Hardware inférence IA : De l'edge au cloud
L’inférence (inference) est l’utilisation d’un modèle déjà entraîné pour faire des prédictions sur de nouvelles données. C’est la phase de production : un utilisateur pose une question à ChatGPT, Stable Diffusion génère une image, un système de recommandation suggère des produits.
Pour comprendre les différences avec le fine-tuning des modèles, consultez notre guide dédié.
Différences avec l’entraînement :
| Critère | Entraînement | Inférence |
|---|---|---|
| Fréquence | Rare (heures/jours/semaines) | Continu (millions de requêtes/jour) |
| Latence | Acceptable (batch processing) | Critique (< 100ms souvent requis) |
| Throughput | Moyen (quelques samples/s) | Élevé (milliers de requêtes/s) |
| VRAM | Très élevée (modèle + gradients + optimizer) | Moyenne (modèle seul) |
| Précision | FP32, BF16 | INT8, INT4 souvent suffisant |
| Coûts | CapEx (one-time investment) | OpEx (coût par requête, continu) |
Objectif de cet article : Vous aider à choisir le hardware optimal pour l’inférence selon votre cas d’usage (datacenter, edge, mobile) et à optimiser les performances et coûts.
Métriques d’Inférence
Latence
Définition : Temps entre la requête et la réponse complète.
Composantes :
Latence totale = Latence réseau + Latence modèle + Overhead système
Latence modèle = Prefill time + Decode time
- Prefill : Traitement du prompt (parallélisable)
- Decode : Génération token par token (séquentiel)
Cibles selon use case :
| Application | Latence cible | Exemples |
|---|---|---|
| Chatbot temps réel | < 100ms (TTFT) | ChatGPT, Claude |
| Recherche sémantique | < 50ms | Embeddings, RAG retrieval |
| Génération image | 1-5s | Stable Diffusion, DALL-E |
| Transcription audio | Temps réel (1x) | Whisper streaming |
| Traduction | < 500ms | Google Translate |
| Vision (détection) | < 30ms (30 FPS) | Véhicules autonomes, surveillance |
TTFT critique : Le Time To First Token < 200ms est essentiel pour l’expérience utilisateur des chatbots. Les utilisateurs perçoivent toute latence > 300ms comme lente.
TTFT (Time To First Token) : Métrique clé pour LLM
- Temps avant le premier token généré
- Critique pour l’expérience utilisateur (perception de réactivité)
- Cible : < 200ms pour chatbots
Throughput
Définition : Nombre de requêtes traitées par unité de temps.
Métriques :
- QPS (Queries Per Second) : Requêtes/seconde
- TPS (Tokens Per Second) : Tokens générés/seconde (LLM)
- IPS (Images Per Second) : Images générées/seconde
Trade-off latence/throughput :
- Batch size = 1 : Latence minimale, throughput faible
- Batch size élevé : Latence augmente, throughput max
Exemple : LLaMA 7B sur A100
- Batch 1 : 50 tokens/s, latence 20ms
- Batch 64 : 2 000 tokens/s, latence 640ms
Coût par Inférence
Définition : Coût pour traiter une requête.
Calcul :
Coût par inférence = (Coût GPU/h ÷ 3600) × Latence(s)
ou
Coût par 1M tokens = (Coût GPU/h ÷ Throughput tokens/h) × 1M
Exemple : A100 (2€/h), throughput 100k tokens/h
Coût par 1M tokens = (2€ ÷ 100 000) × 1 000 000 = 20€/M tokens
Comparaison providers (prix 2025, indicatifs) :
| Provider | Modèle | Prix input | Prix output | Hardware |
|---|---|---|---|---|
| OpenAI | GPT-4 Turbo | 10$/M | 30$/M | Propriétaire |
| Anthropic | Claude Sonnet 3.5 | 3$/M | 15$/M | Propriétaire |
| Gemini 1.5 Pro | 3,5$/M | 10,5$/M | TPU v5 | |
| Together.ai | LLaMA 70B | 0,9$/M | 0,9$/M | A100 clusters |
| Groq | LLaMA 70B | 0,7$/M | 0,8$/M | LPU (ultra-fast) |
| Self-hosted | LLaMA 70B | ~0,1$/M | ~0,1$/M | A100 (amorti) |
Optimisation inférence : Pour du self-hosting haute performance, vLLM est le framework de référence avec PagedAttention et continuous batching pour maximiser le throughput.
Pour un calcul détaillé du ROI self-hosted vs cloud, consultez notre guide complet.
Hardware Inférence Datacenter
GPU NVIDIA Optimisés Inférence
NVIDIA L4 : Champion rapport performance/prix
Pour un comparatif complet des GPU disponibles pour l’inférence, consultez notre guide.
Specs :
- Architecture : Ada Lovelace
- VRAM : 24 GB GDDR6
- TDP : 72W (très efficient)
- FP16 : 242 TFLOPS
- INT8 : 485 TOPS
- Prix : ~5 000€
- Forme : Low-profile, 1-slot PCIe
Efficacité record : Le L4 délivre 3,36 TFLOPS/Watt, le meilleur ratio de la gamme NVIDIA. Sa densité exceptionnelle permet d’installer 8 GPUs dans un serveur 1U, idéal pour les déploiements à grande échelle.
Avantages :
- Efficacité énergétique : 3,36 TFLOPS/Watt (meilleur de la gamme)
- Densité : 8x L4 dans un serveur 1U
- Coût : 5x moins cher que H100
- Versatile : Inférence LLM, vision, graphiques (vGPU)
Use cases :
- Inférence modèles ≤ 13B (LLaMA 7B, Mistral 7B)
- Embedding models (> 10k embeddings/s)
- Stable Diffusion (~10 images/s, 512×512)
- Whisper transcription (temps réel)
Performance (LLaMA 7B, TensorRT, FP16) :
- Latence (batch 1) : 15ms TTFT, 40 tokens/s
- Throughput (batch 64) : 1 500 tokens/s
NVIDIA L40S : Workloads Mixtes
Specs :
- Architecture : Ada Lovelace
- VRAM : 48 GB GDDR6
- TDP : 350W
- FP16 : 733 TFLOPS
- INT8 : 1 466 TOPS
- Prix : ~8 000€
Avantages :
- VRAM élevée : Modèles jusqu’à 34B en FP16, 70B en INT8
- Performance : 3x L4
- Graphiques : Ray tracing, rendering (studios)
Use cases :
- Inférence modèles 13-70B
- Multi-model serving (plusieurs modèles simultanés)
- Workloads graphiques + IA
NVIDIA H100 : Performance Maximale
Specs :
- Architecture : Hopper
- VRAM : 80 GB HBM3
- TDP : 700W
- FP16 : 1 979 TFLOPS
- FP8 : 3 958 TFLOPS
- INT8 : 3 958 TOPS
- Prix : ~35 000€
Avantages :
- FP8 natif : 2x throughput vs FP16 avec perte qualité minime
- Transformer Engine : Optimisations automatiques LLM
- VRAM : Modèles jusqu’à 70B FP16, 180B INT8
Use cases :
- Inférence modèles > 70B (Falcon 180B, GPT-4-level)
- Ultra-low latency (< 10ms TTFT)
- Serving haute densité (milliers QPS)
Performance (LLaMA 70B, TensorRT, FP8) :
- Latence (batch 1) : 25ms TTFT, 100 tokens/s
- Throughput (batch 256) : 15 000 tokens/s
Comparatif GPU Inférence :
| GPU | VRAM | TDP | Prix | TOPS INT8 | Efficiency | Use Case |
|---|---|---|---|---|---|---|
| L4 | 24 GB | 72W | 5k€ | 485 | ⭐⭐⭐⭐⭐ | Modèles ≤ 13B, coût optimal |
| L40S | 48 GB | 350W | 8k€ | 1 466 | ⭐⭐⭐⭐ | Modèles 13-70B, mixte |
| A100 | 80 GB | 400W | 12k€ | 624 | ⭐⭐⭐ | Legacy, training & inference |
| H100 | 80 GB | 700W | 35k€ | 3 958 | ⭐⭐⭐⭐ | Modèles > 70B, perf max |
Recommandation :
- Budget optimal : L4 (80% des use cases)
- VRAM nécessaire : L40S (48GB)
- Performance max : H100
AMD et Alternatives
AMD Instinct MI210, MI250X
Specs (MI250X) :
- VRAM : 128 GB HBM2e
- TDP : 560W
- FP16 : 383 TFLOPS
- Prix : ~15 000€
Avantages :
- VRAM massive : Modèles jusqu’à 70B sans quantization
- Prix/GB : Meilleur que NVIDIA
Inconvénients :
- Écosystème : ROCm moins mature que CUDA
- Support logiciel : TensorRT, vLLM ont moins d’optimisations AMD
Use cases :
- Entreprises cherchant diversification fournisseurs
- Workloads nécessitant VRAM élevée
- Prix infrastructure critique
Intel Gaudi 2
Specs :
- VRAM : 96 GB HBM2e
- TDP : 600W
- Prix : ~15 000€ (estimé)
Avantages :
- Optimisé pour LLM (architecture dédiée)
- Bon support PyTorch/TensorFlow
Inconvénients :
- Adoption limitée
- Écosystème jeune
Adoption :
- AWS (instances DL1)
- Certaines entreprises (Hugging Face a testé)
Accélérateurs Spécialisés Inférence
Groq LPU (Language Processing Unit)
Principe : Architecture ASIC optimisée exclusivement pour inférence LLM.
Performance :
- LLaMA 70B : 300 tokens/s (vs 100 tokens/s H100)
- Latence ultra-faible : < 10ms TTFT
- Deterministic : Latence constante (pas de variations)
Disponibilité :
- Cloud API : GroqCloud
- Tarif : 0,7$/M tokens (très compétitif)
Limitation :
- Inférence uniquement (pas d’entraînement)
- Modèles supportés limités (Llama, Mixtral)
Cerebras CS-3
Principe : Un seul chip géant (wafer-scale, 46 225 mm²).
Performance :
- GPT-3 175B : 1 800 tokens/s sur un seul chip
- Latence : < 5ms TTFT
Disponibilité :
- Cloud : Cerebras Cloud
- On-premise : Location/achat (> 1M$)
Use case :
- Inférence modèles massifs (> 100B params)
- Entreprises avec budgets illimités
Optimisations Inférence
Quantization
Principe : Réduire la précision numérique des poids (FP16 → INT8 → INT4).
Impact :
| Précision | Taille modèle | Vitesse | Qualité | VRAM (LLaMA 70B) |
|---|---|---|---|---|
| FP16 | 1x | 1x | 100% | 140 GB |
| INT8 | 0,5x | 2-3x | 98-99% | 70 GB |
| INT4 | 0,25x | 4-6x | 95-97% | 35 GB |
| INT2 | 0,125x | 8x+ | 85-90% | 18 GB |
Techniques :
Post-Training Quantization (PTQ) :
- Quantize après entraînement
- Pas besoin de ré-entraînement
- Légère perte de qualité
Quantization-Aware Training (QAT) :
- Entraîne le modèle en anticipant la quantization
- Meilleure qualité
- Plus coûteux
Outils :
# bitsandbytes (facile)
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3-70b",
load_in_8bit=True, # INT8 quantization
device_map="auto",
)
# GPTQ (meilleure qualité)
from auto_gptq import AutoGPTQForCausalLM
model = AutoGPTQForCausalLM.from_quantized(
"TheBloke/Llama-2-70B-GPTQ",
use_triton=True,
)
# AWQ (très rapide)
from awq import AutoAWQForCausalLM
model = AutoAWQForCausalLM.from_quantized(
"TheBloke/Llama-2-70B-AWQ",
fuse_layers=True,
)
Comparatif méthodes :
| Méthode | Qualité | Vitesse | Facilité |
|---|---|---|---|
| bitsandbytes | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| GPTQ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| AWQ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| GGUF | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
TensorRT (NVIDIA)
Définition : SDK NVIDIA pour optimiser l’inférence sur GPU.
Optimisations :
- Graph optimization : Fusion d’opérations
- Kernel auto-tuning : Sélection kernels optimaux
- Precision calibration : INT8 optimal
- Dynamic tensor memory : Réutilisation mémoire
- Multi-stream execution : Parallélisation
Impact : 2-5x speedup vs PyTorch natif
Utilisation :
import tensorrt as trt
from torch2trt import torch2trt
# Conversion PyTorch → TensorRT
model_trt = torch2trt(
model,
[input_tensor],
fp16_mode=True, # FP16 pour Tensor Cores
max_workspace_size=1 << 30, # 1GB workspace
)
# Inférence
output = model_trt(input_tensor)
TensorRT-LLM : Version spécialisée pour LLM
# Conversion LLaMA → TensorRT-LLM
git clone https://github.com/NVIDIA/TensorRT-LLM
cd TensorRT-LLM
python examples/llama/convert_checkpoint.py --model_dir ./llama-7b --output_dir ./trt_ckpt
# Build engine
trtllm-build --checkpoint_dir ./trt_ckpt --output_dir ./trt_engine --gemm_plugin fp16
# Inférence
python examples/run.py --engine_dir ./trt_engine
Performance : LLaMA 7B, A100
- PyTorch FP16 : 40 tokens/s
- TensorRT-LLM FP16 : 120 tokens/s
- TensorRT-LLM FP8 (H100) : 250 tokens/s
vLLM
Définition : Framework open-source optimisé pour serving LLM à haut débit.
Innovations :
- PagedAttention : Gestion mémoire efficace (inspirée de la mémoire virtuelle OS)
- Continuous batching : Ajouter/retirer requêtes dynamiquement
- CUDA graphs : Réduire overhead GPU
Impact : 10-24x throughput vs Hugging Face Transformers standard
Installation :
pip install vllm
Utilisation :
from vllm import LLM, SamplingParams
# Load model
llm = LLM(model="meta-llama/Llama-3-8b", tensor_parallel_size=1)
# Sampling params
sampling_params = SamplingParams(temperature=0.7, top_p=0.9, max_tokens=100)
# Generate
outputs = llm.generate(["Hello, my name is"], sampling_params)
API Server :
vllm serve meta-llama/Llama-3-8b --host 0.0.0.0 --port 8000
# Compatible avec OpenAI API
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Llama-3-8b",
"prompt": "Hello, my name is",
"max_tokens": 100
}'
Benchmarks (A100, LLaMA 7B) :
| Framework | Throughput (tokens/s) | Latence (ms) |
|---|---|---|
| Transformers | 1 000 | 120 |
| Text Generation Inference | 5 000 | 80 |
| vLLM | 12 000 | 60 |
| TensorRT-LLM | 15 000 | 50 |
Text Generation Inference (TGI)
Définition : Framework Hugging Face pour serving production.
Features :
- Optimisations CUDA : Flash Attention, Paged Attention
- Quantization intégrée : bitsandbytes, GPTQ, AWQ
- Continuous batching
- Monitoring : Prometheus metrics
- Streaming : Server-Sent Events
Déploiement :
# Docker
docker run -p 8080:80 \
-v $PWD/data:/data \
ghcr.io/huggingface/text-generation-inference:latest \
--model-id meta-llama/Llama-3-8b \
--quantize bitsandbytes-nf4
API :
from huggingface_hub import InferenceClient
client = InferenceClient("http://localhost:8080")
output = client.text_generation("Hello world", max_new_tokens=50)
Autres Optimisations
Flash Attention : Algorithme attention optimisé mémoire et vitesse
- 2-4x speedup
- Intégré dans PyTorch 2.0+ (
scaled_dot_product_attention)
Speculative Decoding : Générer plusieurs tokens en parallèle avec draft model
- 2-3x speedup pour génération longue
- Qualité identique
KV Cache Optimization :
- Réutiliser les calculs Key/Value des tokens précédents
- Réduction latence 10-50x pour longues conversations
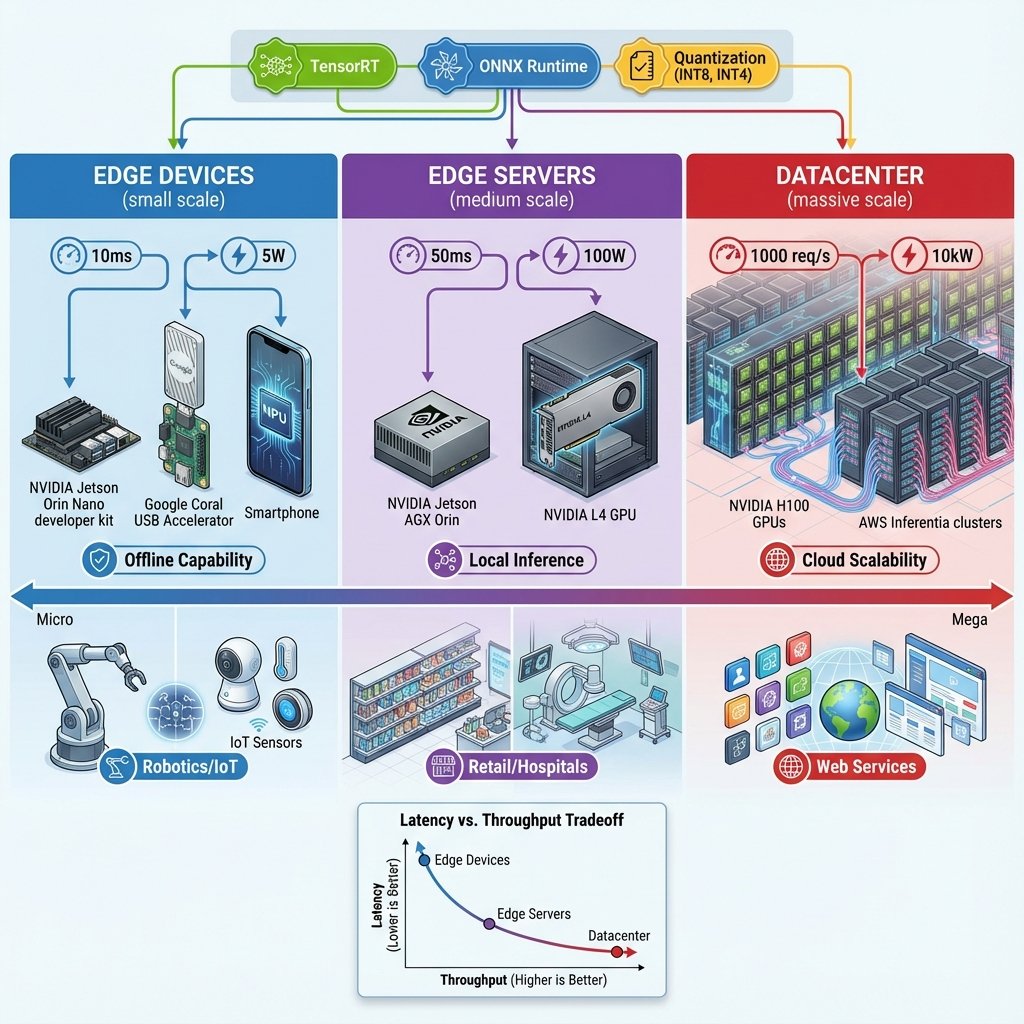
Edge AI et Devices Embarqués
NVIDIA Jetson
Gamme :
| Modèle | GPU | RAM | TDP | Prix | Use Case |
|---|---|---|---|---|---|
| Nano | 128 CUDA cores | 4 GB | 5-10W | 100€ | Prototyping, hobbyist |
| Xavier NX | 384 CUDA cores | 8 GB | 10-15W | 400€ | Robotique, drones |
| Orin Nano | 1024 CUDA cores | 8 GB | 7-15W | 500€ | Edge AI, vision |
| Orin NX | 1024 CUDA cores | 16 GB | 15-25W | 800€ | Véhicules autonomes |
| AGX Orin | 2048 CUDA cores | 64 GB | 15-60W | 2 000€ | Robotique industrielle |
Capacités :
- Jetson Orin Nano :
- YOLOv5 : 60 FPS (détection objets)
- ResNet-50 : 250 FPS
- Whisper tiny : Temps réel
- AGX Orin :
- Multiple caméras 4K simultanées
- LLaMA 7B (quantized) : 5-10 tokens/s
Use cases :
- Robotique (perception, navigation)
- Véhicules autonomes (Tesla utilise hardware similaire)
- Smart cities (caméras de surveillance intelligentes)
- Drones (détection obstacles, tracking)
Google Coral TPU
Principe : TPU miniaturisé pour edge inference.
Formats :
- USB Accelerator : Clé USB (40€)
- Dev Board : Carte avec CPU + TPU (150€)
- M.2 Accelerator : Module M.2 pour intégration (30€)
- PCIe Accelerator : Carte PCIe (120€)
Specs :
- Performance : 4 TOPS (INT8)
- TDP : 2W (USB), 3W (M.2)
- Modèles : TensorFlow Lite uniquement
Capacités :
- MobileNet V2 : 400 FPS
- EfficientDet : 30 FPS
- Latence : 1-5ms
Use cases :
- IoT devices (peu de puissance disponible)
- Détection objets edge (caméras smart)
- Audio processing (keywords spotting)
Limitation :
- TensorFlow Lite uniquement (pas PyTorch direct)
- Modèles doivent être compilés spécifiquement
Apple Silicon
Apple Neural Engine (ANE) : NPU intégré aux puces M1/M2/M3/M4.
Specs :
| Puce | ANE TOPS | Unified Memory | TDP | Prix (Mac) |
|---|---|---|---|---|
| M1 | 11 | 8-16 GB | 20W | MacBook Air (~1 000€) |
| M2 | 15,8 | 8-24 GB | 20W | MacBook Air (~1 200€) |
| M3 Pro | 18 | 18-36 GB | 30W | MacBook Pro (~2 500€) |
| M3 Max | 40 | 36-128 GB | 60W | MacBook Pro (~4 000€) |
| M4 Max | 45+ | 64-192 GB | 90W | MacBook Pro (~5 000€) |
| M2 Ultra | 31,6 | 64-192 GB | 150W | Mac Studio (~5 000€) |
Avantages :
- Unified Memory : CPU, GPU, ANE partagent la RAM (pas de copies)
- Efficacité : 10x moins de consommation que GPU discret équivalent
- Core ML : Framework optimisé Apple
Capacités (M3 Max) :
- Stable Diffusion : 1-2 images/s (512×512)
- Whisper : 10x temps réel
- LLaMA 7B (quantized) : 20-30 tokens/s
- Embeddings : 2 000 embeddings/s
Développement :
# Core ML
import coremltools as ct
# Convert PyTorch → Core ML
model_coreml = ct.convert(
model,
inputs=[ct.TensorType(shape=(1, 3, 224, 224))],
compute_units=ct.ComputeUnit.ALL, # CPU + GPU + ANE
)
model_coreml.save("model.mlpackage")
Use cases :
- Développement IA sur Mac (excellente autonomie)
- Apps iOS/macOS avec ML
- Inference on-device (privacy)
Raspberry Pi 5 + AI Kit
Specs :
- CPU : Quad-core Cortex-A76 @ 2,4 GHz
- RAM : 4-8 GB
- AI Kit : Module Hailo-8L (13 TOPS INT8)
- Prix : 80€ (Pi 5) + 70€ (AI Kit) = 150€
Capacités (avec AI Kit) :
- YOLOv5 : 30 FPS (640×640)
- ResNet-50 : 100 FPS
- Pose estimation : 20 FPS
Use cases :
- Projets IoT éducatifs
- Prototyping edge AI
- Smart home (détection présence, reconnaissance visages)
Smartphones et Mobile
Qualcomm Snapdragon
| Chipset | NPU TOPS | Exemples téléphones | Prix |
|---|---|---|---|
| Snapdragon 8 Gen 3 | 45 | Samsung S24 Ultra, OnePlus 12 | 1 000€+ |
| Snapdragon 8 Gen 2 | 35 | Samsung S23, Xiaomi 13 | 700€+ |
Capacités :
- Stable Diffusion (optimisé) : 10-15s par image
- LLaMA 2B : Temps réel
- Vision models : Temps réel (30 FPS+)
Frameworks :
- TensorFlow Lite : Standard Android
- ONNX Runtime Mobile : Cross-platform
- Qualcomm AI Engine : Optimisations Snapdragon
Use cases :
- Assistants vocaux on-device
- Traduction temps réel
- Photographie computationnelle (HDR, night mode)
- AR/VR (Meta Quest, Apple Vision Pro)
Architectures de Déploiement
Cloud Centralisé
Principe : Tous les modèles dans un datacenter central.
Avantages :
- Économies d’échelle : Mutualisation ressources
- Maintenance : Centralisée, simple
- Hardware puissant : H100, gros modèles
- Updates : Instantanées (pas de déploiement client)
Inconvénients :
- Latence réseau : 50-200ms incompressible
- Coûts bande passante : Data transfer out (AWS : 0,09$/GB)
- Privacy : Données quittent l’appareil
Use cases :
- SaaS grand public (ChatGPT, Midjourney)
- APIs publiques
- Workloads batch (pas de latence critique)
Architecture :
[Utilisateurs] → [Load Balancer] → [Cluster GPU] → [Database]
↓
[Cache (Redis)]
Edge Distribué
Principe : Inférence sur les devices locaux (Jetson, smartphones, IoT).
Avantages :
- Latence minimale : < 10ms (pas de réseau)
- Privacy : Données restent locales
- Résilience : Fonctionne offline
- Coûts : Pas de cloud, pas de bande passante
Inconvénients :
- Hardware limité : Petits modèles uniquement
- Updates : Déploiement complexe (OTA)
- Hétérogénéité : Multiples devices, OS
Use cases :
- Véhicules autonomes (latence critique)
- Santé (privacy RGPD/HIPAA)
- IoT industriel (pas de réseau fiable)
- Mobile apps (offline)
Architecture :
[Device Edge] → [Edge Gateway] → [Cloud (optionnel)]
↓ (local)
[Modèle IA local]
Hybrid Edge-Cloud
Principe : Preprocessing edge, inférence cloud si nécessaire.
Stratégies :
Simple → Edge, Complexe → Cloud :
- Détection objets simples : Edge (Jetson)
- Analyse sémantique complexe : Cloud (H100)
Privacy-sensitive → Edge, Reste → Cloud :
- Données sensibles : Jamais le cloud
- Données anonymes : Cloud si besoin
Fast path → Edge, Slow path → Cloud :
- Réponses rapides : Edge (cache, small models)
- Queries complexes : Cloud
Exemple : Assistant vocal
[Microphone] → [Wake word detection (Edge, Coral TPU)]
↓ (si wake word détecté)
[Speech-to-text (Cloud, Whisper large)]
↓
[LLM (Cloud, GPT-4)]
↓
[Text-to-speech (Edge, cached)]
↓
[Speaker]
Avantages :
- Meilleur compromis latence/coût/qualité
- Privacy préservée pour données sensibles
- Fallback si cloud indisponible
Comparatif Architectures
| Critère | Cloud | Edge | Hybrid |
|---|---|---|---|
| Latence | 50-200ms | < 10ms | 10-100ms |
| Coût | Élevé (continu) | Faible (one-time) | Moyen |
| Privacy | ⚠️ | ✅ | ✅ partiel |
| Puissance modèles | Illimitée | Limitée | Moyenne |
| Offline | ❌ | ✅ | ✅ partiel |
| Complexité | Simple | Moyenne | Élevée |
Cas d’Usage Réels
Chatbot Production (SaaS)
Requirements :
- Latence : < 100ms TTFT
- Throughput : 10 000 QPS peak
- Modèle : LLaMA 70B (qualité élevée)
Solution :
Hardware : 8x L40S (48GB chacun, 8k€/GPU = 64k€)
Software : vLLM + TensorRT-LLM FP8
Serving : Kubernetes + load balancing
Performance :
- TTFT : 40ms
- Throughput : 12 000 QPS
- Coût par 1M tokens : 0,15€
ROI vs Cloud :
- Cloud (H100) : 15$/h × 4 nodes × 24h × 30j = 43 200$/mois
- On-prem : 64k€ amortis sur 36 mois = 1 777€/mois + électricité (500€) = 2 277€/mois
- Économie : 40 923€/mois (break-even : 1,5 mois)
Recherche Sémantique (RAG)
Requirements :
- Latence : < 20ms (embeddings)
- Throughput : 50 000 embeddings/s
- Modèle : bge-large-en (1,3B params)
Solution :
Hardware : 4x L4 (24GB, 5k€/GPU = 20k€)
Software : TensorRT + INT8 quantization
Architecture : Round-robin load balancing
Performance :
- Latence : 8ms
- Throughput : 60 000 embeddings/s
- Coût par 1M embeddings : 0,01€
Génération Image (Stable Diffusion)
Requirements :
- Latence : < 3s (512×512)
- Throughput : 100 images/minute
- Modèle : SDXL (3,5B params)
Solution :
Hardware : 2x L40S (48GB)
Software : Diffusers + TensorRT (UNet optimized)
Optimizations : VAE caching, xFormers
Performance :
- Latence : 2,1s (512×512)
- Throughput : 140 images/minute
- Coût par image : 0,003€
Véhicule Autonome (Edge)
Requirements :
- Latence : < 30ms (temps réel 30 FPS)
- Détection : Objets, lanes, signs
- Modèle : YOLOv8 + lane detection
Solution :
Hardware : NVIDIA Orin (2 000€)
Software : TensorRT + INT8
Cameras : 4x caméras (front, sides, rear)
Performance :
- Latence : 18ms (55 FPS)
- Consommation : 30W
- Offline : ✅ (critique)
Conclusion
L’inférence représente 90% de la charge de calcul IA en production. Optimiser hardware et logiciel est crucial pour la rentabilité et l’expérience utilisateur.
Points clés :
Hardware :
- Cloud datacenter : L4 (meilleur rapport perf/prix), H100 (performance max)
- Edge : Jetson Orin (robotique), Coral TPU (IoT), Apple Silicon (dev)
Optimisations :
- Quantization : INT8 (2-3x speedup, qualité préservée)
- vLLM : 10-24x throughput vs naive PyTorch
- TensorRT : 2-5x speedup GPU NVIDIA
Architecture :
Coûts :
- On-premise rentable si volume > 1M tokens/jour
- L4 : coût inférence 10x inférieur vs H100
- Edge : CapEx uniquement, OpEx minimal
Pour aller plus loin :
- Comparez les différents GPU pour l’inférence
- Découvrez les techniques de quantization
- Explorez l’Edge AI pour l’inférence locale
- Optimisez avec vLLM pour le throughput
- Calculez votre budget et ROI
- Explorez les options cloud
- Préparez votre infrastructure de monitoring