Extraction d'Informations : NER, Classification, Résumés Automatiques
L’extraction d’informations est l’un des cas d’usage les plus puissants et pragmatiques de l’IA en entreprise. Transformer des montagnes de documents non structurés (emails, PDFs, tickets support) en données exploitables a toujours été un défi majeur. Avec les LLMs modernes, c’est devenu accessible, précis et rapide.
Dans ce guide complet, vous découvrirez comment extraire automatiquement des informations depuis vos documents : reconnaître des entités (noms, lieux, dates), classifier des contenus, extraire des données structurées en JSON, générer des résumés intelligents et analyser des sentiments.
Table des Matières
- Pourquoi l’extraction d’informations ?
- Types d’extraction
- Named Entity Recognition (NER)
- Classification de documents
- Extraction de données structurées
- Résumés automatiques
- Sentiment Analysis
- JSON Mode et garanties de structure
- Function Calling pour extraction
- Validation et vérification
- Batch processing à grande échelle
- Use cases réels
- Coûts et optimisation
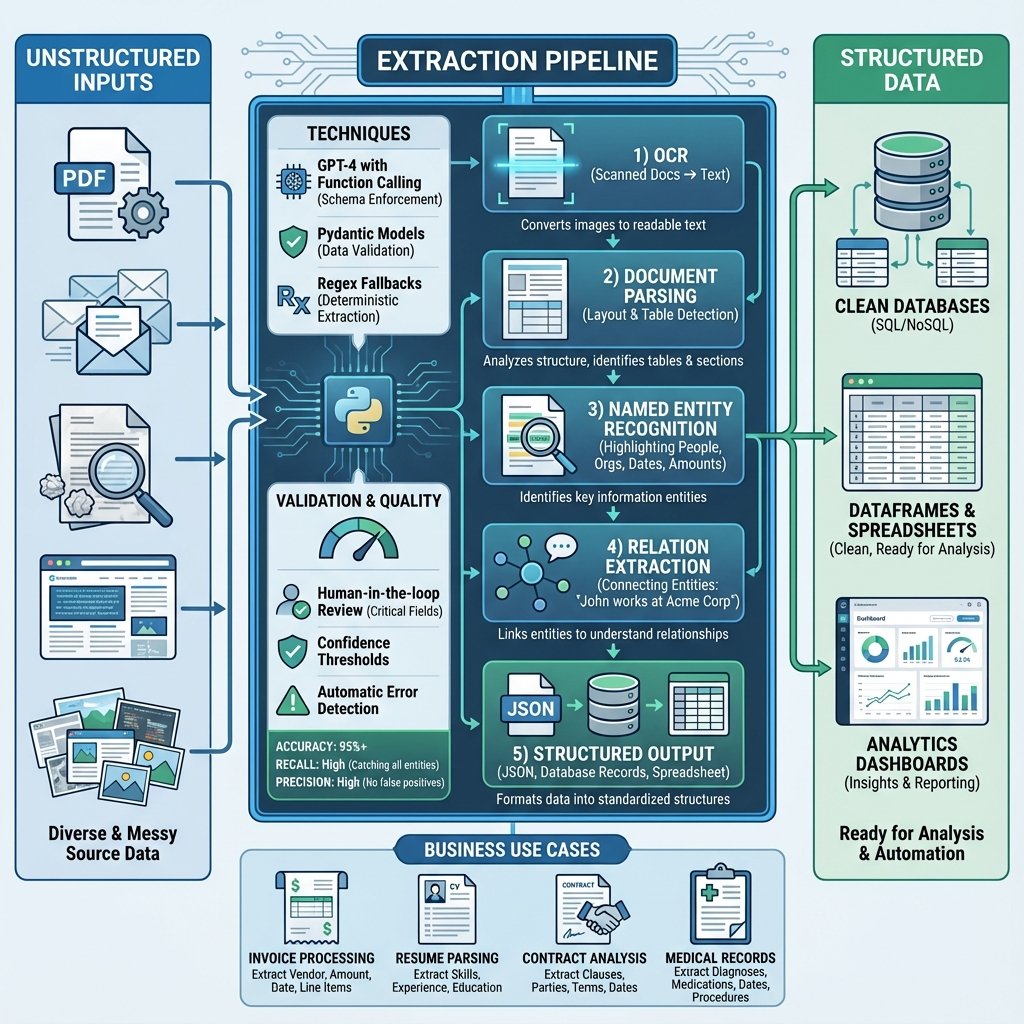
Pourquoi l’extraction d’informations ?
Le problème : données non structurées partout
Dans les entreprises, 80-90% des données sont non structurées :
- 📧 Emails : Milliers par jour, informations critiques noyées
- 📄 Documents : Contrats, factures, rapports PDF
- 🎫 Tickets support : Jira, Zendesk, plaintes clients
- 💬 Chat/Slack : Conversations informelles avec infos importantes
- 🌐 Web scraping : Pages HTML à parser
- 📝 Notes de réunion : Comptes-rendus, actions à suivre
Résultat : Informations impossibles à analyser à grande échelle, perte de temps, décisions sous-informées.
Ce que l’extraction apporte
✅ Automatisation : Traiter 1000 documents en minutes vs jours
✅ Structuration : Transformer texte libre → bases de données
✅ Insights : Identifier tendances, patterns, anomalies
✅ ROI direct : Économie de temps = économie d’argent
✅ Scalabilité : Grandir sans embaucher proportionnellement
Avant vs Après LLMs
| Tâche | Avant (règles/ML classique) | Après (LLMs) |
|---|---|---|
| NER | Modèles spécialisés entraînés (spaCy) | Zero-shot ou few-shot avec GPT-4 |
| Classification | Entraînement supervisé (1000+ exemples) | Few-shot (5-10 exemples) ou zero-shot |
| Extraction JSON | Regex complexes + parsing fragile | Prompt + JSON mode garantit structure |
| Résumés | Extractive (copie phrases) | Abstractive (reformule intelligemment) |
| Sentiment | Dictionnaires + heuristiques | Compréhension nuancée du contexte |
Types d’extraction
Voici les principaux types d’extraction d’informations :
Named Entity Recognition (NER)
Identifier et classer les entités nommées :
- Personnes : “Jean Dupont”, “Marie Martin”
- Organisations : “Microsoft”, “Ministère des Finances”
- Lieux : “Paris”, “123 rue de la Paix”
- Dates : “15 janvier 2025”, “la semaine prochaine”
- Montants : “1 500€”, “2.5 millions de dollars”
- Produits : “iPhone 15 Pro”, “Tesla Model 3”
Use cases : Analyse de contrats, veille média, CRM enrichment
Classification
Catégoriser des documents ou messages :
- Tickets support : Bug / Feature / Question
- Emails : Urgent / Normal / Spam
- Documents : Contrat / Facture / Rapport / Autre
- Sentiment : Positif / Neutre / Négatif
- Intent : Achat / Réclamation / Information
Use cases : Routage automatique, priorisation, analytics
Extraction de données structurées
Transformer texte libre en JSON/CSV :
- Factures : Montant, date, fournisseur, ligne items
- CVs : Compétences, expériences, éducation
- Contrats : Parties, montants, dates clés, clauses
- Formulaires : Champs extraits automatiquement
Use cases : Automatisation comptable, RH, juridique
Résumés
Générer résumés courts et pertinents :
- Articles : TL;DR de 2-3 phrases
- Réunions : Compte-rendu avec action items
- Rapports : Executive summary
- Threads emails : Synthèse de conversation
Use cases : Gain de temps, décision rapide, archivage
Relations et événements
Extraire relations entre entités :
- “Jean Dupont travaille pour Microsoft”
- “Apple a acquis Shazam en 2018 pour 400M$”
- “Le contrat expire le 31/12/2025”
Use cases : Knowledge graphs, due diligence, veille
Named Entity Recognition (NER)
NER avec GPT-4
from openai import OpenAI
import json
client = OpenAI(api_key="xxx")
def extract_entities(text: str) -> dict:
"""
Extraire les entités nommées d'un texte
Returns:
{
"persons": [...],
"organizations": [...],
"locations": [...],
"dates": [...],
"amounts": [...]
}
"""
prompt = f"""Extrais toutes les entités nommées du texte suivant.
Texte :
{text}
Retourne un JSON avec les clés suivantes :
- persons : liste des noms de personnes
- organizations : liste des organisations/entreprises
- locations : liste des lieux (villes, pays, adresses)
- dates : liste des dates mentionnées
- amounts : liste des montants (avec devise)
- products : liste des produits/services mentionnés
Pour chaque entité, indique aussi sa position dans le texte (index de début et fin).
Format de sortie (JSON strict):
{{
"persons": [{{"name": "...", "start": 0, "end": 10}}],
"organizations": [...],
"locations": [...],
"dates": [...],
"amounts": [...],
"products": [...]
}}"""
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": "Tu es un expert en extraction d'entités nommées. Tu retournes toujours un JSON valide."},
{"role": "user", "content": prompt}
],
temperature=0, # Déterministe
response_format={"type": "json_object"} # Force JSON
)
entities = json.loads(response.choices[0].message.content)
return entities
# Exemple d'utilisation
text = """
Apple a annoncé le 12 septembre 2024 le lancement de l'iPhone 16 Pro à 1 299€.
Tim Cook, PDG d'Apple, a présenté le produit depuis le Steve Jobs Theater à Cupertino, Californie.
Les précommandes débutent le 15 septembre en France, Allemagne et Royaume-Uni.
"""
entities = extract_entities(text)
print(json.dumps(entities, indent=2, ensure_ascii=False))
Sortie attendue :
{
"persons": [
{"name": "Tim Cook", "start": 105, "end": 113}
],
"organizations": [
{"name": "Apple", "start": 0, "end": 5},
{"name": "Apple", "start": 118, "end": 123}
],
"locations": [
{"name": "Steve Jobs Theater", "start": 158, "end": 176},
{"name": "Cupertino, Californie", "start": 179, "end": 199},
{"name": "France", "start": 240, "end": 246},
{"name": "Allemagne", "start": 248, "end": 257},
{"name": "Royaume-Uni", "start": 261, "end": 272}
],
"dates": [
{"date": "12 septembre 2024", "start": 19, "end": 36},
{"date": "15 septembre", "start": 223, "end": 236}
],
"amounts": [
{"amount": "1 299€", "start": 75, "end": 81}
],
"products": [
{"name": "iPhone 16 Pro", "start": 54, "end": 67}
]
}
NER avec Few-Shot Learning
Pour améliorer la précision sur des domaines spécifiques :
def extract_medical_entities(text: str) -> dict:
"""NER spécialisé médical"""
few_shot_examples = """
Exemple 1:
Texte: "Le patient Jean Dupont, 45 ans, présente une hypertension artérielle. Prescription: Amlodipine 5mg, 1x/jour."
Entités:
{
"patient": "Jean Dupont",
"age": 45,
"conditions": ["hypertension artérielle"],
"medications": [{"name": "Amlodipine", "dosage": "5mg", "frequency": "1x/jour"}]
}
Exemple 2:
Texte: "Marie Martin, diabète de type 2 depuis 2020. Glycémie à jeun: 1.8 g/L. Metformine 850mg matin et soir."
Entités:
{
"patient": "Marie Martin",
"conditions": ["diabète de type 2"],
"condition_start_year": 2020,
"lab_results": [{"test": "glycémie à jeun", "value": "1.8 g/L"}],
"medications": [{"name": "Metformine", "dosage": "850mg", "frequency": "matin et soir"}]
}
Maintenant, extrais les entités du texte suivant:
Texte: {text}
Entités (JSON):
"""
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": "Tu es un expert en extraction d'informations médicales."},
{"role": "user", "content": few_shot_examples.format(text=text)}
],
temperature=0,
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
# Test
medical_text = """
Pierre Durand, 62 ans, consulte pour douleurs thoraciques.
Antécédents: infarctus en 2018, cholestérol élevé.
Examen: tension 160/95, fréquence cardiaque 88 bpm.
Traitement actuel: Atorvastatine 20mg le soir, Ramipril 5mg le matin.
"""
entities = extract_medical_entities(medical_text)
print(json.dumps(entities, indent=2, ensure_ascii=False))
Attention santé : L’extraction d’informations médicales nécessite une validation rigoureuse. Ne jamais utiliser en production sans supervision médicale et conformité RGPD/HIPAA.
NER avec spaCy (comparaison)
Pour comparaison, voici spaCy (approche traditionnelle) :
import spacy
# Charger modèle français
nlp = spacy.load("fr_core_news_lg")
def extract_entities_spacy(text: str) -> dict:
"""NER avec spaCy"""
doc = nlp(text)
entities = {
"persons": [],
"organizations": [],
"locations": [],
"dates": [],
"amounts": []
}
for ent in doc.ents:
entity_info = {
"text": ent.text,
"start": ent.start_char,
"end": ent.end_char,
"label": ent.label_
}
if ent.label_ == "PER": # Personne
entities["persons"].append(entity_info)
elif ent.label_ == "ORG": # Organisation
entities["organizations"].append(entity_info)
elif ent.label_ in ["LOC", "GPE"]: # Lieu
entities["locations"].append(entity_info)
# etc.
return entities
Comparaison spaCy vs GPT-4 :
| Critère | spaCy | GPT-4 |
|---|---|---|
| Précision | 85-90% (domaine général) | 95%+ |
| Domaines spécialisés | Nécessite fine-tuning | Zero/few-shot suffit |
| Coût | Gratuit (local) | ~$0.01 pour 1000 tokens |
| Latence | <10ms | 500-1000ms |
| Offline | ✅ Oui | ❌ Non (API) |
| Maintenance | Modèle à jour | API toujours à jour |
Recommandation : spaCy pour volume énorme + latence critique, GPT-4 pour précision maximale + domaines variés.
Classification de documents
Classification simple (une catégorie)
def classify_support_ticket(ticket_text: str) -> dict:
"""
Classifier un ticket support
Catégories :
- bug : Problème technique à corriger
- feature : Demande de nouvelle fonctionnalité
- question : Simple question
- documentation : Problème de doc
"""
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{
"role": "system",
"content": """Tu es un classificateur de tickets support.
Catégories possibles :
- bug : Problème technique, erreur, crash
- feature : Demande de nouvelle fonctionnalité
- question : Simple question sur utilisation
- documentation : Documentation manquante ou incorrecte
Retourne un JSON avec :
- category : la catégorie choisie
- confidence : score de confiance (0-1)
- reasoning : explication courte de ton choix"""
},
{"role": "user", "content": f"Ticket:\n{ticket_text}\n\nClassification (JSON):"}
],
temperature=0,
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
# Exemples
tickets = [
"L'application plante quand je clique sur Enregistrer. Erreur 500.",
"Serait-il possible d'ajouter un export Excel dans les rapports ?",
"Comment changer mon mot de passe ?",
"La doc sur les webhooks ne correspond pas au comportement réel de l'API."
]
for ticket in tickets:
result = classify_support_ticket(ticket)
print(f"📋 Ticket: {ticket[:50]}...")
print(f" → {result['category']} (confiance: {result['confidence']})")
print(f" → Raison: {result['reasoning']}\n")
Sortie attendue :
📋 Ticket: L'application plante quand je clique sur Enregistr...
→ bug (confiance: 0.95)
→ Raison: Erreur 500 indique un problème technique serveur
📋 Ticket: Serait-il possible d'ajouter un export Excel dans...
→ feature (confiance: 0.98)
→ Raison: Demande explicite de nouvelle fonctionnalité
📋 Ticket: Comment changer mon mot de passe ?...
→ question (confiance: 0.99)
→ Raison: Question simple sur utilisation basique
📋 Ticket: La doc sur les webhooks ne correspond pas au compo...
→ documentation (confiance: 0.92)
→ Raison: Mentionne explicitement problème de documentation
Classification multi-label
Pour les cas où un document peut avoir plusieurs catégories :
def classify_email_multi_label(email_text: str) -> dict:
"""
Classification multi-label d'un email
Labels possibles (peut en avoir plusieurs) :
- action_required : Nécessite une action
- urgent : Urgent
- customer_facing : Concerne un client
- financial : Aspect financier
- legal : Aspect juridique
- internal : Interne seulement
"""
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{
"role": "system",
"content": """Classifie l'email avec tous les labels applicables.
Labels disponibles :
- action_required : L'email nécessite une action/réponse
- urgent : Marqué urgent ou deadline proche
- customer_facing : Concerne un client externe
- financial : Montants, budget, facturation
- legal : Contrats, conformité, juridique
- internal : Communication interne uniquement
Retourne JSON :
{
"labels": ["label1", "label2", ...],
"priority_score": 1-10,
"suggested_assignee": "équipe ou personne",
"deadline": "YYYY-MM-DD ou null"
}"""
},
{"role": "user", "content": f"Email:\n{email_text}"}
],
temperature=0,
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
# Exemple
email = """
Objet: URGENT - Problème facturation client Acme Corp
Bonjour,
Le client Acme Corp signale une erreur sur sa facture de décembre :
montant facturé 15 000€ au lieu de 12 000€ convenu contractuellement.
Ils menacent de suspendre le paiement si non résolu avant le 15/01.
Merci de traiter en priorité avec le service compta et juridique.
Sophie
"""
result = classify_email_multi_label(email)
print(json.dumps(result, indent=2, ensure_ascii=False))
Sortie :
{
"labels": [
"action_required",
"urgent",
"customer_facing",
"financial",
"legal"
],
"priority_score": 9,
"suggested_assignee": "Équipe Finance + Juridique",
"deadline": "2025-01-15"
}
Classification avec confidence scoring
def classify_with_confidence_threshold(
text: str,
categories: list[str],
confidence_threshold: float = 0.7
) -> dict:
"""
Classifier avec seuil de confiance
Si confiance < seuil, retourne "uncertain" pour review humaine
"""
categories_str = ", ".join(categories)
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{
"role": "system",
"content": f"""Classifie le texte parmi : {categories_str}
Retourne JSON :
{{
"category": "...",
"confidence": 0-1,
"top_3_probabilities": {{
"cat1": 0.X,
"cat2": 0.Y,
"cat3": 0.Z
}}
}}"""
},
{"role": "user", "content": text}
],
temperature=0,
response_format={"type": "json_object"}
)
result = json.loads(response.choices[0].message.content)
# Appliquer seuil
if result["confidence"] < confidence_threshold:
result["needs_human_review"] = True
result["category"] = "uncertain"
else:
result["needs_human_review"] = False
return result
# Test sur cas ambigus
ambiguous_text = "Le produit est correct mais pas exceptionnel. Quelques petits défauts."
result = classify_with_confidence_threshold(
ambiguous_text,
categories=["positive", "neutral", "negative"],
confidence_threshold=0.7
)
if result["needs_human_review"]:
print("⚠️ Confiance faible, review humaine recommandée")
print(f" Probabilités: {result['top_3_probabilities']}")
Extraction de données structurées
Extraction de factures
from pydantic import BaseModel, Field
from typing import List, Optional
class LineItem(BaseModel):
"""Ligne de facture"""
description: str
quantity: float
unit_price: float
total: float
tax_rate: Optional[float] = None
class Invoice(BaseModel):
"""Facture structurée"""
invoice_number: str
invoice_date: str
due_date: Optional[str] = None
# Fournisseur
supplier_name: str
supplier_address: Optional[str] = None
supplier_vat_number: Optional[str] = None
# Client
customer_name: str
customer_address: Optional[str] = None
# Montants
subtotal: float
tax_amount: float
total_amount: float
currency: str = "EUR"
# Lignes
line_items: List[LineItem]
# Infos paiement
payment_method: Optional[str] = None
bank_details: Optional[str] = None
def extract_invoice(invoice_text: str) -> Invoice:
"""
Extraire données structurées d'une facture
Args:
invoice_text: Texte OCR de la facture
Returns:
Invoice object avec tous les champs structurés
"""
# Utiliser function calling pour garantir la structure
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{
"role": "system",
"content": """Tu es un expert en extraction de données de factures.
Extrais TOUTES les informations disponibles dans le texte.
Si une info n'est pas présente, utilise null."""
},
{
"role": "user",
"content": f"Extrais les données de cette facture:\n\n{invoice_text}"
}
],
functions=[{
"name": "save_invoice",
"description": "Sauvegarder les données d'une facture",
"parameters": Invoice.model_json_schema()
}],
function_call={"name": "save_invoice"},
temperature=0
)
# Parser la réponse
function_args = json.loads(
response.choices[0].message.function_call.arguments
)
return Invoice(**function_args)
# Exemple de facture (texte OCR)
invoice_ocr_text = """
FACTURE N° 2025-001
Date: 15 janvier 2025
Date d'échéance: 15 février 2025
Fournisseur:
TechCorp Solutions
123 Avenue des Champs-Élysées
75008 Paris
TVA: FR12345678901
Client:
Entreprise Dupont SARL
45 Rue de la Paix
69001 Lyon
Description Qté P.U. Total
─────────────────────────────────────────────────────────
Licence logiciel Pro (12 mois) 5 199.00€ 995.00€
Support premium 1 299.00€ 299.00€
Formation (2 jours) 1 800.00€ 800.00€
Sous-total HT: 2,094.00€
TVA (20%): 418.80€
TOTAL TTC: 2,512.80€
Paiement par virement bancaire
IBAN: FR76 1234 5678 9012 3456 7890 123
BIC: BNPAFRPPXXX
Merci de votre confiance.
"""
invoice = extract_invoice(invoice_ocr_text)
# Afficher résultat structuré
print("📄 Facture extraite:")
print(f" Numéro: {invoice.invoice_number}")
print(f" Date: {invoice.invoice_date}")
print(f" Fournisseur: {invoice.supplier_name}")
print(f" Client: {invoice.customer_name}")
print(f" Total: {invoice.total_amount} {invoice.currency}")
print(f" Lignes: {len(invoice.line_items)}")
for item in invoice.line_items:
print(f" - {item.description}: {item.quantity} × {item.unit_price}€ = {item.total}€")
# Sauvegarder en JSON
with open("invoice_2025_001.json", "w") as f:
f.write(invoice.model_dump_json(indent=2))
# Ou insérer en base de données
# db.invoices.insert_one(invoice.model_dump())
Extraction de CVs
class Experience(BaseModel):
"""Expérience professionnelle"""
company: str
position: str
start_date: str
end_date: Optional[str] = None # None = en cours
description: Optional[str] = None
achievements: List[str] = []
class Education(BaseModel):
"""Formation"""
institution: str
degree: str
field: str
graduation_year: Optional[int] = None
class Resume(BaseModel):
"""CV structuré"""
# Informations personnelles
full_name: str
email: Optional[str] = None
phone: Optional[str] = None
location: Optional[str] = None
linkedin: Optional[str] = None
# Profil
professional_summary: Optional[str] = None
# Expériences
experiences: List[Experience]
# Formation
education: List[Education]
# Compétences
technical_skills: List[str] = []
languages: List[dict] = [] # [{"language": "Anglais", "level": "Courant"}]
soft_skills: List[str] = []
# Autre
certifications: List[str] = []
interests: List[str] = []
def extract_resume(cv_text: str) -> Resume:
"""Extraire données structurées d'un CV"""
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{
"role": "system",
"content": """Extrais toutes les informations d'un CV de manière structurée.
Pour les dates :
- Si "depuis 2020" ou "2020 - présent" → end_date = null
- Format YYYY-MM si mois disponible, sinon YYYY
Pour les compétences :
- technical_skills : technologies, langages de prog, outils
- soft_skills : leadership, communication, etc.
Sois exhaustif."""
},
{"role": "user", "content": f"CV à extraire:\n\n{cv_text}"}
],
functions=[{
"name": "save_resume",
"description": "Sauvegarder les données d'un CV",
"parameters": Resume.model_json_schema()
}],
function_call={"name": "save_resume"},
temperature=0
)
function_args = json.loads(
response.choices[0].message.function_call.arguments
)
return Resume(**function_args)
# Exemple
cv_text = """
Jean MARTIN
Développeur Full Stack Senior
📧 [email protected] | 📱 06 12 34 56 78 | 📍 Paris
💼 linkedin.com/in/jeanmartin
PROFIL
Développeur passionné avec 8 ans d'expérience en développement web.
Expert React/Node.js, spécialisé dans les architectures scalables.
EXPÉRIENCES
Lead Developer | TechCorp | Paris
Mars 2021 - Présent
- Architecte et développe une plateforme SaaS (React, Node.js, PostgreSQL)
- Manage une équipe de 5 développeurs
- Migration vers microservices → -40% latence, +99.9% uptime
- Mise en place CI/CD avec GitHub Actions
Senior Full Stack Developer | Startup XYZ | Lyon
Janvier 2018 - Février 2021
- Développement features produit (React, Express, MongoDB)
- Refonte complète UI/UX → +25% conversion
- Intégration Stripe, SendGrid, AWS S3
Développeur JavaScript | Agence Web | Paris
Septembre 2015 - Décembre 2017
- Développement sites vitrine et e-commerce
- WordPress, Shopify, développements custom
FORMATION
Master Informatique | Université Paris-Saclay | 2015
Spécialisation : Génie Logiciel
Licence Informatique | Université Claude Bernard Lyon 1 | 2013
COMPÉTENCES TECHNIQUES
- Frontend : React, TypeScript, Next.js, Tailwind CSS
- Backend : Node.js, Express, NestJS, Python/Django
- Databases : PostgreSQL, MongoDB, Redis
- DevOps : Docker, Kubernetes, AWS, GitHub Actions
- Outils : Git, Jira, Figma
LANGUES
- Français : Langue maternelle
- Anglais : Courant (TOEIC 950)
- Espagnol : Intermédiaire
CERTIFICATIONS
- AWS Certified Solutions Architect (2023)
- Certified Kubernetes Administrator (2022)
CENTRES D'INTÉRÊT
Open source (contributeur React), photographie, escalade
"""
resume = extract_resume(cv_text)
print(f"📝 CV de {resume.full_name}")
print(f" 📧 {resume.email} | 📱 {resume.phone}")
print(f" 💼 {len(resume.experiences)} expériences")
print(f" 🎓 {len(resume.education)} diplômes")
print(f" 💻 {len(resume.technical_skills)} compétences techniques")
print(f" 🌍 {len(resume.languages)} langues")
# Exporter en JSON pour ATS (Applicant Tracking System)
with open(f"resume_{resume.full_name.replace(' ', '_')}.json", "w") as f:
f.write(resume.model_dump_json(indent=2, exclude_none=True))
Astuce pour CVs en PDF : Utilisez d’abord un outil OCR (Tesseract, AWS Textract, GPT-4V) pour convertir PDF → texte, puis appliquez l’extraction structurée.
Résumés automatiques
Résumé extractif vs abstractif
Extractif : Copie les phrases les plus importantes (ancien) Abstractif : Reformule intelligemment (LLMs)
def generate_summary(
text: str,
style: str = "executive", # executive, bullet_points, tweet
max_length: int = 200
) -> str:
"""
Générer un résumé intelligent
Args:
text: Texte à résumer
style: Style de résumé
max_length: Longueur max en mots
Styles disponibles :
- executive : Résumé formel pour décideurs
- bullet_points : Liste à puces des points clés
- tweet : Version ultra-courte (<280 car.)
- eli5 : Explain Like I'm 5 (vulgarisation max)
"""
style_prompts = {
"executive": f"Rédige un résumé exécutif professionnel en {max_length} mots max. Public : dirigeants d'entreprise.",
"bullet_points": f"Résume en {max_length // 10} points clés maximum (bullet points). Commence chaque point par un verbe d'action.",
"tweet": "Résume en moins de 280 caractères, style tweet engageant avec 1-2 émojis pertinents.",
"eli5": f"Explique en {max_length} mots max comme si je_had 5 ans. Simple, clair, analogies si besoin."
}
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{
"role": "system",
"content": f"""Tu es un expert en résumés.
{style_prompts.get(style, style_prompts['executive'])}
Règles :
- Garde les informations les PLUS importantes
- Sois factuel, pas de remplissage
- Préserve chiffres et noms clés
- Pas de "cet article parle de..." → directement le contenu"""
},
{"role": "user", "content": f"Texte à résumer:\n\n{text}"}
],
temperature=0.3 # Légère créativité pour reformulation
)
return response.choices[0].message.content
# Exemples
long_article = """
[Supposons un long article de 2000 mots sur l'IA en entreprise...]
L'intelligence artificielle transforme radicalement le monde de l'entreprise.
Selon une étude McKinsey de 2024, 72% des entreprises du Fortune 500 ont déployé
au moins une solution IA en production. Les gains de productivité observés
varient de 15% à 40% selon les secteurs...
[etc.]
"""
# Style executif
print("📊 RÉSUMÉ EXÉCUTIF:")
print(generate_summary(long_article, style="executive", max_length=150))
print()
# Bullet points
print("📋 POINTS CLÉS:")
print(generate_summary(long_article, style="bullet_points"))
print()
# Tweet
print("🐦 VERSION TWEET:")
print(generate_summary(long_article, style="tweet"))
Résumé de réunions avec action items
from pydantic import BaseModel
from typing import List
class ActionItem(BaseModel):
"""Tâche à faire"""
task: str
assignee: Optional[str] = None
deadline: Optional[str] = None
priority: str = "normal" # low, normal, high
class MeetingSummary(BaseModel):
"""Compte-rendu de réunion structuré"""
meeting_title: str
date: str
participants: List[str]
# Résumé
key_points: List[str] # 3-5 points principaux
decisions_made: List[str] # Décisions prises
action_items: List[ActionItem] # Tâches à faire
# Optionnel
next_meeting_date: Optional[str] = None
blockers: List[str] = [] # Blocages identifiés
def summarize_meeting(transcript: str) -> MeetingSummary:
"""
Résumer une transcription de réunion
Args:
transcript: Transcription Whisper/Otter/etc.
Returns:
Compte-rendu structuré avec action items
"""
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{
"role": "system",
"content": """Tu génères des comptes-rendus de réunion structurés.
Identifie :
1. Points clés discutés (3-5 max, les PLUS importants)
2. Décisions formellement prises
3. Action items avec assignation si mentionné
Pour les action items :
- Si "Jean, tu peux faire X" → assignee: "Jean"
- Si "d'ici vendredi" → deadline: date
- Si "urgent", "critique" → priority: "high"
Sois concis et factuel."""
},
{
"role": "user",
"content": f"Transcription de réunion:\n\n{transcript}\n\nGénère le compte-rendu structuré."
}
],
functions=[{
"name": "save_meeting_summary",
"description": "Sauvegarder le compte-rendu de réunion",
"parameters": MeetingSummary.model_json_schema()
}],
function_call={"name": "save_meeting_summary"},
temperature=0
)
function_args = json.loads(
response.choices[0].message.function_call.arguments
)
return MeetingSummary(**function_args)
# Exemple
meeting_transcript = """
Réunion Sprint Planning - 15 janvier 2025
Participants: Sophie (PM), Marc (Tech Lead), Julie (Dev), Thomas (Designer)
Sophie: Bonjour à tous. Aujourd'hui on planifie le sprint 12. Objectif principal :
finaliser le nouveau dashboard analytics demandé par le client Acme Corp.
Marc: OK. On a 3 user stories prioritaires : intégration API analytics,
UI des graphiques, et export PDF. Je pense qu'on peut tout finir en 2 semaines
mais il faudra que Thomas ait les maquettes finales d'ici jeudi.
Thomas: Pas de problème, je les aurai prêtes mercredi. Par contre, pour le
choix des couleurs, il faut valider avec le client. Sophie, tu peux organiser
un call rapide avec eux cette semaine ?
Sophie: Oui, je schedule ça pour jeudi après-midi. Julie, tu es dispo pour
y participer ?
Julie: Oui. Une question Marc : pour l'export PDF, on utilise quelle librairie ?
J'ai vu qu'on avait eu des soucis avec pdfmake sur le projet précédent.
Marc: Bonne question. Je propose qu'on teste puppeteer cette fois. Plus fiable.
Julie, tu peux faire un POC d'ici lundi prochain ? Juste générer un PDF basique
pour valider que ça marche bien.
Julie: OK, je note.
Sophie: Super. Donc récap : Thomas livre les maquettes mercredi, j'organise le call
client jeudi, Julie fait le POC PDF lundi. On se revoit lundi prochain pour faire
le point. Des blocages à signaler ?
Marc: Oui, on attend toujours les accès à l'environnement de staging du client.
Ça fait 1 semaine. Sophie, tu peux escalader ? C'est bloquant pour les tests.
Sophie: OK, je relance leur IT aujourd'hui même. Urgent. Autre chose ?
[Discussion continue...]
Sophie: Parfait. Prochaine réunion : lundi 22 janvier, 14h. Merci tout le monde !
"""
summary = summarize_meeting(meeting_transcript)
# Afficher compte-rendu
print(f"📅 {summary.meeting_title}")
print(f"Date: {summary.date}")
print(f"Participants: {', '.join(summary.participants)}\n")
print("🔑 POINTS CLÉS:")
for i, point in enumerate(summary.key_points, 1):
print(f" {i}. {point}")
print("\n✅ DÉCISIONS:")
for decision in summary.decisions_made:
print(f" • {decision}")
print("\n📋 ACTION ITEMS:")
for item in summary.action_items:
assignee_str = f" ({item.assignee})" if item.assignee else ""
deadline_str = f" - ⏰ {item.deadline}" if item.deadline else ""
priority_icon = "🔴" if item.priority == "high" else "🟡" if item.priority == "normal" else "🟢"
print(f" {priority_icon} {item.task}{assignee_str}{deadline_str}")
if summary.blockers:
print("\n⚠️ BLOCAGES:")
for blocker in summary.blockers:
print(f" • {blocker}")
print(f"\n➡️ Prochaine réunion: {summary.next_meeting_date}")
# Envoyer par email automatiquement
send_email(
to=", ".join([f"{p}@company.com" for p in summary.participants]),
subject=f"CR: {summary.meeting_title}",
body=format_meeting_summary_html(summary)
)
Sentiment Analysis
from enum import Enum
class Sentiment(str, Enum):
VERY_NEGATIVE = "very_negative"
NEGATIVE = "negative"
NEUTRAL = "neutral"
POSITIVE = "positive"
VERY_POSITIVE = "very_positive"
class SentimentAnalysis(BaseModel):
"""Analyse de sentiment détaillée"""
overall_sentiment: Sentiment
confidence: float # 0-1
sentiment_score: float # -1 (très négatif) à +1 (très positif)
# Émotions détectées
emotions: List[str] = [] # joie, colère, frustration, satisfaction, etc.
# Aspects (pour reviews produits)
aspect_sentiments: dict = {} # {"qualité": "positive", "prix": "negative"}
# Indicateurs
is_sarcastic: bool = False
urgency_level: str = "normal" # low, normal, high, critical
def analyze_sentiment(text: str) -> SentimentAnalysis:
"""Analyse de sentiment avancée"""
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{
"role": "system",
"content": """Analyse le sentiment d'un texte de manière nuancée.
Sentiment global :
- very_negative : Très mécontent, en colère
- negative : Insatisfait, déçu
- neutral : Neutre, factuel
- positive : Satisfait, content
- very_positive : Très satisfait, enthousiaste
Détecte aussi :
- Émotions sous-jacentes (joie, colère, frustration, etc.)
- Sarcasme / ironie
- Urgence (critique si menace, deadline proche)
- Pour les reviews : sentiment par aspect (qualité, prix, service, etc.)
Sois précis sur le score (-1 à +1)."""
},
{"role": "user", "content": f"Texte à analyser:\n\n{text}"}
],
functions=[{
"name": "save_sentiment",
"description": "Sauvegarder l'analyse de sentiment",
"parameters": SentimentAnalysis.model_json_schema()
}],
function_call={"name": "save_sentiment"},
temperature=0
)
function_args = json.loads(
response.choices[0].message.function_call.arguments
)
return SentimentAnalysis(**function_args)
# Exemples variés
texts = [
# Très négatif
"""J'ai acheté ce produit il y a 2 semaines et il est déjà cassé.
Le service client ne répond pas depuis 5 jours. Inadmissible pour le prix.
Je veux un remboursement IMMÉDIATEMENT sinon je contacte ma banque.""",
# Négatif mais constructif
"""Le produit est correct dans l'ensemble, mais je suis déçu par la qualité
des finitions. Pour 200€, je m'attendais à mieux. Le SAV a été réactif par contre.""",
# Neutre/factuel
"""J'ai reçu ma commande en 3 jours. Conforme à la description. RAS.""",
# Positif
"""Très satisfait de mon achat ! Le produit correspond exactement à ce que
je cherchais. Livraison rapide et emballage soigné. Je recommande.""",
# Très positif
"""WOW ! Ce produit a dépassé toutes mes attentes ! Qualité exceptionnelle,
service client aux petits oignons. J'en ai déjà commandé 2 autres pour offrir.
Bravo à l'équipe ! ⭐⭐⭐⭐⭐""",
# Sarcastique
"""Génial, encore un bug après la mise à jour. Vraiment, bravo les développeurs,
vous faites un travail "remarquable". 3ème fois ce mois-ci. Continuez comme ça ! 👏"""
]
print("📊 ANALYSE DE SENTIMENTS\n" + "="*60)
for i, text in enumerate(texts, 1):
analysis = analyze_sentiment(text)
# Couleur selon sentiment
sentiment_colors = {
Sentiment.VERY_NEGATIVE: "🔴",
Sentiment.NEGATIVE: "🟠",
Sentiment.NEUTRAL: "⚪",
Sentiment.POSITIVE: "🟢",
Sentiment.VERY_POSITIVE: "🟢✨"
}
icon = sentiment_colors[analysis.overall_sentiment]
print(f"\n{i}. {icon} {analysis.overall_sentiment.value.upper()}")
print(f" Score: {analysis.sentiment_score:.2f} | Confiance: {analysis.confidence:.0%}")
if analysis.emotions:
print(f" Émotions: {', '.join(analysis.emotions)}")
if analysis.is_sarcastic:
print(f" ⚠️ Sarcasme détecté")
if analysis.urgency_level != "normal":
print(f" 🚨 Urgence: {analysis.urgency_level}")
if analysis.aspect_sentiments:
print(f" Aspects:")
for aspect, sent in analysis.aspect_sentiments.items():
print(f" • {aspect}: {sent}")
print(f" Texte: {text[:80]}...")
Monitoring de satisfaction client à grande échelle
def batch_sentiment_analysis(texts: List[str]) -> dict:
"""
Analyser le sentiment de milliers de messages
Returns:
{
"summary": {"positive": 120, "negative": 30, ...},
"average_score": 0.65,
"flagged_urgent": [...],
"trends": {...}
}
"""
results = []
# Batch par 100 pour optimiser coûts
for i in range(0, len(texts), 100):
batch = texts[i:i+100]
# Un seul appel pour 100 textes
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{
"role": "system",
"content": "Analyse le sentiment de chaque texte. Retourne un JSON array."
},
{
"role": "user",
"content": f"Textes (JSON array):\n{json.dumps(batch, ensure_ascii=False)}"
}
],
response_format={"type": "json_object"},
temperature=0
)
batch_results = json.loads(response.choices[0].message.content)
results.extend(batch_results["sentiments"])
# Agrégation
summary = {"very_positive": 0, "positive": 0, "neutral": 0, "negative": 0, "very_negative": 0}
total_score = 0
urgent_cases = []
for r in results:
summary[r["sentiment"]] += 1
total_score += r["score"]
if r.get("urgency") == "critical":
urgent_cases.append(r)
return {
"summary": summary,
"average_score": total_score / len(results),
"flagged_urgent": urgent_cases,
"total_analyzed": len(results)
}
JSON Mode et garanties de structure
Depuis GPT-4 Turbo, OpenAI propose un JSON Mode qui garantit que la sortie sera un JSON valide.
# Avec JSON mode (recommandé)
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": "Tu retournes toujours un JSON valide."},
{"role": "user", "content": "Extrais les infos..."}
],
response_format={"type": "json_object"} # ← Force JSON
)
# Garantit que response.choices[0].message.content est un JSON parsable
data = json.loads(response.choices[0].message.content)
Avec Anthropic Claude
Claude utilise une approche légèrement différente :
import anthropic
client = anthropic.Anthropic(api_key="xxx")
response = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=2000,
messages=[
{
"role": "user",
"content": """Extrais les informations et retourne UNIQUEMENT un JSON.
Format attendu:
{
"name": "...",
"email": "...",
"items": [...]
}
Texte:
[...]
"""
}
]
)
# Parser
data = json.loads(response.content[0].text)
Validation avec Pydantic
Pydantic garantit la structure ET les types :
from pydantic import BaseModel, EmailStr, field_validator
from datetime import date
class User(BaseModel):
"""Utilisateur avec validation stricte"""
name: str
email: EmailStr # Valide format email
age: int
signup_date: date
tags: List[str] = []
@field_validator('age')
@classmethod
def validate_age(cls, v):
if v < 18:
raise ValueError('L\'utilisateur doit avoir au moins 18 ans')
if v > 120:
raise ValueError('Âge invalide')
return v
@field_validator('name')
@classmethod
def validate_name(cls, v):
if len(v) < 2:
raise ValueError('Le nom doit faire au moins 2 caractères')
return v.strip().title()
# Extraction + validation
def extract_user_safe(text: str) -> User:
"""Extraction avec validation Pydantic"""
try:
# Extraction via LLM
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": "Extrais les infos utilisateur en JSON."},
{"role": "user", "content": text}
],
functions=[{
"name": "save_user",
"parameters": User.model_json_schema()
}],
function_call={"name": "save_user"}
)
user_data = json.loads(response.choices[0].message.function_call.arguments)
# Validation Pydantic (lève exception si invalide)
user = User(**user_data)
return user
except ValueError as e:
# Données invalides
logging.error(f"Validation error: {e}")
raise
# Test
text = "Je m'appelle jean dupont, mon email est [email protected], j'ai 25 ans, inscrit le 2025-01-15"
try:
user = extract_user_safe(text)
print(f"✅ Utilisateur validé: {user.name} ({user.email})")
except ValueError as e:
print(f"❌ Erreur de validation: {e}")
Function Calling pour extraction
Le function calling est la méthode la plus robuste pour garantir une structure de sortie.
Pourquoi function calling ?
✅ Structure garantie : Le modèle DOIT suivre le schéma
✅ Validation automatique : Types vérifiés côté modèle
✅ Pydantic-friendly : Compatible avec vos modèles de données
✅ Meilleure précision : Le modèle comprend mieux la structure attendue
Exemple complet : Extraction de contrats
from pydantic import BaseModel, Field
from typing import List, Optional
from datetime import date
class ContractParty(BaseModel):
"""Partie d'un contrat"""
name: str
role: str # "client", "fournisseur", "partenaire"
address: Optional[str] = None
company_id: Optional[str] = None # SIRET, etc.
class ContractClause(BaseModel):
"""Clause contractuelle"""
title: str
content: str
category: str # "paiement", "confidentialité", "résiliation", etc.
is_critical: bool = False
class Contract(BaseModel):
"""Contrat structuré"""
contract_number: Optional[str] = None
contract_type: str # "service", "achat", "partenariat", etc.
signature_date: Optional[date] = None
effective_date: Optional[date] = None
end_date: Optional[date] = None
# Parties
parties: List[ContractParty]
# Financier
total_amount: Optional[float] = None
currency: str = "EUR"
payment_terms: Optional[str] = None
# Clauses importantes
key_clauses: List[ContractClause]
# Conditions
renewal_terms: Optional[str] = None
termination_notice_days: Optional[int] = None
# Résumé
executive_summary: str
def extract_contract(contract_text: str) -> Contract:
"""
Extraire toutes les informations d'un contrat
Args:
contract_text: Texte du contrat (PDF → texte via OCR)
Returns:
Contract structuré avec toutes les infos
"""
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{
"role": "system",
"content": """Tu es un expert juridique spécialisé dans l'analyse de contrats.
Extrais TOUTES les informations du contrat de manière structurée.
Pour les clauses :
- Identifie les 5-10 clauses LES PLUS IMPORTANTES
- is_critical = true si : montants élevés, confidentialité, pénalités, résiliation
Pour le résumé exécutif :
- 2-3 phrases décrivant l'essence du contrat
- Qui fait quoi, pour combien, jusqu'à quand
Sois exhaustif et précis."""
},
{
"role": "user",
"content": f"Contrat à analyser:\n\n{contract_text}"
}
],
functions=[{
"name": "save_contract",
"description": "Sauvegarder les données d'un contrat",
"parameters": Contract.model_json_schema()
}],
function_call={"name": "save_contract"},
temperature=0
)
function_args = json.loads(
response.choices[0].message.function_call.arguments
)
# Validation Pydantic
contract = Contract(**function_args)
return contract
# Exemple de contrat
contract_text = """
CONTRAT DE PRESTATION DE SERVICES N° 2025-SVC-042
Entre les soussignés :
TECHCORP SOLUTIONS SAS
Siège social : 123 Avenue des Champs-Élysées, 75008 Paris
SIRET : 123 456 789 00012
Représentée par M. Jean MARTIN, Directeur Général
Ci-après dénommée "le Prestataire"
D'une part,
Et :
ENTREPRISE DUPONT SARL
Siège social : 45 Rue de la Paix, 69001 Lyon
SIRET : 987 654 321 00034
Représentée par Mme Sophie DUPONT, Gérante
Ci-après dénommée "le Client"
D'autre part,
IL A ÉTÉ CONVENU CE QUI SUIT :
ARTICLE 1 - OBJET DU CONTRAT
Le Prestataire s'engage à fournir au Client des services de développement
et maintenance d'une application web sur mesure, selon les spécifications
détaillées en Annexe A.
ARTICLE 2 - DURÉE
Le présent contrat prend effet le 1er février 2025 et est conclu pour
une durée de 24 mois, soit jusqu'au 31 janvier 2027.
Sauf dénonciation par l'une des parties avec un préavis de 3 mois avant
l'échéance, le contrat sera renouvelé par tacite reconduction pour des
périodes successives de 12 mois.
ARTICLE 3 - CONDITIONS FINANCIÈRES
Le montant total du contrat est fixé à DEUX CENT MILLE EUROS (200 000 €) HT.
Modalités de paiement :
- 30% à la signature (60 000 €) - échéance 15/02/2025
- 40% à la livraison de la V1 (80 000 €) - échéance prévue 30/06/2025
- 30% à la recette finale (60 000 €) - échéance prévue 30/09/2025
Délai de paiement : 30 jours à réception de facture.
En cas de retard de paiement : pénalités de 3x le taux légal + indemnité
forfaitaire de 40 € pour frais de recouvrement.
ARTICLE 4 - CONFIDENTIALITÉ
Les parties s'engagent à garder strictement confidentielles toutes les
informations échangées dans le cadre du présent contrat, pendant sa durée
et pendant 5 ans après sa fin.
Toute divulgation non autorisée entraînera des pénalités de 50 000 € par
incident, sans préjudice d'autres recours.
ARTICLE 5 - PROPRIÉTÉ INTELLECTUELLE
L'ensemble des développements réalisés dans le cadre de ce contrat seront
la propriété exclusive du Client dès paiement intégral.
ARTICLE 6 - RÉSILIATION
Chaque partie peut résilier le contrat en cas de manquement grave de
l'autre partie, après mise en demeure restée sans effet pendant 30 jours.
Le Client peut également résilier de plein droit avec un préavis de 2 mois
moyennant une indemnité de 20% du solde restant dû.
ARTICLE 7 - MAINTENANCE
Une période de maintenance corrective gratuite de 6 mois est incluse
après la recette finale.
Fait à Paris, le 15 janvier 2025, en deux exemplaires originaux.
Pour TECHCORP SOLUTIONS Pour ENTREPRISE DUPONT
Jean MARTIN Sophie DUPONT
"""
contract = extract_contract(contract_text)
# Affichage structuré
print(f"📄 CONTRAT #{contract.contract_number}")
print(f"Type: {contract.contract_type}")
print(f"Dates: {contract.signature_date} → {contract.end_date}")
print(f"Montant: {contract.total_amount:,.0f} {contract.currency}\n")
print("PARTIES:")
for party in contract.parties:
print(f" • {party.name} ({party.role})")
if party.company_id:
print(f" SIRET: {party.company_id}")
print(f"\nRÉSUMÉ EXÉCUTIF:")
print(f" {contract.executive_summary}\n")
print(f"CLAUSES CRITIQUES:")
for clause in contract.key_clauses:
if clause.is_critical:
print(f" 🔴 {clause.title}")
print(f" Catégorie: {clause.category}")
print(f" {clause.content[:100]}...\n")
print(f"CONDITIONS:")
print(f" • Paiement: {contract.payment_terms}")
print(f" • Préavis de résiliation: {contract.termination_notice_days} jours")
print(f" • Renouvellement: {contract.renewal_terms}")
# Sauvegarder pour due diligence
contract_json = contract.model_dump_json(indent=2, exclude_none=True)
with open(f"contract_{contract.contract_number}.json", "w") as f:
f.write(contract_json)
# Alertes automatiques
alerts = []
if contract.total_amount and contract.total_amount > 100_000:
alerts.append(f"⚠️ Contrat de montant élevé : {contract.total_amount:,.0f} {contract.currency}")
if contract.end_date:
days_until_end = (contract.end_date - date.today()).days
if 0 < days_until_end < 90:
alerts.append(f"⚠️ Fin du contrat dans {days_until_end} jours")
for clause in contract.key_clauses:
if clause.is_critical and "pénalité" in clause.content.lower():
alerts.append(f"⚠️ Clause de pénalités : {clause.title}")
if alerts:
print("\n🚨 ALERTES:")
for alert in alerts:
print(f" {alert}")
Validation et vérification
L’extraction n’est jamais 100% fiable. Voici comment valider et gérer les erreurs.
Stratégie de validation en couches
from typing import Tuple
import logging
class ExtractionResult(BaseModel):
"""Résultat d'extraction avec métadonnées"""
data: dict
confidence: float # 0-1
validation_errors: List[str] = []
needs_human_review: bool = False
def extract_with_validation(
text: str,
schema: type[BaseModel],
confidence_threshold: float = 0.7
) -> Tuple[BaseModel, ExtractionResult]:
"""
Extraction avec validation multi-niveaux
Niveaux de validation :
1. Validation structurelle (Pydantic)
2. Validation sémantique (règles métier)
3. Validation de confiance (score LLM)
4. Validation cross-field (cohérence)
"""
# 1. Extraction initiale
try:
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{
"role": "system",
"content": """Extrais les données ET fournis un score de confiance (0-1).
Retourne :
{
"data": {...}, // Les données extraites
"confidence": 0.XX, // Ta confiance globale
"uncertain_fields": ["field1", ...] // Champs peu sûrs
}"""
},
{"role": "user", "content": text}
],
response_format={"type": "json_object"},
temperature=0
)
result = json.loads(response.choices[0].message.content)
except Exception as e:
logging.error(f"Extraction failed: {e}")
raise
# 2. Validation structurelle (Pydantic)
validation_errors = []
try:
extracted_data = schema(**result["data"])
except ValueError as e:
validation_errors.append(f"Structure invalide: {e}")
# Tenter de récupérer avec valeurs par défaut
extracted_data = schema.construct(**result["data"])
# 3. Validation sémantique (règles métier)
semantic_errors = validate_business_rules(extracted_data)
validation_errors.extend(semantic_errors)
# 4. Validation de confiance
confidence = result.get("confidence", 0)
needs_review = confidence < confidence_threshold or len(validation_errors) > 0
# 5. Validation cross-field
cross_errors = validate_field_coherence(extracted_data)
validation_errors.extend(cross_errors)
extraction_result = ExtractionResult(
data=result["data"],
confidence=confidence,
validation_errors=validation_errors,
needs_human_review=needs_review
)
return extracted_data, extraction_result
def validate_business_rules(data: BaseModel) -> List[str]:
"""Règles métier spécifiques"""
errors = []
# Exemple pour une facture
if hasattr(data, 'invoice_date') and hasattr(data, 'due_date'):
if data.due_date and data.invoice_date:
if data.due_date < data.invoice_date:
errors.append("Date d'échéance antérieure à date de facture")
if hasattr(data, 'total_amount') and hasattr(data, 'subtotal'):
if data.total_amount and data.subtotal:
if data.total_amount < data.subtotal:
errors.append("Total inférieur au sous-total")
return errors
def validate_field_coherence(data: BaseModel) -> List[str]:
"""Cohérence entre champs"""
errors = []
# Exemple : Somme des lignes doit correspondre au sous-total
if hasattr(data, 'line_items') and hasattr(data, 'subtotal'):
if data.line_items and data.subtotal:
calculated_total = sum(item.total for item in data.line_items)
if abs(calculated_total - data.subtotal) > 0.01: # Tolérance
errors.append(
f"Incohérence: somme lignes ({calculated_total}) "
f"≠ sous-total ({data.subtotal})"
)
return errors
# Utilisation
invoice_text = "..."
invoice, result = extract_with_validation(invoice_text, Invoice, confidence_threshold=0.8)
if result.needs_human_review:
print("⚠️ REVIEW HUMAINE NÉCESSAIRE")
print(f"Confiance: {result.confidence:.0%}")
if result.validation_errors:
print("Erreurs détectées:")
for error in result.validation_errors:
print(f" • {error}")
# Envoyer dans une queue de review
send_to_human_review_queue(invoice, result)
else:
print("✅ Validation OK, traitement automatique")
process_invoice_automatically(invoice)
Retry avec clarification
Si l’extraction échoue, demander au LLM de clarifier :
def extract_with_retry(
text: str,
schema: type[BaseModel],
max_retries: int = 2
) -> BaseModel:
"""Extraction avec retry intelligent"""
for attempt in range(max_retries + 1):
try:
result, validation = extract_with_validation(text, schema)
if not validation.needs_human_review:
return result # Succès !
if attempt < max_retries:
# Retry avec feedback sur les erreurs
feedback = "\n".join(validation.validation_errors)
clarification_prompt = f"""
L'extraction précédente a échoué avec ces erreurs :
{feedback}
Réessaye l'extraction en faisant particulièrement attention à :
- La cohérence des montants
- Les formats de dates (YYYY-MM-DD)
- La complétude des informations obligatoires
Texte original :
{text}
"""
text = clarification_prompt # Retry avec contexte
logging.info(f"Retry {attempt + 1}/{max_retries}")
except Exception as e:
if attempt == max_retries:
raise
logging.warning(f"Attempt {attempt + 1} failed: {e}")
# Échec après tous les retries
raise ValueError(f"Extraction failed after {max_retries} retries")
Batch processing à grande échelle
Pour traiter des milliers de documents efficacement.
Architecture de batch processing
import asyncio
from concurrent.futures import ThreadPoolExecutor
from typing import List
import time
class BatchProcessor:
"""Processeur batch optimisé"""
def __init__(
self,
model: str = "gpt-4-turbo",
max_concurrent: int = 10,
rate_limit_rpm: int = 500 # Requêtes par minute
):
self.model = model
self.max_concurrent = max_concurrent
self.rate_limit_rpm = rate_limit_rpm
self.requests_this_minute = 0
self.minute_start = time.time()
async def process_batch(
self,
texts: List[str],
extraction_func: callable
) -> List[dict]:
"""
Traiter un batch avec rate limiting
Args:
texts: Liste de textes à traiter
extraction_func: Fonction d'extraction async
Returns:
Liste de résultats
"""
results = []
# Découper en chunks pour respecter rate limit
chunk_size = min(self.max_concurrent, self.rate_limit_rpm // 60)
for i in range(0, len(texts), chunk_size):
chunk = texts[i:i + chunk_size]
# Attendre si on dépasse le rate limit
await self._wait_for_rate_limit(len(chunk))
# Traiter le chunk en parallèle
chunk_results = await asyncio.gather(
*[extraction_func(text) for text in chunk],
return_exceptions=True
)
# Gérer les erreurs
for j, result in enumerate(chunk_results):
if isinstance(result, Exception):
logging.error(f"Error processing item {i+j}: {result}")
results.append({"error": str(result), "text_index": i+j})
else:
results.append(result)
print(f"Processed {min(i + chunk_size, len(texts))}/{len(texts)}")
return results
async def _wait_for_rate_limit(self, requests_count: int):
"""Attendre si nécessaire pour respecter le rate limit"""
now = time.time()
elapsed = now - self.minute_start
if elapsed < 60:
# Toujours dans la même minute
if self.requests_this_minute + requests_count > self.rate_limit_rpm:
wait_time = 60 - elapsed
print(f"⏳ Rate limit: attente de {wait_time:.1f}s")
await asyncio.sleep(wait_time)
self.minute_start = time.time()
self.requests_this_minute = 0
else:
# Nouvelle minute
self.minute_start = now
self.requests_this_minute = 0
self.requests_this_minute += requests_count
# Fonction d'extraction async
async def extract_invoice_async(text: str) -> dict:
"""Version async de l'extraction"""
loop = asyncio.get_event_loop()
return await loop.run_in_executor(
None,
lambda: extract_invoice(text).model_dump()
)
# Utilisation
async def main():
# Charger 1000 factures
invoices_texts = load_invoices_from_folder("./invoices/") # 1000 PDFs
processor = BatchProcessor(
model="gpt-4-turbo",
max_concurrent=20,
rate_limit_rpm=500
)
print(f"📦 Traitement de {len(invoices_texts)} factures...")
start_time = time.time()
results = await processor.process_batch(
invoices_texts,
extract_invoice_async
)
elapsed = time.time() - start_time
# Statistiques
successful = [r for r in results if "error" not in r]
failed = [r for r in results if "error" in r]
print(f"\n✅ Terminé en {elapsed/60:.1f} minutes")
print(f" Succès: {len(successful)} ({len(successful)/len(results)*100:.1f}%)")
print(f" Échecs: {len(failed)}")
if failed:
print("\n❌ Échecs:")
for failure in failed[:10]: # Top 10
print(f" Index {failure['text_index']}: {failure['error']}")
# Sauvegarder résultats
save_results_to_database(successful)
return results
# Run
if __name__ == "__main__":
results = asyncio.run(main())
Optimisations de coûts pour batch
# 1. Utiliser des modèles plus petits quand possible
def choose_model_by_complexity(text: str) -> str:
"""Choisir le bon modèle selon la complexité"""
# Texte court et structure simple → modèle petit
if len(text) < 500 and is_simple_structure(text):
return "gpt-3.5-turbo" # 10× moins cher
# Texte moyen → turbo
elif len(text) < 2000:
return "gpt-4-turbo"
# Texte long ou complexe → model complet
else:
return "gpt-4"
# 2. Cache pour documents similaires
from functools import lru_cache
import hashlib
@lru_cache(maxsize=1000)
def extract_cached(text_hash: str, text: str) -> dict:
"""Cache les extractions de documents identiques"""
return extract_invoice(text).model_dump()
def extract_with_cache(text: str) -> dict:
text_hash = hashlib.md5(text.encode()).hexdigest()
return extract_cached(text_hash, text)
# 3. Batch API d'OpenAI (moins cher, asynchrone)
def submit_batch_job(texts: List[str]) -> str:
"""
Soumettre un batch job OpenAI
Avantages :
- 50% moins cher que API standard
- Traitement async (résultats sous 24h)
Use case : traitement de nuit de milliers de documents
"""
# Préparer le fichier JSONL
batch_requests = []
for i, text in enumerate(texts):
batch_requests.append({
"custom_id": f"request-{i}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4-turbo",
"messages": [
{"role": "system", "content": "Extract invoice data..."},
{"role": "user", "content": text}
],
"response_format": {"type": "json_object"}
}
})
# Sauvegarder en JSONL
with open("batch_input.jsonl", "w") as f:
for req in batch_requests:
f.write(json.dumps(req) + "\n")
# Upload et soumettre
batch_file = client.files.create(
file=open("batch_input.jsonl", "rb"),
purpose="batch"
)
batch_job = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
print(f"📦 Batch job soumis: {batch_job.id}")
print(f" Statut: {batch_job.status}")
return batch_job.id
# Récupérer les résultats plus tard
def get_batch_results(batch_id: str) -> List[dict]:
"""Récupérer résultats d'un batch job"""
batch = client.batches.retrieve(batch_id)
if batch.status != "completed":
print(f"⏳ Batch en cours: {batch.status}")
return []
# Télécharger résultats
result_file = client.files.content(batch.output_file_id)
results = []
for line in result_file.text.split("\n"):
if line.strip():
results.append(json.loads(line))
return results
Use cases réels
Automatisation comptable
Problème : Traiter 500 factures/mois manuellement (2h/jour)
Solution :
# Pipeline complet
def accounting_automation_pipeline(pdf_path: str):
"""Pipeline facture PDF → comptabilité"""
# 1. OCR du PDF
text = ocr_pdf(pdf_path) # Tesseract ou AWS Textract
# 2. Extraction structurée
invoice = extract_invoice(text)
# 3. Validation
if invoice.total_amount > 10000:
# Validation humaine pour montants élevés
send_for_approval(invoice)
return
# 4. Matching avec bons de commande
matching_po = find_matching_purchase_order(
supplier=invoice.supplier_name,
amount=invoice.total_amount
)
if matching_po and abs(matching_po.amount - invoice.total_amount) < 10:
# Match OK → traitement auto
create_accounting_entry(invoice)
update_purchase_order_status(matching_po.id, "invoiced")
trigger_payment_workflow(invoice)
else:
# Pas de match → alerte
send_alert_to_accounting(invoice, "No matching PO found")
Résultats :
- ⏱️ Temps de traitement : 2h/jour → 15min/jour
- 💰 Économie : 8 ETP évités
- ✅ Précision : 97% (vs 94% manuel - erreurs de saisie)
Tri automatique de tickets support
Problème : 1000 tickets/jour à router manuellement
Solution :
def support_ticket_triage(ticket_text: str, ticket_metadata: dict):
"""Triage intelligent de tickets"""
# 1. Classification + sentiment
classification = classify_support_ticket(ticket_text)
sentiment = analyze_sentiment(ticket_text)
# 2. Extraction d'infos clés
entities = extract_entities(ticket_text)
# 3. Scoring de priorité
priority_score = calculate_priority(
category=classification["category"],
sentiment=sentiment.overall_sentiment,
urgency=sentiment.urgency_level,
customer_tier=ticket_metadata.get("customer_tier")
)
# 4. Routage intelligent
if priority_score > 8:
# Urgent → Senior support + notification manager
assign_to_team("senior_support")
notify_manager(ticket_metadata["ticket_id"])
elif classification["category"] == "bug" and classification["confidence"] > 0.9:
# Bug confirmé → Engineering
assign_to_team("engineering")
create_jira_ticket(ticket_text, entities)
elif classification["category"] == "question":
# Question → Chatbot first, puis junior support
chatbot_response = try_chatbot_response(ticket_text)
if chatbot_response["confidence"] > 0.8:
send_automated_response(ticket_metadata["ticket_id"], chatbot_response)
else:
assign_to_team("junior_support")
# 5. Enrichissement automatique
update_ticket(ticket_metadata["ticket_id"], {
"category": classification["category"],
"priority": priority_score,
"sentiment": sentiment.overall_sentiment.value,
"extracted_info": entities
})
Résultats :
- 📊 Temps de première réponse : -60%
- 🎯 Précision de routage : 92%
- 😊 Satisfaction client : +15%
Analyse de CVs à grande échelle
Problème : Recruter 50 postes, 2000 CVs reçus
Solution :
async def cv_screening_pipeline(cv_pdfs: List[str], job_requirements: dict):
"""Screening automatique de CVs"""
# 1. OCR parallèle
cv_texts = await asyncio.gather(*[ocr_pdf_async(pdf) for pdf in cv_pdfs])
# 2. Extraction structurée
resumes = []
for text in cv_texts:
resume = extract_resume(text)
resumes.append(resume)
# 3. Scoring vs requirements
scored_candidates = []
for resume in resumes:
score = calculate_fit_score(resume, job_requirements)
scored_candidates.append({
"resume": resume,
"score": score["total"],
"skill_match": score["skills"],
"experience_match": score["experience"],
"education_match": score["education"]
})
# 4. Ranking
scored_candidates.sort(key=lambda x: x["score"], reverse=True)
# 5. Shortlist automatique
shortlist = scored_candidates[:50] # Top 50
# 6. Génération de rapports
for candidate in shortlist:
generate_candidate_report(candidate)
return shortlist
def calculate_fit_score(resume: Resume, requirements: dict) -> dict:
"""Scorer un CV vs exigences du poste"""
# Compétences techniques (40% du score)
required_skills = set(requirements["technical_skills"])
candidate_skills = set(resume.technical_skills)
skill_match = len(required_skills & candidate_skills) / len(required_skills)
# Expérience (40%)
years_experience = sum(
(datetime.strptime(exp.end_date or "9999-12-31", "%Y-%m-%d") -
datetime.strptime(exp.start_date, "%Y-%m-%d")).days / 365
for exp in resume.experiences
)
experience_match = min(years_experience / requirements["min_years_experience"], 1.0)
# Formation (20%)
education_match = 1.0 if any(
edu.degree in requirements["required_degrees"]
for edu in resume.education
) else 0.5
total = (
skill_match * 0.4 +
experience_match * 0.4 +
education_match * 0.2
) * 100
return {
"total": total,
"skills": skill_match * 100,
"experience": experience_match * 100,
"education": education_match * 100
}
Résultats :
- ⏱️ Temps de screening : 80h → 2h
- 🎯 Qualité des shortlists : Identique aux RH humains
- 💰 Coût : ~50€ pour 2000 CVs (vs 80h RH)
Coûts et optimisation
Calcul des coûts
def estimate_extraction_cost(
num_documents: int,
avg_tokens_per_doc: int = 1000,
model: str = "gpt-4-turbo"
) -> dict:
"""Estimer le coût d'extraction"""
# Prix par 1M tokens (input) - Janvier 2025
prices = {
"gpt-4-turbo": 0.01, # $0.01/1K tokens in
"gpt-4": 0.03,
"gpt-3.5-turbo": 0.0005,
"claude-3-5-sonnet": 0.003
}
price_per_1k = prices.get(model, 0.01)
total_tokens = num_documents * avg_tokens_per_doc
total_cost = (total_tokens / 1000) * price_per_1k
return {
"total_documents": num_documents,
"total_tokens": total_tokens,
"cost_usd": total_cost,
"cost_eur": total_cost * 0.92, # Approximatif
"cost_per_document": total_cost / num_documents
}
# Exemples
print("📊 ESTIMATION DE COÛTS\n")
# Factures
cost = estimate_extraction_cost(500, avg_tokens_per_doc=800, model="gpt-4-turbo")
print(f"500 factures (GPT-4 Turbo):")
print(f" • Coût total: {cost['cost_eur']:.2f}€")
print(f" • Par document: {cost['cost_per_document']*100:.2f} centimes\n")
# Tickets support
cost = estimate_extraction_cost(10000, avg_tokens_per_doc=200, model="gpt-3.5-turbo")
print(f"10K tickets support (GPT-3.5):")
print(f" • Coût total: {cost['cost_eur']:.2f}€")
print(f" • Par ticket: {cost['cost_per_document']*100:.4f} centimes\n")
# CVs
cost = estimate_extraction_cost(2000, avg_tokens_per_doc=1500, model="gpt-4-turbo")
print(f"2000 CVs (GPT-4 Turbo):")
print(f" • Coût total: {cost['cost_eur']:.2f}€")
print(f" • Par CV: {cost['cost_per_document']*100:.1f} centimes")
Sortie :
📊 ESTIMATION DE COÛTS
500 factures (GPT-4 Turbo):
• Coût total: 3.68€
• Par document: 0.74 centimes
10K tickets support (GPT-3.5):
• Coût total: 0.92€
• Par ticket: 0.0092 centimes
2000 CVs (GPT-4 Turbo):
• Coût total: 27.60€
• Par CV: 1.4 centimes
Optimisations de coûts
# 1. Compression de prompts
def optimize_prompt(text: str, max_tokens: int = 2000) -> str:
"""Réduire la taille du prompt sans perdre d'info"""
if len(text.split()) <= max_tokens:
return text
# Supprimer formatting inutile
text = re.sub(r'\n{3,}', '\n\n', text) # Max 2 newlines
text = re.sub(r' {2,}', ' ', text) # Max 1 space
# Si encore trop long, résumer
if len(text.split()) > max_tokens:
summary = generate_summary(text, max_length=max_tokens)
return summary
return text
# 2. Extraction incrémentale
def incremental_extraction(text: str) -> dict:
"""
Extraire en plusieurs passes avec modèles différents
1. Passe rapide (GPT-3.5) : structure de base
2. Passe détaillée (GPT-4) : seulement si nécessaire
"""
# Passe 1 : extraction basique (cheap)
basic_extraction = extract_with_model(text, model="gpt-3.5-turbo")
# Si confiance suffisante, on s'arrête là
if basic_extraction.confidence > 0.9:
return basic_extraction.data
# Sinon, raffiner avec GPT-4 (expensive)
refined = extract_with_model(
text,
model="gpt-4-turbo",
context={"previous_attempt": basic_extraction.data}
)
return refined.data
# 3. Caching intelligent
class SmartCache:
"""Cache avec similarity matching"""
def __init__(self):
self.cache = {}
self.embeddings_cache = {}
def get_similar(self, text: str, similarity_threshold: float = 0.95) -> Optional[dict]:
"""Trouver une extraction similaire en cache"""
# Embedder le texte
embedding = get_embedding(text)
# Chercher le plus similaire
for cached_text, cached_result in self.cache.items():
cached_embedding = self.embeddings_cache.get(cached_text)
if cached_embedding is None:
continue
similarity = cosine_similarity(embedding, cached_embedding)
if similarity > similarity_threshold:
return cached_result # Cache hit !
return None # Cache miss
def set(self, text: str, result: dict):
"""Ajouter au cache"""
self.cache[text] = result
self.embeddings_cache[text] = get_embedding(text)
Conclusion
L’extraction d’informations avec LLMs est l’un des cas d’usage les plus pragmatiques et rentables de l’IA générative en entreprise.
Points clés à retenir
✅ Zero-shot ou few-shot : Pas besoin de milliers d’exemples étiquetés
✅ JSON Mode + Function Calling : Garantit la structure de sortie
✅ Validation multi-niveaux : Structurelle, sémantique, business rules
✅ Batch processing : Traiter des milliers de documents efficacement
✅ ROI rapide : Coûts très faibles (centimes par document) vs économies de temps massives
Quand utiliser l’extraction LLM ?
| Critère | Extraction LLM | Alternatives |
|---|---|---|
| Volume | <1M documents/mois | >1M → modèles fine-tunés |
| Variété | Documents hétérogènes | Documents très standardisés → règles |
| Évolution | Formats qui changent souvent | Formats figés → regex/parsers |
| Précision requise | 90-98% suffisant | >99% requis → ML classique + validation |
| Temps de mise en œuvre | Jours-semaines | Mois-années |
Next steps
- Commencer petit : 100 documents test
- Valider la qualité : Review humaine sur échantillon
- Optimiser les coûts : Modèles adaptés, caching, batch
- Scaler progressivement : 100 → 1K → 10K documents
- Automatiser : Pipeline CI/CD pour extractions
Ressources et liens
Articles connexes
- Function Calling - Appeler des outils depuis les LLMs
- RAG - Récupération augmentée pour extraction contextuelle
- Prompt Engineering - Optimiser les prompts d’extraction
- Agents IA - Orchestrer plusieurs étapes d’extraction
- Bases de Données Vectorielles - Stocker et rechercher documents
Outils mentionnés
- LLMs : OpenAI GPT-4, Anthropic Claude, Google Gemini
- NER classique : spaCy, Hugging Face Transformers
- OCR : Tesseract, AWS Textract, Google Document AI
- Validation : Pydantic, JSON Schema
- Frameworks : LangChain, LlamaIndex