Production et optimisation : déployer une base vectorielle à l'échelle
Passer d’un prototype à une application production-ready nécessite bien plus qu’une simple base vectorielle.
Dans cet article, nous couvrons tout ce dont vous avez besoin pour déployer en production de manière robuste et scalable.
Objectifs de l’article
Après avoir lu cet article, vous serez capable de :
- ✅ Architecturer un système vectoriel production-ready
- ✅ Implémenter un cache efficace (Redis)
- ✅ Monitorer avec Prometheus et Grafana
- ✅ Optimiser les performances (batch, quantization)
- ✅ Gérer la scalabilité (horizontale/verticale)
- ✅ Sécuriser l’accès et gérer les coûts
- ✅ Appliquer les best practices
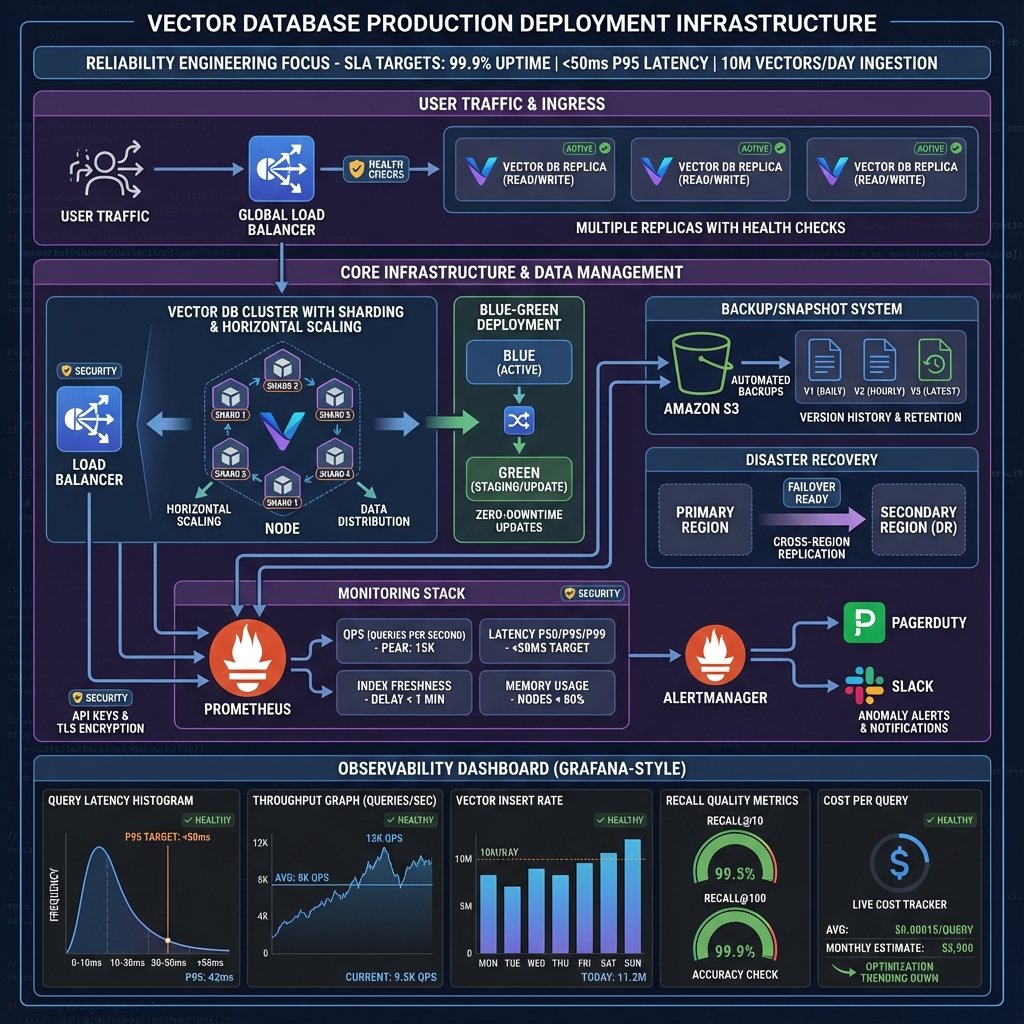
Architecture production
Stack complet
┌─────────────┐
│ Users │
└──────┬──────┘
│
┌────────▼────────┐
│ Load Balancer │ ← Nginx, AWS ELB
│ (Rate Limiting)│
└────────┬────────┘
│
┌────────────┼────────────┐
│ │ │
┌────▼───┐ ┌───▼────┐ ┌──▼─────┐
│API #1 │ │API #2 │ │API #3 │ ← FastAPI, Flask
└────┬───┘ └───┬────┘ └──┬─────┘
│ │ │
└────────────┼───────────┘
│
┌────────▼────────┐
│ Redis Cache │ ← Caching layer
└────────┬────────┘
│
┌────────────┼────────────┐
│ │ │
┌─────────▼───────┐ │ ┌────────▼────────┐
│ Embedding │ │ │ Vector Database │
│ Service │ │ │ (Pinecone/Qdr.) │
│ (OpenAI/Local) │ │ └────────┬────────┘
└─────────────────┘ │ │
│ ┌────────▼────────┐
│ │ LLM Service │
│ │ (GPT-4/Claude) │
│ └─────────────────┘
│
┌─────────▼──────────┐
│ Monitoring Stack │
│ Prometheus+Grafana │
└─────────────────────┘
Composants clés
- Load Balancer : Distribution requêtes, rate limiting
- API Servers : Application logic (FastAPI)
- Cache : Redis pour résultats fréquents
- Embedding Service : Génération embeddings
- Vector DB : Pinecone, Qdrant, Weaviate
- LLM Service : OpenAI, Anthropic
- Monitoring : Prometheus, Grafana, Logs
Caching strategy
Pourquoi un cache ?
Les embeddings sont coûteux à générer :
- OpenAI : $0.02/1M tokens
- Temps : 100-500ms par appel
Le cache Redis peut réduire coûts de 90%+ !
Redis setup
# Docker
docker run -d -p 6379:6379 redis:latest
# Python
pip install redis
Implémentation
import redis
import hashlib
import json
from openai import OpenAI
class CachedEmbeddingService:
"""Service d'embeddings avec cache Redis."""
def __init__(self, openai_key: str, redis_host: str = "localhost"):
self.openai = OpenAI(api_key=openai_key)
self.redis = redis.Redis(host=redis_host, port=6379, db=0, decode_responses=True)
self.ttl = 86400 * 7 # 7 jours
def _cache_key(self, text: str, model: str) -> str:
"""Générer clé cache."""
content = f"{model}:{text}"
return f"emb:{hashlib.md5(content.encode()).hexdigest()}"
def get_embedding(self, text: str, model: str = "text-embedding-3-small") -> list[float]:
"""
Obtenir embedding avec cache.
Args:
text: Texte à embedder
model: Modèle OpenAI
Returns:
Embedding (liste de floats)
"""
# 1. Vérifier cache
cache_key = self._cache_key(text, model)
cached = self.redis.get(cache_key)
if cached:
print("✅ Cache HIT")
return json.loads(cached)
# 2. Cache MISS : générer embedding
print("❌ Cache MISS : appel OpenAI")
response = self.openai.embeddings.create(
model=model,
input=text
)
embedding = response.data[0].embedding
# 3. Stocker dans cache
self.redis.setex(
cache_key,
self.ttl,
json.dumps(embedding)
)
return embedding
def clear_cache(self):
"""Vider tout le cache."""
for key in self.redis.scan_iter("emb:*"):
self.redis.delete(key)
# Utilisation
service = CachedEmbeddingService(openai_key="sk-...")
# Premier appel : cache MISS
emb1 = service.get_embedding("bases de données") # ~200ms
# Deuxième appel : cache HIT
emb2 = service.get_embedding("bases de données") # ~2ms (100× plus rapide !)
Cache pour résultats de recherche
class CachedVectorSearch:
"""Recherche vectorielle avec cache."""
def __init__(self, vectordb, redis_client):
self.vectordb = vectordb
self.redis = redis_client
self.ttl = 3600 # 1 heure
def search(self, query: str, top_k: int = 5) -> list:
"""Recherche avec cache."""
# Clé cache
cache_key = f"search:{hashlib.md5(query.encode()).hexdigest()}:{top_k}"
# Vérifier cache
cached = self.redis.get(cache_key)
if cached:
return json.loads(cached)
# Cache MISS : recherche réelle
results = self.vectordb.search(query, top_k=top_k)
# Stocker dans cache
self.redis.setex(cache_key, self.ttl, json.dumps(results))
return results
Monitoring et métriques
Stack monitoring
- Prometheus : Collecte métriques
- Grafana : Visualisation dashboards
- Loki (optionnel) : Logs centralisés
Métriques clés
from prometheus_client import Counter, Histogram, Gauge, start_http_server
import time
# === Métriques ===
# Requêtes totales
requests_total = Counter(
'vector_db_requests_total',
'Total requests',
['operation', 'status']
)
# Latence
latency_histogram = Histogram(
'vector_db_latency_seconds',
'Request latency',
['operation'],
buckets=[0.01, 0.05, 0.1, 0.5, 1.0, 2.0, 5.0]
)
# Cache hit rate
cache_hits = Counter('cache_hits_total', 'Cache hits')
cache_misses = Counter('cache_misses_total', 'Cache misses')
# Vector DB size
vector_count = Gauge('vector_db_count', 'Number of vectors')
# === Instrumentation ===
def search_with_metrics(query: str):
"""Recherche avec métriques."""
start = time.time()
try:
# Recherche
results = vectordb.search(query)
# Succès
requests_total.labels(operation='search', status='success').inc()
return results
except Exception as e:
# Erreur
requests_total.labels(operation='search', status='error').inc()
raise
finally:
# Latence
latency = time.time() - start
latency_histogram.labels(operation='search').observe(latency)
# Démarrer serveur métriques (port 8000)
start_http_server(8000)
Dashboard Grafana
Dashboards importants :
Overview :
- Requêtes/seconde
- Latence p50, p95, p99
- Taux d’erreur
Cache :
- Hit rate (%)
- Hits vs Misses
- Économies ($)
Vector DB :
- Nombre de vecteurs
- Taille stockage
- Coûts mensuels
Performance :
- Latence par opération
- Throughput
- Queues
Scalabilité
Scaling vertical
Augmenter ressources serveur.
# Docker Compose
services:
vectordb:
image: qdrant/qdrant
deploy:
resources:
limits:
cpus: '4'
memory: 16G
reservations:
cpus: '2'
memory: 8G
Quand : <1M vecteurs, trafic modéré
Scaling horizontal
Distribuer charge sur plusieurs serveurs.
Load Balancing
# nginx.conf
upstream api_servers {
server api1:8000;
server api2:8000;
server api3:8000;
}
server {
listen 80;
location / {
proxy_pass http://api_servers;
proxy_set_header Host $host;
}
}
Read replicas
# Distribuer lectures sur replicas
class LoadBalancedVectorDB:
def __init__(self, primary, replicas):
self.primary = primary
self.replicas = replicas
self.replica_index = 0
def write(self, data):
"""Écriture sur primary."""
return self.primary.write(data)
def search(self, query):
"""Lecture sur replica (round-robin)."""
replica = self.replicas[self.replica_index]
self.replica_index = (self.replica_index + 1) % len(self.replicas)
return replica.search(query)
Quand : >1M vecteurs, trafic élevé
Optimisations de performance
Batch queries
# ❌ Lent : queries individuelles
for query in queries:
results = vectordb.search(query)
# ✅ Rapide : batch
results = vectordb.batch_search(queries) # 10× plus rapide
Dimensionality reduction
from sklearn.decomposition import PCA
# Réduire 1536 → 384 dimensions
pca = PCA(n_components=384)
embeddings_reduced = pca.fit_transform(embeddings)
# Économie : 4× moins de stockage, 4× plus rapide
Trade-off : ~5-10% de précision perdue
Quantization
Réduire précision des vecteurs.
# Float32 (4 bytes) → Int8 (1 byte)
import numpy as np
def quantize_embedding(embedding):
"""Quantize float32 → int8."""
# Normaliser [-1, 1] → [-128, 127]
quantized = np.clip(embedding * 127, -128, 127).astype(np.int8)
return quantized
# Économie : 4× moins de stockage
Async/concurrent processing
import asyncio
from concurrent.futures import ThreadPoolExecutor
async def search_async(query):
"""Recherche asynchrone."""
loop = asyncio.get_event_loop()
with ThreadPoolExecutor() as pool:
result = await loop.run_in_executor(pool, vectordb.search, query)
return result
# Traiter N queries en parallèle
async def process_queries(queries):
tasks = [search_async(q) for q in queries]
results = await asyncio.gather(*tasks)
return results
Sécurité
Authentification
from fastapi import FastAPI, Security, HTTPException
from fastapi.security import HTTPBearer, HTTPAuthorizationCredentials
app = FastAPI()
security = HTTPBearer()
# Vérifier API key
def verify_api_key(credentials: HTTPAuthorizationCredentials = Security(security)):
if credentials.credentials != "your-secret-key":
raise HTTPException(status_code=403, detail="Invalid API key")
return credentials.credentials
@app.post("/search")
async def search(query: str, token: str = Security(verify_api_key)):
"""Endpoint sécurisé."""
results = vectordb.search(query)
return results
Rate limiting
from slowapi import Limiter, _rate_limit_exceeded_handler
from slowapi.util import get_remote_address
from slowapi.errors import RateLimitExceeded
limiter = Limiter(key_func=get_remote_address)
app = FastAPI()
app.state.limiter = limiter
app.add_exception_handler(RateLimitExceeded, _rate_limit_exceeded_handler)
@app.post("/search")
@limiter.limit("100/minute") # 100 requêtes/minute
async def search(request: Request, query: str):
results = vectordb.search(query)
return results
Chiffrement
# Chiffrer données sensibles
from cryptography.fernet import Fernet
key = Fernet.generate_key()
cipher = Fernet(key)
# Chiffrer avant stockage
text_encrypted = cipher.encrypt(text.encode())
# Déchiffrer après récupération
text_decrypted = cipher.decrypt(text_encrypted).decode()
Gestion des coûts
Optimisations
- Cache agressif : 90%+ économies
- Batch operations : Réduire appels API
- Dimensionality reduction : 4× moins de stockage
- Quantization : 4× moins de stockage
- Spot instances : AWS/GCP (jusqu’à -70%)
- Reserved capacity : Pinecone/Cloud (-40%)
Monitoring coûts
# Tracker coûts
class CostTracker:
def __init__(self):
self.embedding_cost = 0.00002 # $0.02/1M tokens
self.llm_cost = 0.001 # $1/1M tokens (GPT-4)
self.vectordb_cost = 0.0001 # Par query
def track_embedding(self, tokens: int):
cost = tokens * self.embedding_cost / 1000
# Log cost
print(f"Embedding cost: ${cost:.6f}")
def track_llm(self, tokens: int):
cost = tokens * self.llm_cost / 1000
print(f"LLM cost: ${cost:.6f}")
CI/CD pour vector DBs
Pipeline
# .gitlab-ci.yml
stages:
- test
- build
- deploy
test:
stage: test
script:
- pytest tests/
- python benchmark_recall.py # Vérifier recall@10 > 95%
build:
stage: build
script:
- docker build -t api:$CI_COMMIT_SHA .
- docker push api:$CI_COMMIT_SHA
deploy_staging:
stage: deploy
script:
- kubectl set image deployment/api api=api:$CI_COMMIT_SHA
- python verify_deployment.py # Smoke tests
deploy_production:
stage: deploy
when: manual # Déploiement manuel en prod
script:
- kubectl set image deployment/api api=api:$CI_COMMIT_SHA --namespace=production
Version control embeddings
# Versioner embeddings
class EmbeddingVersioning:
def __init__(self, vectordb):
self.vectordb = vectordb
def create_version(self, version_name: str):
"""Créer snapshot."""
# Backup index
self.vectordb.create_snapshot(version_name)
def rollback(self, version_name: str):
"""Rollback vers version."""
self.vectordb.restore_snapshot(version_name)
Best practices checklist
Architecture
- Load balancer avec rate limiting
- API servers scalables (3+ instances)
- Cache Redis pour embeddings et résultats
- Monitoring Prometheus + Grafana
- Logs centralisés (ELK, Loki)
Performance
- Batch operations partout
- Dimensionality reduction évaluée
- Async/concurrent processing
- Index optimisé (HNSW tuning)
- CDN pour assets statiques
Sécurité
- Authentification (API keys)
- Rate limiting (100-1000/min)
- HTTPS obligatoire
- Chiffrement données sensibles
- Logs d’audit
Coûts
- Cache hit rate >80%
- Monitoring coûts temps réel
- Alertes sur dépassement budget
- Reserved capacity pour économies
- Suppression données obsolètes
Reliability
- Health checks
- Auto-restart conteneurs
- Backups quotidiens
- Disaster recovery plan
- Multi-region (si critique)
Conclusion
Déployer en production nécessite bien plus qu’une simple base vectorielle :
✅ Architecture complète (load balancer, cache, monitoring)
✅ Optimisations (batch, quantization, dimensionality reduction)
✅ Monitoring (Prometheus, Grafana, alertes)
✅ Sécurité (authentification, rate limiting, chiffrement)
✅ Coûts (cache, optimisations, reserved capacity)
✅ CI/CD (tests, déploiement automatisé)
Dans le dernier article de la série, nous couvrirons les techniques RAG avancées : hybrid search, reranking, multi-query, et agents RAG.
👉 Article 9 : RAG avancé avec bases vectorielles
Ressources complémentaires
Articles liés :
Outils :