Weaviate : base vectorielle open source avec Hybrid Search
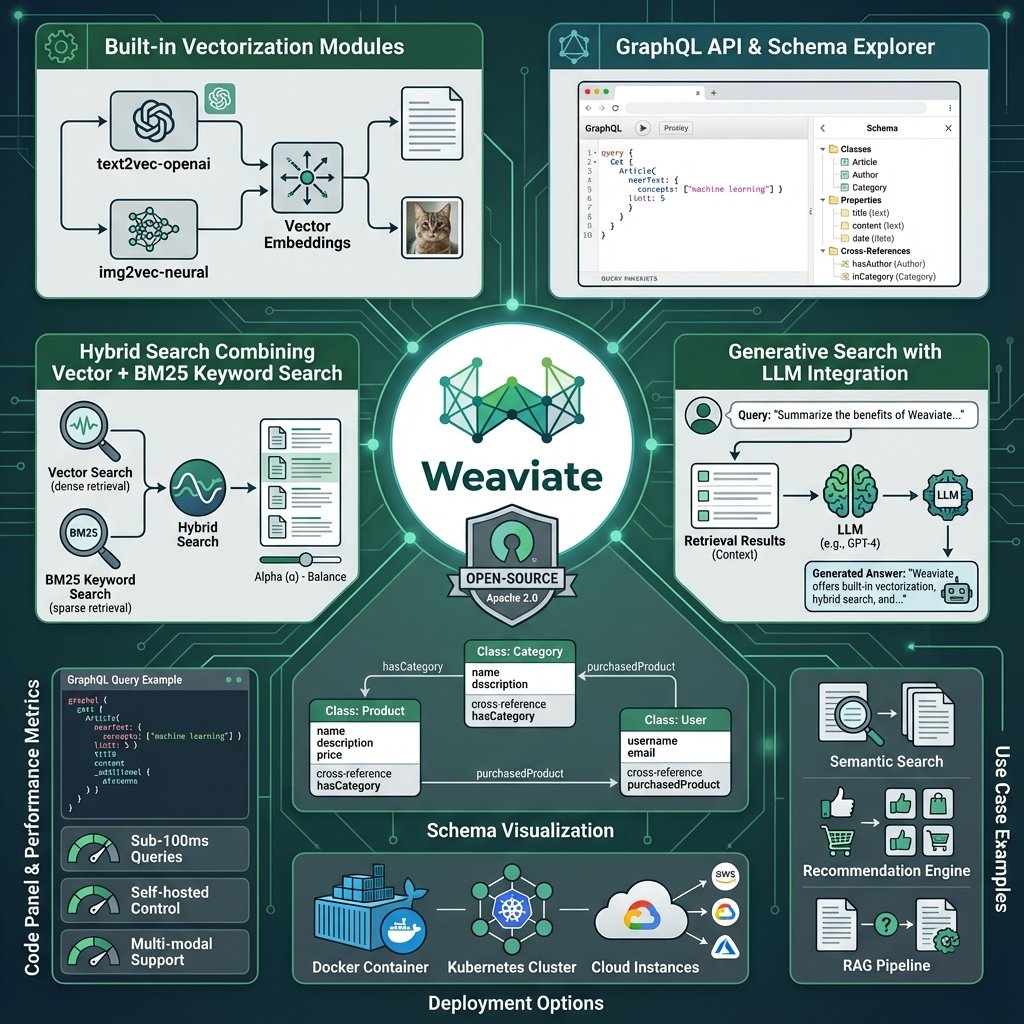
Weaviate est une base de données vectorielle open source qui se distingue par son hybrid search natif et ses modules de vectorisation automatique.
Alternative crédible à Pinecone, avec l’avantage d’être self-hostable tout en offrant aussi une option cloud managée.
Objectifs de l’article
Après avoir lu cet article, vous serez capable de :
- ✅ Installer Weaviate (Docker et Cloud)
- ✅ Créer des schémas et collections
- ✅ Utiliser les modules de vectorisation automatique
- ✅ Implémenter le hybrid search (vectoriel + BM25)
- ✅ Querier avec GraphQL et REST API
- ✅ Intégrer avec LangChain
- ✅ Choisir entre self-hosted et Weaviate Cloud
Présentation de Weaviate
Qu’est-ce que Weaviate ?
Weaviate (prononcé “wee-vee-eight”) est une base de données vectorielle open source créée en 2019.
Points forts :
- 🔍 Hybrid search natif : BM25 + vectoriel en un seul appel
- 🤖 Modules de vectorisation : Automatisation de l’embedding
- 📊 GraphQL : API puissante et flexible
- 🐳 Self-hosted : Docker, Kubernetes
- ☁️ Cloud option : Weaviate Cloud Services (WCS)
- 🔓 Open source : BSD-3 license
Avantages
- ✅ Hybrid search out-of-the-box (unique !)
- ✅ Vectorisation automatique (pas besoin d’embedder manuellement)
- ✅ GraphQL pour queries complexes
- ✅ Self-hosting possible (contrôle total, privacy)
- ✅ Performance excellente (HNSW)
- ✅ Multi-tenancy natif
Inconvénients
- ❌ Courbe d’apprentissage (GraphQL, schémas)
- ❌ Self-hosting = gestion infrastructure (vs Pinecone)
- ❌ Moins de documentation que Pinecone
Installation
Docker (Local/Self-Hosted)
Le plus simple pour commencer.
# docker-compose.yml
version: '3.8'
services:
weaviate:
image: semitechnologies/weaviate:latest
ports:
- "8080:8080"
environment:
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'text2vec-openai'
ENABLE_MODULES: 'text2vec-openai'
OPENAI_APIKEY: 'your-openai-key'
CLUSTER_HOSTNAME: 'node1'
volumes:
- weaviate_data:/var/lib/weaviate
volumes:
weaviate_data:
# Lancer
docker-compose up -d
# Vérifier
curl http://localhost:8080/v1/meta
Weaviate Cloud Services (WCS)
Cloud managé (gratuit pour commencer).
- Aller sur console.weaviate.cloud
- Créer un compte
- Créer un cluster (Sandbox gratuit : 5M vecteurs)
- Récupérer l’URL et API key
Installation Python client
pip install weaviate-client
Connexion
import weaviate
# Local (Docker)
client = weaviate.Client("http://localhost:8080")
# Cloud (WCS)
client = weaviate.Client(
url="https://your-cluster.weaviate.network",
auth_client_secret=weaviate.AuthApiKey(api_key="your-wcs-key")
)
# Vérifier connexion
print(client.is_ready()) # True
Schéma et collections
Weaviate utilise un schéma pour définir vos collections (classes).
Créer une Collection (Class)
# Définir le schéma
class_obj = {
"class": "Article",
"description": "Articles de blog",
"vectorizer": "text2vec-openai", # Module de vectorisation
"moduleConfig": {
"text2vec-openai": {
"model": "text-embedding-3-small",
"dimensions": 1536
}
},
"properties": [
{
"name": "title",
"dataType": ["text"],
"description": "Titre de l'article"
},
{
"name": "content",
"dataType": ["text"],
"description": "Contenu de l'article"
},
{
"name": "category",
"dataType": ["text"],
"description": "Catégorie"
},
{
"name": "views",
"dataType": ["int"],
"description": "Nombre de vues"
},
{
"name": "publishDate",
"dataType": ["date"],
"description": "Date de publication"
}
]
}
# Créer la classe
client.schema.create_class(class_obj)
print("Collection 'Article' créée !")
Voir le schéma
schema = client.schema.get()
print(schema)
Types de données
| DataType | Description | Exemple |
|---|---|---|
| text | Texte | “Hello world” |
| int | Entier | 42 |
| number | Flottant | 3.14 |
| boolean | Booléen | true, false |
| date | Date ISO 8601 | “2025-01-15T10:00:00Z” |
| uuid | UUID | “…” |
| text[] | Array de textes | [“tag1”, “tag2”] |
Modules de vectorisation automatique
Weaviate peut vectoriser automatiquement vos données avec des modules.
Modules disponibles
| Module | Provider | Dimensions | Coût |
|---|---|---|---|
| text2vec-openai | OpenAI | 1536, 3072 | Payant |
| text2vec-cohere | Cohere | 1024, 4096 | Payant |
| text2vec-huggingface | HF Inference API | Variable | Payant |
| text2vec-transformers | Local | Variable | Gratuit |
Configuration module
# Dans le schéma
"moduleConfig": {
"text2vec-openai": {
"model": "text-embedding-3-small",
"dimensions": 1536,
"modelVersion": "003",
"type": "text"
}
}
CRUD operations
Create (Insert)
# Ajouter un objet
# Weaviate génère automatiquement l'embedding du 'content' !
data_obj = {
"title": "Introduction aux bases vectorielles",
"content": "Les bases de données vectorielles sont essentielles pour l'IA moderne.",
"category": "tech",
"views": 1250,
"publishDate": "2025-01-15T10:00:00Z"
}
# Insérer
result = client.data_object.create(
data_object=data_obj,
class_name="Article"
)
print(f"ID créé : {result}")
Batch Insert
# Insertion par batch (performant)
client.batch.configure(batch_size=100)
with client.batch as batch:
for article in articles: # Liste d'articles
batch.add_data_object(
data_object=article,
class_name="Article"
)
print(f"{len(articles)} articles ajoutés")
Read (Get by ID)
# Récupérer par UUID
obj = client.data_object.get_by_id(
uuid="object-uuid-here",
class_name="Article"
)
print(obj)
Update
# Mettre à jour
client.data_object.update(
uuid="object-uuid-here",
class_name="Article",
data_object={
"views": 2000 # Nouveau nombre de vues
}
)
Delete
# Supprimer par ID
client.data_object.delete(
uuid="object-uuid-here",
class_name="Article"
)
# Supprimer par filtre (batch delete)
client.batch.delete_objects(
class_name="Article",
where={
"path": ["category"],
"operator": "Equal",
"valueText": "obsolete"
}
)
Query : Recherche Vectorielle
Recherche simple
# Recherche sémantique
result = (
client.query
.get("Article", ["title", "content", "category", "views"])
.with_near_text({"concepts": ["bases de données vectorielles"]})
.with_limit(3)
.do()
)
# Afficher résultats
for article in result['data']['Get']['Article']:
print(f"Titre : {article['title']}")
print(f"Catégorie : {article['category']}")
print()
Avec Distance/Certainty
# Avec score de similarité
result = (
client.query
.get("Article", ["title", "content"])
.with_near_text({"concepts": ["IA et machine learning"]})
.with_additional(["distance", "certainty"]) # Scores
.with_limit(5)
.do()
)
for article in result['data']['Get']['Article']:
print(f"{article['title']}")
print(f" Distance : {article['_additional']['distance']:.4f}")
print(f" Certainty : {article['_additional']['certainty']:.4f}")
Note :
- Distance : 0 = identique, plus grand = différent
- Certainty : 0-1, plus proche de 1 = plus similaire
Hybrid Search : le pouvoir de Weaviate
Le hybrid search combine :
- Recherche vectorielle (sémantique)
- BM25 (mots-clés, TF-IDF like)
Syntaxe
result = (
client.query
.get("Article", ["title", "content", "category"])
.with_hybrid(
query="bases de données vectorielles",
alpha=0.75 # 75% vectoriel, 25% BM25
)
.with_limit(5)
.do()
)
for article in result['data']['Get']['Article']:
print(f"- {article['title']}")
Paramètre alpha
| Alpha | Vectoriel | BM25 | Use Case |
|---|---|---|---|
| 0.0 | 0% | 100% | Pure keyword search |
| 0.25 | 25% | 75% | Keyword-heavy |
| 0.5 | 50% | 50% | Équilibré |
| 0.75 | 75% | 25% | Semantic-heavy (recommandé) |
| 1.0 | 100% | 0% | Pure semantic search |
Exemple : Query “Python programming” trouve :
- Sémantique : “Développement logiciel”, “Coder en Python”
- BM25 : Documents contenant exactement “Python” et “programming”
Exemple comparatif
# 1. Pure vectoriel (alpha=1.0)
result_vector = (
client.query
.get("Article", ["title"])
.with_hybrid(query="Python programming", alpha=1.0)
.with_limit(3)
.do()
)
# 2. Pure BM25 (alpha=0.0)
result_bm25 = (
client.query
.get("Article", ["title"])
.with_hybrid(query="Python programming", alpha=0.0)
.with_limit(3)
.do()
)
# 3. Hybrid (alpha=0.75)
result_hybrid = (
client.query
.get("Article", ["title"])
.with_hybrid(query="Python programming", alpha=0.75)
.with_limit(3)
.do()
)
print("Vectoriel :", [a['title'] for a in result_vector['data']['Get']['Article']])
print("BM25 :", [a['title'] for a in result_bm25['data']['Get']['Article']])
print("Hybrid :", [a['title'] for a in result_hybrid['data']['Get']['Article']])
Filtrage (Where)
Combiner recherche vectorielle + filtres.
Opérateurs
# Égalité
where_filter = {
"path": ["category"],
"operator": "Equal",
"valueText": "tech"
}
# Comparaison numérique
where_filter = {
"path": ["views"],
"operator": "GreaterThan",
"valueInt": 1000
}
# AND
where_filter = {
"operator": "And",
"operands": [
{"path": ["category"], "operator": "Equal", "valueText": "tech"},
{"path": ["views"], "operator": "GreaterThan", "valueInt": 1000}
]
}
# OR
where_filter = {
"operator": "Or",
"operands": [
{"path": ["category"], "operator": "Equal", "valueText": "tech"},
{"path": ["category"], "operator": "Equal", "valueText": "ai"}
]
}
Exemple complet
# Recherche : articles "IA" dans catégorie "tech" avec >1000 vues
result = (
client.query
.get("Article", ["title", "content", "category", "views"])
.with_near_text({"concepts": ["intelligence artificielle"]})
.with_where({
"operator": "And",
"operands": [
{"path": ["category"], "operator": "Equal", "valueText": "tech"},
{"path": ["views"], "operator": "GreaterThan", "valueInt": 1000}
]
})
.with_limit(5)
.do()
)
GraphQL : Queries avancées
Weaviate utilise GraphQL pour queries complexes.
Exemple GraphQL Brut
query = """
{
Get {
Article(
hybrid: {
query: "machine learning",
alpha: 0.75
}
where: {
path: ["category"],
operator: Equal,
valueText: "tech"
}
limit: 5
) {
title
content
category
views
_additional {
distance
certainty
}
}
}
}
"""
result = client.query.raw(query)
Aggregate queries
# Statistiques
result = (
client.query
.aggregate("Article")
.with_fields("meta { count }")
.with_group_by_filter(["category"])
.do()
)
print(result)
# Ex: {'tech': 150 articles, 'ai': 89 articles, ...}
Intégration LangChain
pip install langchain-weaviate
from langchain_weaviate import WeaviateVectorStore
from langchain.schema import Document
# Connexion
vectorstore = WeaviateVectorStore(
client=client,
index_name="Article",
text_key="content"
)
# Ajouter documents
docs = [
Document(
page_content="Les bases vectorielles sont essentielles.",
metadata={"title": "Intro bases vectorielles", "category": "tech"}
),
Document(
page_content="Weaviate offre hybrid search natif.",
metadata={"title": "Guide Weaviate", "category": "tech"}
)
]
vectorstore.add_documents(docs)
# Recherche
results = vectorstore.similarity_search("bases de données", k=2)
for doc in results:
print(f"- {doc.metadata['title']}")
Exemple RAG avec Hybrid Search
import weaviate
from openai import OpenAI
class WeaviateRAG:
"""RAG avec Weaviate hybrid search."""
def __init__(self, weaviate_url: str, openai_key: str):
self.weaviate = weaviate.Client(weaviate_url)
self.openai = OpenAI(api_key=openai_key)
def setup_schema(self):
"""Créer le schéma."""
class_obj = {
"class": "Document",
"vectorizer": "text2vec-openai",
"moduleConfig": {
"text2vec-openai": {
"model": "text-embedding-3-small"
}
},
"properties": [
{"name": "content", "dataType": ["text"]},
{"name": "title", "dataType": ["text"]},
{"name": "category", "dataType": ["text"]}
]
}
self.weaviate.schema.create_class(class_obj)
def index_documents(self, documents: list[dict]):
"""Indexer documents."""
with self.weaviate.batch as batch:
batch.batch_size = 100
for doc in documents:
batch.add_data_object(
data_object=doc,
class_name="Document"
)
print(f"{len(documents)} documents indexés")
def ask(self, question: str, alpha: float = 0.75, top_k: int = 3) -> str:
"""
Poser une question avec hybrid search.
Args:
question: Question
alpha: 0-1, poids vectoriel vs BM25
top_k: Nombre de documents
Returns:
Réponse générée
"""
# 1. Hybrid search
result = (
self.weaviate.query
.get("Document", ["content", "title"])
.with_hybrid(query=question, alpha=alpha)
.with_limit(top_k)
.do()
)
# 2. Construire contexte
docs = result['data']['Get']['Document']
context = "\n\n".join([
f"Document: {doc['title']}\n{doc['content']}"
for doc in docs
])
# 3. Générer avec LLM
response = self.openai.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "Réponds avec le contexte fourni."},
{"role": "user", "content": f"Contexte:\n{context}\n\nQuestion: {question}"}
]
)
return response.choices[0].message.content
# Utilisation
rag = WeaviateRAG("http://localhost:8080", "sk-...")
# Setup (une fois)
rag.setup_schema()
# Indexer
docs = [
{"content": "...", "title": "Doc 1", "category": "tech"},
{"content": "...", "title": "Doc 2", "category": "ai"}
]
rag.index_documents(docs)
# Poser question
answer = rag.ask("Qu'est-ce que le hybrid search ?", alpha=0.75)
print(answer)
Self-Hosted vs Weaviate Cloud
Self-Hosted (Docker/Kubernetes)
Avantages :
- ✅ Contrôle total
- ✅ Privacy (données ne quittent pas votre infra)
- ✅ Pas de limite de vecteurs
- ✅ Coût fixe (serveurs)
Inconvénients :
- ❌ Gestion infrastructure (DevOps)
- ❌ Scaling manuel
- ❌ Backups à gérer
Use case : Grandes entreprises, données sensibles, budget limité à long terme.
Weaviate Cloud Services (WCS)
Avantages :
- ✅ Managé (pas d’infra)
- ✅ Scaling automatique
- ✅ Backups automatiques
- ✅ Simple et rapide
Inconvénients :
- ❌ Coût (payant)
- ❌ Données dans le cloud
- ❌ Vendor lock-in partiel
Use case : Startups, MVP, pas d’équipe DevOps.
Pricing WCS (2025)
| Tier | Prix | Vecteurs | Use Case |
|---|---|---|---|
| Sandbox | Gratuit | 5M | Dev/test |
| Standard | $25+/mois | Illimité | Production |
| Enterprise | Custom | Illimité | Grande échelle |
Performance et scalabilité
Benchmarks
Dataset : 1M vecteurs, 768 dimensions
| Opération | Latence | Notes |
|---|---|---|
| Vectorielle | 5-10ms | HNSW |
| Hybrid | 8-15ms | Vectorielle + BM25 |
| Avec filtres | 10-20ms | Dépend du filtre |
| Batch insert | 1000 obj/s | Optimisé |
Scaling
Vertical : Augmenter RAM/CPU du serveur
Horizontal : Sharding et replication
# docker-compose.yml
CLUSTER_GOSSIP_BIND_PORT: '7100'
CLUSTER_DATA_BIND_PORT: '7101'
Best practices
✅ À faire
- Hybrid search par défaut (alpha=0.75)
.with_hybrid(query="...", alpha=0.75)
- Batch insert pour performance
with client.batch as batch:
...
- Choisir bon vectorizer selon use case
# OpenAI : Qualité
# Transformers local : Gratuit, privacy
- Filtres pour affiner résultats
.with_where(...)
❌ À éviter
Oublier les filtres : Combiner toujours sémantique + business logic
Alpha mal configuré : Tester 0.5, 0.75, 1.0 sur vos données
Pas de batch : Insert un par un = très lent
Conclusion
Weaviate est l’alternative open source idéale si vous voulez :
✅ Hybrid search natif (unique !)
✅ Self-hosting (contrôle, privacy)
✅ Vectorisation automatique (modules)
✅ GraphQL (queries puissantes)
✅ Open source (BSD-3)
Quand Utiliser Weaviate ?
- ✅ Besoin de hybrid search (vectoriel + BM25)
- ✅ Self-hosting souhaité (privacy, contrôle)
- ✅ Équipe avec compétences DevOps
- ✅ Budget limité long terme
Dans le prochain article, nous découvrirons Chroma, la base vectorielle la plus simple pour le développement local.
👉 Article 6 : Chroma - Base Vectorielle Locale Simple
Exercices pratiques
Setup Weaviate
Installez Weaviate avec Docker et créez votre premier schéma.
Hybrid Search
Comparez résultats avec alpha=0, 0.5, 1.0 sur vos données.
RAG complet
Créez un chatbot RAG avec hybrid search et LangChain.
Ressources complémentaires
Articles liés :
Documentation :