RAG avancé : techniques de pointe avec bases vectorielles | Guide complet
Le RAG basique (retrieval simple + LLM) fonctionne, mais peut être considérablement amélioré avec des techniques avancées.
Dans cet article final de la série, nous couvrons les techniques state-of-the-art qui améliorent la qualité de 30-50%+.
Objectifs de l’article
Après avoir lu cet article, vous serez capable de :
- ✅ Implémenter hybrid search (vectoriel + BM25)
- ✅ Utiliser le reranking pour améliorer précision
- ✅ Appliquer multi-query expansion
- ✅ Structurer avec parent-child chunks
- ✅ Générer avec HyDE (Hypothetical Documents)
- ✅ Créer des agents RAG autonomes
- ✅ Compresser contexte intelligemment
- ✅ Évaluer qualité avec RAGAS
Limites du RAG basique
RAG basique
def basic_rag(question: str):
# 1. Embedder question
query_embedding = embedding_model.encode(question)
# 2. Rechercher (top-3)
results = vectordb.search(query_embedding, top_k=3)
# 3. Contexte
context = "\n\n".join([r.text for r in results])
# 4. LLM
answer = llm.generate(f"Context: {context}\n\nQuestion: {question}")
return answer
Problèmes
- Single query = résultats potentiellement limités
- Pas de reranking = ordre sous-optimal
- Chunks fixes = perte de contexte
- Pas d’adaptation = même approche pour toutes questions
- Pas d’évaluation = qualité inconnue
RAG basique : Recall@10 ~60-70%, Answer quality ~70% RAG avancé : Recall@10 ~85-95%, Answer quality ~90%+
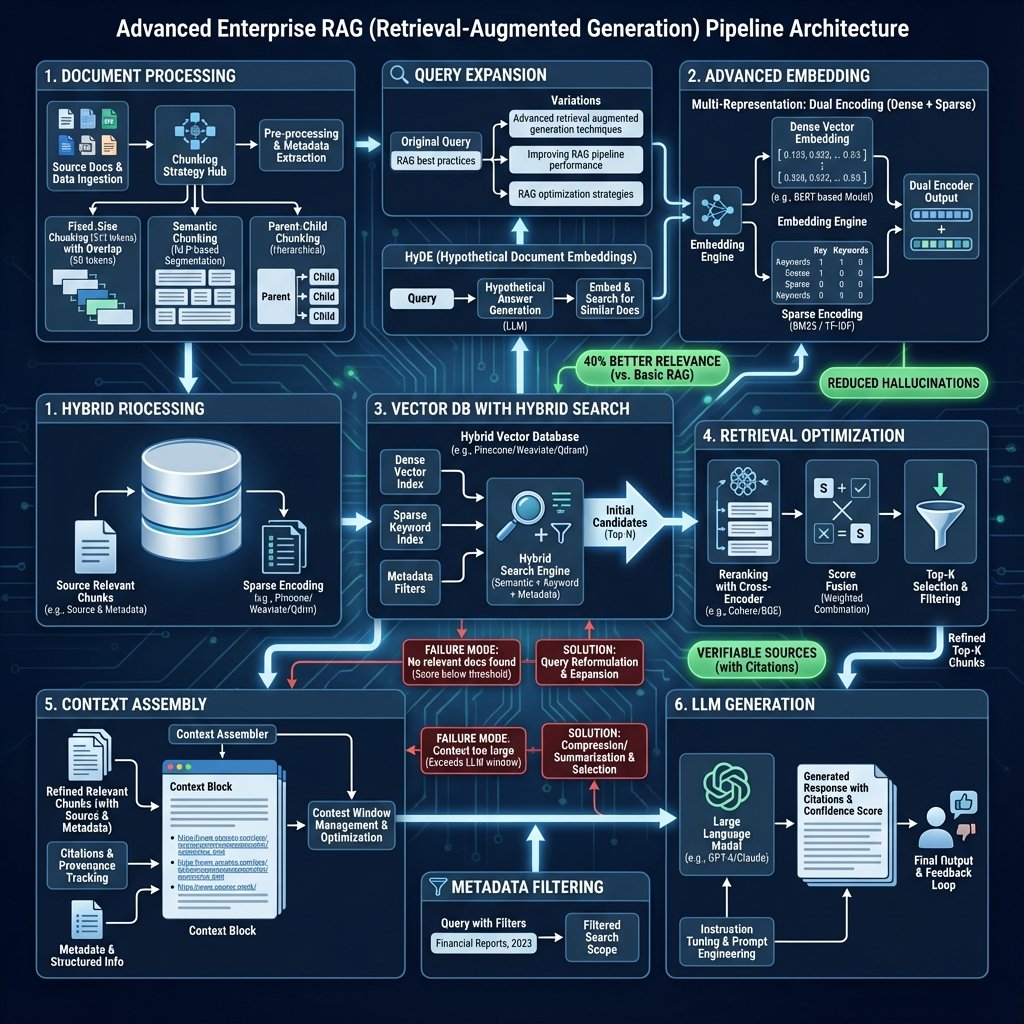
Hybrid Search : Vectoriel + BM25
Principe
Combiner recherche sémantique (dense) et mots-clés (sparse/BM25).
Dense (vectoriel) : Capture le sens
"automobile électrique" trouve "voiture électrique", "Tesla", "EV"
Sparse (BM25) : Mots exacts
"automobile électrique" trouve exactement ces mots
Implémentation avec Weaviate
import weaviate
client = weaviate.Client("http://localhost:8080")
def hybrid_search(query: str, alpha: float = 0.75, top_k: int = 5):
"""
Hybrid search.
Args:
query: Question
alpha: 0-1 (0=BM25 only, 1=vector only, 0.75=recommended)
top_k: Nombre résultats
"""
result = (
client.query
.get("Document", ["text", "title"])
.with_hybrid(query=query, alpha=alpha)
.with_limit(top_k)
.do()
)
docs = result['data']['Get']['Document']
return docs
# Utilisation
question = "Python programming for beginners"
# Pure vectoriel
results_vector = hybrid_search(question, alpha=1.0)
# Pure BM25
results_bm25 = hybrid_search(question, alpha=0.0)
# Hybrid (recommandé)
results_hybrid = hybrid_search(question, alpha=0.75)
Amélioration attendue
- Recall : +10-15%
- Précision : +5-10%
- Meilleur pour queries avec termes techniques spécifiques
Reranking : Cross-Encoder
Problème Bi-Encoder
Les embeddings (bi-encoder) encodent query et documents séparément.
Query → Embedding Q
Doc → Embedding D
Similarité = cosine(Q, D)
Limite : Pas d’interaction directe query-document.
Solution : Cross-Encoder
Le cross-encoder prend query + document ensemble.
[Query, Document] → Cross-Encoder → Score (0-1)
Implémentation avec Sentence-BERT
from sentence_transformers import CrossEncoder
# Charger cross-encoder
reranker = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
def rerank_results(query: str, documents: list[str], top_k: int = 3):
"""
Reranker documents avec cross-encoder.
Args:
query: Question
documents: Liste de documents récupérés
top_k: Nombre final de documents
Returns:
Documents rerankés (top_k meilleurs)
"""
# Préparer pairs (query, doc)
pairs = [[query, doc] for doc in documents]
# Scorer avec cross-encoder
scores = reranker.predict(pairs)
# Trier par score décroissant
doc_score_pairs = list(zip(documents, scores))
doc_score_pairs.sort(key=lambda x: x[1], reverse=True)
# Top-K
top_docs = [doc for doc, score in doc_score_pairs[:top_k]]
return top_docs
# Exemple
question = "How to install Python?"
# 1. Retrieval (top-10)
initial_results = vectordb.search(question, top_k=10)
docs = [r.text for r in initial_results]
# 2. Rerank (top-3)
reranked_docs = rerank_results(question, docs, top_k=3)
print("Après reranking:")
for i, doc in enumerate(reranked_docs, 1):
print(f"{i}. {doc[:100]}...")
Avec Cohere Rerank API
import cohere
co = cohere.Client(api_key="...")
def rerank_with_cohere(query: str, documents: list[str], top_k: int = 3):
"""Rerank avec Cohere API (meilleure qualité)."""
response = co.rerank(
query=query,
documents=documents,
top_n=top_k,
model='rerank-english-v2.0'
)
# Documents rerankés
reranked_docs = [documents[result.index] for result in response.results]
return reranked_docs
Amélioration attendue
- Précision : +15-25%
- Trade-off : +50-100ms latence
- Recommandé : Retrieve top-20, rerank top-3
3. Multi-Query Expansion
Principe
Générer N variantes de la query, récupérer pour chacune, combiner résultats.
Implémentation
from openai import OpenAI
openai = OpenAI(api_key="...")
def multi_query_expansion(question: str, n_variants: int = 3):
"""
Générer variantes de la question.
Args:
question: Question originale
n_variants: Nombre de variantes
Returns:
Liste de questions (originale + variantes)
"""
prompt = f"""Génère {n_variants} variantes de cette question en reformulant différemment.
Question originale: {question}
Variantes (une par ligne):"""
response = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0.7
)
# Parser variantes
variants_text = response.choices[0].message.content
variants = [q.strip() for q in variants_text.split('\n') if q.strip()]
# Retourner originale + variantes
all_queries = [question] + variants
return all_queries
def advanced_retrieval(question: str, top_k_per_query: int = 5, final_top_k: int = 3):
"""
Retrieval multi-query avec reranking.
Args:
question: Question
top_k_per_query: Docs par query
final_top_k: Docs finaux après reranking
"""
# 1. Multi-query expansion
queries = multi_query_expansion(question, n_variants=2)
print(f"Queries: {queries}")
# 2. Retrieve pour chaque query
all_docs = []
for query in queries:
results = vectordb.search(query, top_k=top_k_per_query)
all_docs.extend([r.text for r in results])
# 3. Dédupliquer
unique_docs = list(dict.fromkeys(all_docs)) # Préserve ordre
print(f"Documents uniques: {len(unique_docs)}")
# 4. Rerank
final_docs = rerank_results(question, unique_docs, top_k=final_top_k)
return final_docs
# Utilisation
question = "Comment installer Python sur Windows ?"
docs = advanced_retrieval(question)
Output :
Queries: [
'Comment installer Python sur Windows ?',
'Installation de Python sous Windows',
'Installer Python Windows étapes'
]
Documents uniques: 12
Docs finaux: 3
Amélioration attendue
- Recall : +15-30%
- Couvre plus de façons de formuler la question
- Trade-off : +200-500ms, coût LLM
Parent-Child Chunks
Problème
Chunk petit (200 tokens) : Bon pour retrieval, mais peu de contexte pour LLM
Chunk grand (1000 tokens) : Mauvais pour retrieval (bruit), bon pour LLM
Solution : hiérarchie
Parent Document (1000 tokens)
├─ Child Chunk 1 (200 tokens) ← Indexé pour retrieval
├─ Child Chunk 2 (200 tokens) ← Indexé pour retrieval
└─ Child Chunk 3 (200 tokens) ← Indexé pour retrieval
Process :
- Retrieve child chunks (précis)
- Return parent documents (contexte complet)
Implémentation
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema import Document
# Text splitters
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=50)
# Vectorstore (child chunks)
vectorstore = Chroma(
collection_name="child_chunks",
embedding_function=OpenAIEmbeddings()
)
# Document store (parent docs)
docstore = InMemoryStore()
# Retriever
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=docstore,
child_splitter=child_splitter,
parent_splitter=parent_splitter
)
# Ajouter documents
docs = [
Document(page_content="Long article about Python programming..."),
Document(page_content="Comprehensive guide to web development...")
]
retriever.add_documents(docs)
# Retrieval
# Recherche sur child chunks, retourne parent docs
results = retriever.get_relevant_documents("Python basics")
for doc in results:
print(f"Parent doc (len={len(doc.page_content)}): {doc.page_content[:100]}...")
Amélioration attendue
- Precision : +10-15%
- Context quality : +20-30%
HyDE (Hypothetical Document Embeddings)
Principe
Au lieu d’embedder la query, générer un document hypothétique qui répondrait à la query, et l’embedder.
Query: "Qu'est-ce que le RAG ?"
↓
LLM génère document hypothétique:
"Le RAG (Retrieval-Augmented Generation) est une technique..."
↓
Embedder ce document
↓
Rechercher documents similaires
Intuition : Documents réels ressemblent plus à des documents qu’à des queries.
Implémentation
from openai import OpenAI
openai = OpenAI(api_key="...")
def hyde_retrieval(question: str, top_k: int = 3):
"""
HyDE retrieval.
Args:
question: Question
top_k: Nombre de documents
Returns:
Documents récupérés
"""
# 1. Générer document hypothétique
prompt = f"""Écris un paragraphe qui répond à cette question de manière détaillée et précise:
Question: {question}
Réponse:"""
response = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=200
)
hypothetical_doc = response.choices[0].message.content
print(f"Document hypothétique: {hypothetical_doc[:100]}...")
# 2. Embedder document hypothétique
embedding = embedding_model.encode(hypothetical_doc)
# 3. Rechercher
results = vectordb.search(embedding, top_k=top_k)
return results
# Utilisation
question = "How does HNSW algorithm work?"
docs = hyde_retrieval(question)
Amélioration attendue
- Recall : +10-20% pour questions complexes
- Trade-off : +200-500ms, coût LLM
- Meilleur pour questions techniques/spécifiques
Agentic RAG
Principe
Un agent décide :
- Quand chercher
- Où chercher (quelle base)
- Comment reformuler
- Si la réponse est suffisante
Implémentation avec LangChain
from langchain.agents import Tool, AgentExecutor, create_react_agent
from langchain_openai import ChatOpenAI
from langchain import hub
# LLM
llm = ChatOpenAI(model="gpt-4", temperature=0)
# Tools
def search_technical_docs(query: str) -> str:
"""Rechercher dans docs techniques."""
results = tech_vectordb.search(query, top_k=3)
return "\n\n".join([r.text for r in results])
def search_business_docs(query: str) -> str:
"""Rechercher dans docs business."""
results = business_vectordb.search(query, top_k=3)
return "\n\n".join([r.text for r in results])
tools = [
Tool(
name="SearchTechnicalDocs",
func=search_technical_docs,
description="Recherche docs techniques (API, code, architecture)"
),
Tool(
name="SearchBusinessDocs",
func=search_business_docs,
description="Recherche docs business (produit, stratégie, marketing)"
)
]
# Agent
prompt = hub.pull("hwchase17/react")
agent = create_react_agent(llm, tools, prompt)
# Executor
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
max_iterations=5
)
# Utilisation
question = "How to implement authentication in our API?"
result = agent_executor.invoke({"input": question})
print(result['output'])
Agent reasoning :
Thought: Je dois chercher dans les docs techniques.
Action: SearchTechnicalDocs
Action Input: "authentication API implementation"
Observation: [results]
Thought: J'ai trouvé des infos sur l'implémentation. Je vérifie les best practices business.
Action: SearchBusinessDocs
Action Input: "authentication security requirements"
Observation: [results]
Thought: J'ai toutes les infos nécessaires.
Final Answer: Pour implémenter l'authentification...
Amélioration attendue
- Precision : +20-30%
- Adaptabilité : Très élevée
- Trade-off : +1-5s latence, coût LLM élevé
Contextual Compression
Principe
Compresser le contexte pour ne garder que les parties pertinentes.
Document récupéré (1000 tokens):
"Paragraph 1: Irrelevant...
Paragraph 2: Answers the question...
Paragraph 3: Irrelevant..."
Après compression (200 tokens):
"Paragraph 2: Answers the question..."
Implémentation avec LangChain
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain_openai import OpenAI
# Base retriever
base_retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
# Compressor (LLM)
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
# Compression retriever
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=base_retriever
)
# Utilisation
question = "What is Python used for?"
# Récupère ET compresse
compressed_docs = compression_retriever.get_relevant_documents(question)
for doc in compressed_docs:
print(f"Compressed (len={len(doc.page_content)}): {doc.page_content}")
Amélioration attendue
- Context quality : +15-25%
- Token usage : -50-70% (économies LLM)
- Trade-off : +500-1000ms (LLM compression)
Évaluation avec RAGAS
Métriques RAGAS
from ragas import evaluate
from ragas.metrics import (
context_precision,
context_recall,
faithfulness,
answer_relevancy
)
# Données d'évaluation
data_samples = {
'question': [
"What is Python?",
"How to install numpy?"
],
'answer': [
"Python is a programming language...",
"Use pip install numpy..."
],
'contexts': [
[["Python is an interpreted...", "Created by Guido..."]],
[["Numpy is installed...", "Use pip or conda..."]]
],
'ground_truth': [
"Python is a high-level programming language",
"Install numpy with pip install numpy"
]
}
from datasets import Dataset
dataset = Dataset.from_dict(data_samples)
# Évaluer
result = evaluate(
dataset,
metrics=[
context_precision,
context_recall,
faithfulness,
answer_relevancy
]
)
print(result)
Output :
{
'context_precision': 0.85,
'context_recall': 0.92,
'faithfulness': 0.88,
'answer_relevancy': 0.91
}
Métriques expliquées
| Métrique | Description | Cible |
|---|---|---|
| Context Precision | % contexte pertinent | >0.85 |
| Context Recall | % infos nécessaires récupérées | >0.90 |
| Faithfulness | Réponse fidèle au contexte | >0.85 |
| Answer Relevancy | Réponse répond à la question | >0.90 |
Pipeline RAG avancé complet
class AdvancedRAG:
"""RAG avec toutes les techniques avancées."""
def __init__(self, vectordb, openai_key, cohere_key):
self.vectordb = vectordb
self.openai = OpenAI(api_key=openai_key)
self.cohere = cohere.Client(api_key=cohere_key)
self.embedding_model = SentenceTransformer('all-mpnet-base-v2')
def ask(self, question: str) -> dict:
"""
RAG avancé complet.
Returns:
{'answer', 'sources', 'confidence'}
"""
# 1. Multi-query expansion
queries = self._expand_queries(question, n=2)
print(f"✓ Queries: {len(queries)}")
# 2. Hybrid retrieval (si Weaviate)
all_docs = []
for query in queries:
docs = self._hybrid_search(query, top_k=5)
all_docs.extend(docs)
# Dédupliquer
unique_docs = list(dict.fromkeys(all_docs))
print(f"✓ Documents récupérés: {len(unique_docs)}")
# 3. Rerank avec Cohere
reranked_docs = self._rerank(question, unique_docs, top_k=5)
print(f"✓ Après reranking: {len(reranked_docs)}")
# 4. Contextual compression
compressed_docs = self._compress_context(question, reranked_docs)
print(f"✓ Après compression: {len(compressed_docs)}")
# 5. Générer réponse
context = "\n\n".join(compressed_docs)
answer = self._generate_answer(question, context)
# 6. Calculer confiance
confidence = self._calculate_confidence(answer, compressed_docs)
return {
'answer': answer,
'sources': compressed_docs,
'confidence': confidence
}
def _expand_queries(self, question: str, n: int) -> list[str]:
"""Multi-query expansion."""
# ... (code précédent)
pass
def _hybrid_search(self, query: str, top_k: int) -> list[str]:
"""Hybrid search (vectoriel + BM25)."""
# ... (code précédent)
pass
def _rerank(self, query: str, docs: list[str], top_k: int) -> list[str]:
"""Rerank avec Cohere."""
response = self.cohere.rerank(
query=query,
documents=docs,
top_n=top_k,
model='rerank-english-v2.0'
)
return [docs[r.index] for r in response.results]
def _compress_context(self, question: str, docs: list[str]) -> list[str]:
"""Compression contextuelle."""
# Filtrer parties non pertinentes avec LLM
# ... (simplifié ici)
return docs # En prod : vraie compression
def _generate_answer(self, question: str, context: str) -> str:
"""Générer réponse."""
response = self.openai.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "Réponds avec le contexte."},
{"role": "user", "content": f"Contexte:\n{context}\n\nQuestion: {question}"}
]
)
return response.choices[0].message.content
def _calculate_confidence(self, answer: str, sources: list[str]) -> float:
"""Calculer score de confiance."""
# En prod : utiliser métriques RAGAS
return 0.85 # Placeholder
# Utilisation
rag = AdvancedRAG(vectordb, openai_key="...", cohere_key="...")
result = rag.ask("How does HNSW work?")
print(f"Answer: {result['answer']}")
print(f"Confidence: {result['confidence']:.2%}")
print(f"Sources: {len(result['sources'])}")
Comparaison techniques
| Technique | Amélioration | Latence | Coût | Complexité |
|---|---|---|---|---|
| Hybrid search | +10-15% | +5ms | Gratuit | ⭐⭐ |
| Reranking | +15-25% | +50-100ms | $ | ⭐⭐ |
| Multi-query | +15-30% | +200-500ms | $$ | ⭐⭐⭐ |
| Parent-child | +10-20% | +10ms | Gratuit | ⭐⭐⭐ |
| HyDE | +10-20% | +200-500ms | $$ | ⭐⭐ |
| Agentic RAG | +20-30% | +1-5s | $$$ | ⭐⭐⭐⭐⭐ |
| Compression | +15-25% | +500ms | $$ | ⭐⭐⭐ |
Recommandations par use case
Latence critique (<200ms) :
- ✅ Hybrid search
- ✅ Parent-child chunks
- ❌ Éviter reranking, multi-query, compression
Qualité critique :
- ✅ Toutes les techniques !
- ✅ Priorité : Reranking + Multi-query + Compression
Budget limité :
- ✅ Hybrid search (gratuit)
- ✅ Parent-child (gratuit)
- ❌ Éviter multi-query, agentic RAG
Conclusion de la série
Récapitulatif complet
Nous avons couvert tout le spectre des bases vectorielles :
📚 Fondamentaux :
- ✅ Concept de base vectorielle
- ✅ Embeddings et similarité
- ✅ Algorithmes (HNSW, IVF)
🛠️ Solutions :
- ✅ Pinecone (cloud managé)
- ✅ Weaviate (hybrid search)
- ✅ Chroma (dev local)
- ✅ Qdrant, Milvus, FAISS, pgvector
🚀 Production :
- ✅ Architecture complète
- ✅ Monitoring, optimisation
- ✅ Scalabilité, sécurité
🎯 RAG Avancé :
- ✅ Hybrid search
- ✅ Reranking
- ✅ Multi-query, HyDE
- ✅ Agents RAG
- ✅ Évaluation RAGAS
Ce que vous savez maintenant
Après cette série complète, vous êtes capable de :
✅ Choisir la bonne base vectorielle selon vos besoins
✅ Implémenter un système RAG production-ready
✅ Optimiser performances et coûts
✅ Évaluer la qualité avec métriques objectives
✅ Scaler de 1K à 100M+ vecteurs
✅ Appliquer techniques state-of-the-art 2025
Prochaines étapes
- Pratiquer : Créez votre premier chatbot RAG
- Expérimenter : Testez différentes bases vectorielles
- Optimiser : Appliquez techniques avancées progressivement
- Mesurer : Évaluez avec RAGAS
- Itérer : Améliorez continuellement
Ressources pour aller plus loin
Documentation :
Communautés :
- r/LocalLLaMA (Reddit)
- LangChain Discord
- AI Stack Exchange
Veille :
- Papers With Code (RAG)
- arXiv (cs.CL, cs.IR)
- Hugging Face Blog
Merci d’avoir suivi cette série complète sur les bases de données vectorielles !
Si vous avez des questions ou suggestions, n’hésitez pas à nous contacter.
Autres séries à découvrir :