", # Meilleur modèle
dimensions=1536 # Dimension des vecteurs
)
# Test
vector = embeddings.embed_query("Qu'est-ce que le RAG ?")
print(f"Dimension du vecteur : {len(vector)}") # 1536
Coût : ~0.13$/1M tokens (text-embedding-3-large)
Coûts embeddings : Embedder 1M de mots (1.3M tokens) coûte ~0.17$. Pour 100 000 documents : ~17$. Les embeddings sont un coût unique (sauf re-indexation). Le vrai coût est la génération : GPT-4 à ~15$/1M tokens output.
Embeddings open source (gratuits)
from langchain_community.embeddings import HuggingFaceEmbeddings
# Modèle français optimisé
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
model_kwargs={'device': 'cpu'}, # ou 'cuda' si GPU
encode_kwargs={'normalize_embeddings': True}
)
Avantage : Gratuit, fonctionne offline Inconvénient : Qualité légèrement inférieure à OpenAI
Comparaison des modèles d’embeddings
| Modèle | Dimensions | Performance | Coût | Meilleur pour |
|---|---|---|---|---|
| OpenAI text-embedding-3-large | 1536/3072 | ⭐⭐⭐⭐⭐ | 0.13$/M tokens | Production, multilingue |
| OpenAI text-embedding-3-small | 512/1536 | ⭐⭐⭐⭐ | 0.02$/M tokens | Budget limité |
| Cohere embed-v3 | 1024 | ⭐⭐⭐⭐⭐ | 0.10$/M tokens | Recherche sémantique |
| HuggingFace MiniLM | 384 | ⭐⭐⭐ | Gratuit | Développement local |
| Voyage AI | 1024 | ⭐⭐⭐⭐ | 0.10$/M tokens | Spécialisé retrieval |
Étape 4 : Stockage dans une base vectorielle
Les bases vectorielles permettent la recherche rapide par similarité. Pour plus de détails, voir vecteurs.
FAISS (local, gratuit)
from langchain_community.vectorstores import FAISS
# Création de la base
vectorstore = FAISS.from_documents(
documents=splits,
embedding=embeddings
)
# Sauvegarde locale
vectorstore.save_local("./faiss_index")
# Rechargement
vectorstore = FAISS.load_local(
"./faiss_index",
embeddings,
allow_dangerous_deserialization=True # Nécessaire pour FAISS
)
Avantages : Gratuit, rapide, fonctionne offline
Limites : Pas de persistance automatique, pas de filtrage avancé
Chroma (local avec persistance)
from langchain_community.vectorstores import Chroma
# Création avec persistance
vectorstore = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory="./chroma_db"
)
# Auto-sauvegardé, rechargement automatique
vectorstore = Chroma(
persist_directory="./chroma_db",
embedding_function=embeddings
)
Avantages : Persistance automatique, métadonnées, filtres
Limites : Légèrement plus lent que FAISS
Pinecone (cloud, production)
from langchain_community.vectorstores import Pinecone
import pinecone
# Configuration
pinecone.init(api_key="your-api-key", environment="us-west1-gcp")
# Création de l'index
index_name = "rag-knowledge-base"
if index_name not in pinecone.list_indexes():
pinecone.create_index(
name=index_name,
dimension=1536,
metric="cosine"
)
# Indexation
vectorstore = Pinecone.from_documents(
splits,
embeddings,
index_name=index_name
)
Avantages : Scalable, performant, métadonnées avancées
Coût : Plan gratuit (1M vecteurs), puis payant
Comparaison des bases vectorielles
| Base | Type | Performance | Scalabilité | Filtres | Coût | Meilleur pour |
|---|---|---|---|---|---|---|
| FAISS | Local | ⭐⭐⭐⭐⭐ | ⭐⭐ | ❌ | Gratuit | Prototypes, dev local |
| Chroma | Local | ⭐⭐⭐⭐ | ⭐⭐⭐ | ✅ | Gratuit | Apps moyennes |
| Pinecone | Cloud | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ | Freemium | Production |
| Weaviate | Cloud/Self | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ | Freemium | Multimodal |
| Qdrant | Cloud/Self | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ✅ | Freemium | Haute performance |
Étape 5 : Configuration du retriever
Le retriever définit comment chercher dans la base vectorielle.
Retriever de base (similarité)
# K documents les plus similaires
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 4} # Retourne 4 documents
)
# Test de recherche
docs = retriever.get_relevant_documents("Comment fonctionne le RAG ?")
for i, doc in enumerate(docs):
print(f"\n--- Document {i+1} ---")
print(doc.page_content[:200])
print(f"Score: {doc.metadata.get('score', 'N/A')}")
Retriever avec seuil de similarité
Pour filtrer les résultats non pertinents :
retriever = vectorstore.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={
"k": 10, # Chercher dans 10 candidats
"score_threshold": 0.7 # Garder seulement ceux > 0.7
}
)
Retriever MMR (diversité)
Pour éviter de récupérer des documents trop similaires entre eux :
retriever = vectorstore.as_retriever(
search_type="mmr", # Maximum Marginal Relevance
search_kwargs={
"k": 4,
"fetch_k": 20, # Chercher dans 20 candidats
"lambda_mult": 0.5 # 0=diversité max, 1=similarité max
}
)
Cas d’usage : Documentation avec beaucoup de pages similaires.
Retriever avec filtres de métadonnées
# Recherche uniquement dans des sources spécifiques
retriever = vectorstore.as_retriever(
search_kwargs={
"k": 4,
"filter": {
"source": "documentation.pdf",
"page": {"$gte": 10, "$lte": 50} # Pages 10-50
}
}
)
Compression du contexte
Pour réduire le bruit et les coûts :
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain_openai import ChatOpenAI
# Compresseur intelligent
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
# Retriever avec compression
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=retriever
)
# Les documents retournés sont automatiquement condensés
docs = compression_retriever.get_relevant_documents(
"Quelle est la différence entre LoRA et QLoRA ?"
)
Avantage : Contexte 50-70% plus court, réponses plus précises.
Étape 6 : Création de la chaîne RAG
Maintenant assemblons tout dans une chaîne complète.
RAG simple
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
# 1. LLM
llm = ChatOpenAI(model="gpt-4", temperature=0)
# 2. Prompt pour le RAG
prompt = ChatPromptTemplate.from_template("""
Réponds à la question en te basant sur le contexte suivant.
Si tu ne trouves pas la réponse dans le contexte, dis "Je ne trouve pas cette information dans les documents fournis".
Cite toujours tes sources en mentionnant le document d'origine.
Contexte:
{context}
Question: {input}
Réponse:""")
# 3. Chaîne de combinaison de documents
document_chain = create_stuff_documents_chain(llm, prompt)
# 4. Chaîne RAG complète
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# 5. Utilisation
response = retrieval_chain.invoke({
"input": "Qu'est-ce que le fine-tuning ?"
})
print(response["answer"])
print("\n--- Sources ---")
for doc in response["context"]:
print(f"- {doc.metadata}")
RAG conversationnel (avec historique)
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage
# Prompt pour reformuler la question avec historique
contextualize_q_prompt = ChatPromptTemplate.from_messages([
("system", """Reformule la dernière question de l'utilisateur en une question autonome,
en prenant en compte l'historique de la conversation."""),
MessagesPlaceholder("chat_history"),
("human", "{input}")
])
# Retriever conscient de l'historique
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
# Chaîne RAG avec historique
qa_prompt = ChatPromptTemplate.from_messages([
("system", "Réponds en te basant sur le contexte:\n\n{context}"),
MessagesPlaceholder("chat_history"),
("human", "{input}")
])
document_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, document_chain)
# Conversation
chat_history = []
# Tour 1
response1 = rag_chain.invoke({
"input": "Qu'est-ce que LoRA ?",
"chat_history": chat_history
})
print(response1["answer"])
# Mise à jour de l'historique
chat_history.extend([
HumanMessage(content="Qu'est-ce que LoRA ?"),
AIMessage(content=response1["answer"])
])
# Tour 2 (utilise le contexte)
response2 = rag_chain.invoke({
"input": "Quels sont ses avantages ?", # "ses" fait référence à LoRA
"chat_history": chat_history
})
print(response2["answer"])
Étape 7 : Optimisations avancées
Hybrid Search (mots-clés + sémantique)
from langchain.retrievers import EnsembleRetriever
from langchain_community.retrievers import BM25Retriever
# Retriever par mots-clés (BM25)
bm25_retriever = BM25Retriever.from_documents(splits)
bm25_retriever.k = 4
# Retriever sémantique
semantic_retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
# Combinaison hybride
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, semantic_retriever],
weights=[0.3, 0.7] # 30% mots-clés, 70% sémantique
)
# Meilleure précision, surtout pour les termes techniques exacts
docs = ensemble_retriever.get_relevant_documents("API REST authentication")
Multi-Query Retriever
Génère plusieurs variantes de la question pour une meilleure couverture :
from langchain.retrievers.multi_query import MultiQueryRetriever
multi_query_retriever = MultiQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=ChatOpenAI(model="gpt-4o-mini", temperature=0)
)
# Génère automatiquement 3-5 variantes de la question
docs = multi_query_retriever.get_relevant_documents(
"Comment personnaliser un modèle d'IA ?"
)
# → Génère : "fine-tuning", "adapter un LLM", "entraînement personnalisé", etc.
Parent Document Retriever
Recherche sur des petits chunks mais retourne les documents parents complets :
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
# Store pour les documents parents
store = InMemoryStore()
# Splitter pour petits chunks (recherche)
child_splitter = RecursiveCharacterTextSplitter(chunk_size=200)
# Splitter pour parents (contexte)
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=1000)
# Retriever intelligent
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter
)
retriever.add_documents(documents)
# Recherche précise, contexte complet
docs = retriever.get_relevant_documents("authentication JWT")
Self-Query Retriever
Extrait automatiquement les métadonnées de la question :
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
# Description des métadonnées disponibles
metadata_field_info = [
AttributeInfo(
name="source",
description="Le fichier source du document",
type="string"
),
AttributeInfo(
name="page",
description="Le numéro de page",
type="integer"
),
]
document_content_description = "Documentation technique sur l'IA"
# Retriever auto-filtrant
retriever = SelfQueryRetriever.from_llm(
llm=ChatOpenAI(model="gpt-4o-mini", temperature=0),
vectorstore=vectorstore,
document_contents=document_content_description,
metadata_field_info=metadata_field_info
)
# Question avec filtre implicite
docs = retriever.get_relevant_documents(
"Parle-moi du fine-tuning dans le fichier documentation.pdf"
)
# → Ajoute automatiquement le filtre source="documentation.pdf"
Patterns de production
Indexation asynchrone
import asyncio
from langchain.vectorstores import Chroma
async def index_documents_batch(documents, batch_size=100):
"""Indexation par batches pour gérer de gros volumes"""
for i in range(0, len(documents), batch_size):
batch = documents[i:i+batch_size]
await vectorstore.aadd_documents(batch)
print(f"Indexé {i+batch_size}/{len(documents)} documents")
# Utilisation
await index_documents_batch(splits, batch_size=50)
Cache de recherche
from langchain.cache import InMemoryCache
from langchain.globals import set_llm_cache
# Cache les réponses identiques
set_llm_cache(InMemoryCache())
# Première fois : appel API
response1 = rag_chain.invoke({"input": "Qu'est-ce que le RAG ?"})
# Deuxième fois : récupération du cache (instantané)
response2 = rag_chain.invoke({"input": "Qu'est-ce que le RAG ?"})
Fallback sur plusieurs LLMs
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
# LLM principal
primary_llm = ChatOpenAI(model="gpt-4", timeout=10)
# LLM de secours
fallback_llm = ChatAnthropic(model="claude-sonnet-4.5")
# Chaîne avec fallback automatique
llm = primary_llm.with_fallbacks([fallback_llm])
# Si GPT-4 échoue ou timeout, utilise Claude
rag_chain = create_retrieval_chain(retriever, llm)
Monitoring avec callbacks
from langchain.callbacks import StdOutCallbackHandler
class CustomCallback(StdOutCallbackHandler):
def on_retriever_end(self, documents, **kwargs):
print(f"\n✓ Retriever: {len(documents)} documents trouvés")
def on_llm_start(self, serialized, prompts, **kwargs):
print(f"\n✓ LLM: Génération en cours...")
def on_llm_end(self, response, **kwargs):
tokens = response.llm_output.get('token_usage', {})
print(f"✓ LLM: {tokens.get('total_tokens', 0)} tokens utilisés")
# Utilisation
response = rag_chain.invoke(
{"input": "Qu'est-ce que le fine-tuning ?"},
config={"callbacks": [CustomCallback()]}
)
Problèmes courants et solutions
Réponses hors sujet
Cause : Documents non pertinents récupérés
Solutions :
# Solution 1 : Augmenter le seuil de similarité
retriever = vectorstore.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": 0.8} # Plus strict
)
# Solution 2 : Améliorer le prompt
prompt = ChatPromptTemplate.from_template("""
Réponds UNIQUEMENT si tu trouves l'information dans le contexte.
Si le contexte ne contient pas la réponse, réponds exactement :
"Je ne trouve pas cette information dans les documents."
Contexte: {context}
Question: {input}
""")
Contexte trop long (dépassement de tokens)
Solutions :
# Solution 1 : Réduire k
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# Solution 2 : Chunks plus petits
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # Au lieu de 1000
chunk_overlap=50
)
# Solution 3 : Compression
from langchain.retrievers import ContextualCompressionRetriever
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=retriever
)
Résultats incohérents
Cause : Chunks mal découpés
Solutions :
# Solution 1 : Splitter sémantique
from langchain.text_splitter import SpacyTextSplitter
splitter = SpacyTextSplitter(chunk_size=1000)
# Solution 2 : Overlap plus important
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=300 # 30% de recouvrement
)
# Solution 3 : Parent Document Retriever (voir plus haut)
Performance lente
Solutions :
# Solution 1 : Base vectorielle plus rapide
vectorstore = FAISS.from_documents(splits, embeddings) # Plus rapide que Chroma
# Solution 2 : Embeddings plus légers
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# Solution 3 : Réduire k
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# Solution 4 : LLM plus rapide pour la génération
llm = ChatOpenAI(model="gpt-4o-mini") # Au lieu de gpt-4
Évaluation de la qualité du RAG
Métriques clés
from langchain.evaluation import load_evaluator
# 1. Pertinence du retrieval
retrieval_evaluator = load_evaluator("criteria", criteria="relevance")
# 2. Qualité de la réponse
qa_evaluator = load_evaluator("qa")
# 3. Cohérence avec les sources
coherence_evaluator = load_evaluator("criteria", criteria="coherence")
Dataset de test
test_cases = [
{
"question": "Qu'est-ce que LoRA ?",
"expected_answer": "LoRA est une technique de fine-tuning...",
"expected_source": "fine-tuning.md"
},
# ... plus de cas
]
# Évaluation automatique
for case in test_cases:
result = rag_chain.invoke({"input": case["question"]})
score = qa_evaluator.evaluate_strings(
prediction=result["answer"],
reference=case["expected_answer"]
)
print(f"Question: {case['question']}")
print(f"Score: {score['score']}")
Coûts et optimisation
Estimation des coûts
Pour 10 000 documents (5M tokens) :
| Composant | Service | Coût initial | Coût mensuel | Notes |
|---|---|---|---|---|
| Embeddings | OpenAI (large) | 0.65$ | 0$ | Une fois |
| Embeddings | HuggingFace | 0$ | 0$ | Gratuit |
| Vector DB | FAISS | 0$ | 0$ | Local |
| Vector DB | Pinecone | 0$ | 0-70$ | Freemium |
| LLM (génération) | GPT-4 | - | 30-150$ | Variable |
| LLM (génération) | GPT-4o-mini | - | 3-15$ | 90% moins cher |
Recommandations :
- Dev : HuggingFace + FAISS + GPT-4o-mini = ~0$
- Production PME : OpenAI embeddings + Chroma + GPT-4o = ~50$/mois
- Production grande échelle : OpenAI embeddings + Pinecone + GPT-4 = 500-2000$/mois
Optimisation des coûts
# 1. Cache les embeddings pour éviter la recomputation
from langchain.embeddings import CacheBackedEmbeddings
from langchain.storage import LocalFileStore
store = LocalFileStore("./embedding_cache")
cached_embeddings = CacheBackedEmbeddings.from_bytes_store(
embeddings, store, namespace="openai-embeddings"
)
# 2. Utiliser un LLM moins cher pour les tâches simples
cheap_llm = ChatOpenAI(model="gpt-4o-mini") # 60x moins cher que GPT-4
expensive_llm = ChatOpenAI(model="gpt-4")
# Routing intelligent
def get_llm(question):
if len(question) < 50 and "?" in question:
return cheap_llm
return expensive_llm
# 3. Limiter le contexte envoyé au LLM
retriever = vectorstore.as_retriever(search_kwargs={"k": 2}) # Au lieu de 5
Conclusion
Implémenter un système RAG avec LangChain est devenu accessible grâce aux abstractions puissantes du framework. En suivant ce guide, vous avez appris à :
✅ Charger divers types de documents (PDF, web, bases de données)
✅ Découper intelligemment avec les bons splitters
✅ Vectoriser avec les meilleurs modèles d’embeddings
✅ Stocker dans des bases vectorielles adaptées à votre échelle
✅ Rechercher avec des retrievers optimisés (MMR, hybrid search, compression)
✅ Générer des réponses précises avec des prompts structurés
✅ Optimiser pour la production (async, caching, monitoring)
Checklist de lancement
Avant de déployer votre RAG en production :
- Qualité des données : Documents nettoyés et à jour
- Taille des chunks : Testée et optimisée pour votre cas
- Embeddings : Modèle choisi selon budget et langue
- Base vectorielle : Scalable et persistante
- Retriever : Testé avec seuils et diversité
- Prompt : Inclut gestion des cas “pas de réponse”
- Évaluation : Dataset de test avec métriques
- Monitoring : Callbacks et logs activés
- Coûts : Estimation mensuelle validée
- Sécurité : Pas de données sensibles exposées
Prochaines étapes
Pour aller encore plus loin :
- Agents RAG : Combiner RAG et agents pour des systèmes autonomes
- RAG multimodal : Ajouter images et vidéos
- Fine-tuning : Personnaliser l’embedder ou le LLM pour votre domaine
- Graph RAG : Utiliser des bases de graphes (Neo4j) pour des relations complexes
Pour aller plus loin :
- Maîtrisez les bases avec notre introduction à LangChain
- Comprenez le concept derrière le RAG
- Découvrez les embeddings en profondeur
- Explorez les vecteurs et la similarité cosinus
- Apprenez le fine-tuning pour personnaliser vos modèles
- Comparez les frameworks open source pour l’exécution locale
- Assurez la sécurité et l’éthique de votre système
- Choisissez les bons modèles et acteurs
- Optimisez vos tokens pour réduire les coûts
- Comprenez l’architecture des Transformers
Navigation
← Retour à la Formation LangChain | Module suivant : Agents et Outils Autonomes →