Introduction aux bases de données vectorielles | Guide Complet
Les bases de données vectorielles sont devenues essentielles pour les applications d’IA modernes. Si vous travaillez avec des LLMs, du RAG (Retrieval-Augmented Generation), ou de la recherche sémantique, vous en avez besoin.
Dans cet article, nous allons découvrir ce qu’est une base de données vectorielle, comment elle fonctionne, et pourquoi elle est indispensable en 2025.
Objectifs de l’article
Après avoir lu cet article, vous serez capable de :
- ✅ Comprendre ce qu’est une base vectorielle et son rôle
- ✅ Identifier les cas d’usage pertinents
- ✅ Différencier bases vectorielles, SQL et NoSQL
- ✅ Créer votre première base vectorielle avec Chroma
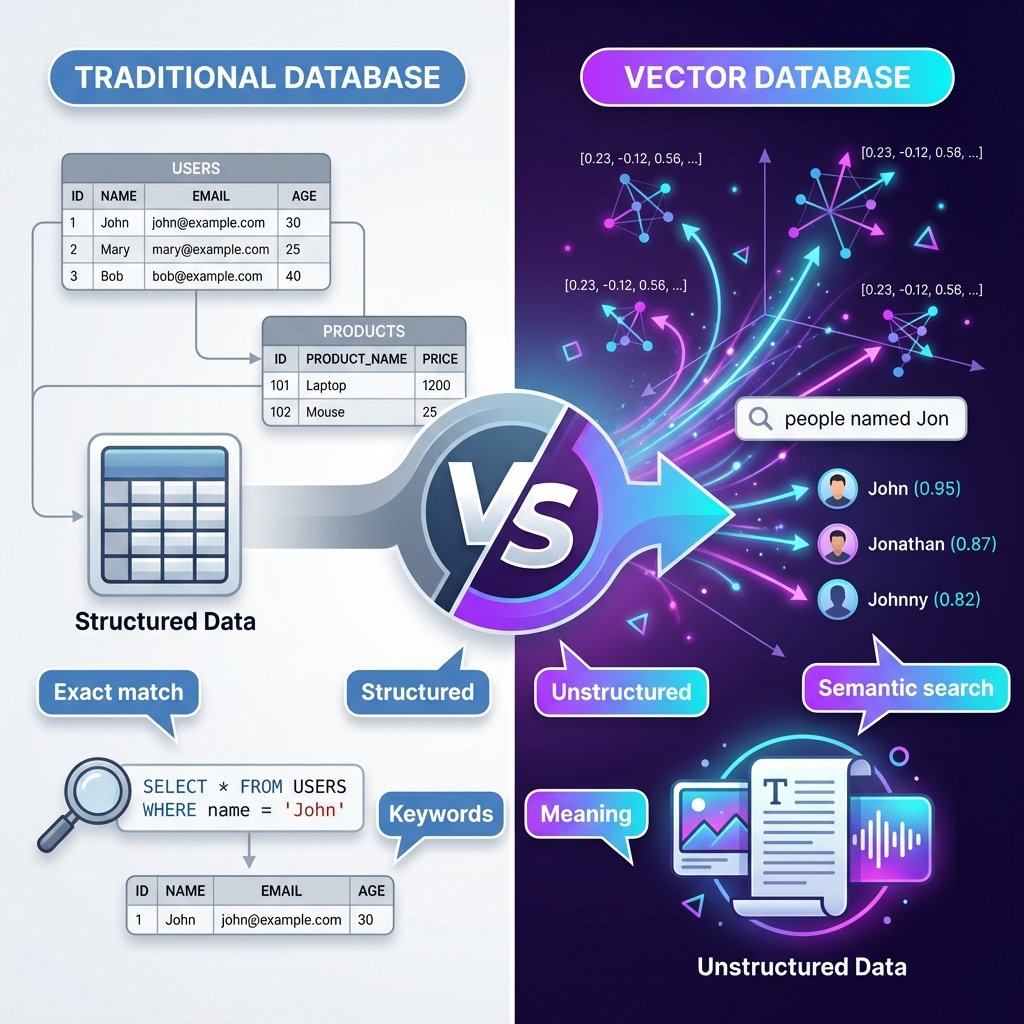
Le problème de la recherche classique
Imaginez que vous cherchez des articles sur “automobile électrique” dans une base de données traditionnelle.
Recherche par mots-clés (SQL)
SELECT * FROM articles
WHERE title LIKE '%automobile%'
OR content LIKE '%automobile%';
Problème : Cette requête ne trouve PAS les articles contenant :
- “voiture électrique”
- “véhicule électrique”
- “Tesla Model 3”
- “EV (Electric Vehicle)”
Pourquoi ? Parce que la recherche SQL est exacte et littérale. Elle ne comprend pas le sens des mots.
Qu’est-ce qu’une base de données vectorielle ?
Une base de données vectorielle (ou vector database) est une base de données spécialisée pour stocker et rechercher des vecteurs (aussi appelés embeddings).
Définition simple
Une base vectorielle stocke des représentations numériques (vecteurs) qui capturent le sens sémantique de vos données (texte, images, audio).
Qu’est-ce qu’un Vecteur/Embedding ?
Un embedding est une liste de nombres qui représente le sens d’un mot, phrase, ou document.
Exemple :
# Texte original
text = "Les bases de données vectorielles"
# Embedding (représentation vectorielle)
embedding = [0.12, -0.45, 0.78, 0.33, -0.21, ...] # 1536 nombres
Les mots similaires ont des vecteurs proches dans l’espace :
"roi" → [0.2, 0.8, -0.3, ...]
"reine" → [0.18, 0.75, -0.28, ...] # Proche de "roi"
"voiture" → [-0.5, 0.1, 0.6, ...] # Loin de "roi"
Comment fonctionne une base vectorielle ?
Le processus se déroule en 3 étapes :
Vectorisation (Embedding)
Transformer vos données en vecteurs avec un modèle d’embedding.
from sentence_transformers import SentenceTransformer
# Charger un modèle d'embedding
model = SentenceTransformer('all-MiniLM-L6-v2')
# Vectoriser du texte
text = "Les bases de données vectorielles sont puissantes"
embedding = model.encode(text)
print(f"Dimension : {len(embedding)}") # 384 nombres
print(f"Vecteur : {embedding[:5]}") # Premiers 5 nombres
Output :
Dimension : 384
Vecteur : [ 0.0234 -0.0512 0.0891 -0.0342 0.0621]
Stockage
Les vecteurs sont indexés dans la base avec des métadonnées.
import chromadb
# Créer une base vectorielle locale
client = chromadb.Client()
collection = client.create_collection("my_documents")
# Ajouter des documents
collection.add(
documents=[
"Les chats sont des animaux mignons",
"Les chiens sont fidèles et loyaux",
"Python est un langage de programmation"
],
ids=["doc1", "doc2", "doc3"],
metadatas=[
{"category": "animaux"},
{"category": "animaux"},
{"category": "tech"}
]
)
Recherche par similarité
Lorsque vous faites une requête, la base :
- Vectorise votre requête (même modèle qu’au stockage)
- Calcule la similarité avec tous les vecteurs stockés
- Retourne les K plus proches (K = nombre de résultats souhaités)
# Rechercher
results = collection.query(
query_texts=["animaux de compagnie"],
n_results=2
)
print(results['documents'])
Output :
[
"Les chiens sont fidèles et loyaux",
"Les chats sont des animaux mignons"
]
Métrique de similarité : comment comparer des Vecteurs ?
Les 3 métriques principales :
Cosine Similarity (la plus utilisée)
Mesure l’angle entre deux vecteurs. Valeur entre -1 et 1.
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# Deux vecteurs
vec1 = np.array([[0.5, 0.8, 0.2]])
vec2 = np.array([[0.6, 0.7, 0.3]])
similarity = cosine_similarity(vec1, vec2)[0][0]
print(f"Similarité : {similarity:.4f}") # Ex: 0.9823
- 1.0 : Identiques
- 0.0 : Orthogonaux (pas de relation)
- -1.0 : Opposés
Dot Product
Produit scalaire simple. Rapide mais sensible à la magnitude.
dot_product = np.dot(vec1[0], vec2[0])
print(f"Dot product : {dot_product:.4f}")
Euclidean Distance
Distance géométrique classique. Valeur de 0 à ∞.
from scipy.spatial.distance import euclidean
distance = euclidean(vec1[0], vec2[0])
print(f"Distance : {distance:.4f}")
- 0 : Identiques
- Plus grand : Plus différents
Recommandation : Utilisez cosine similarity pour la recherche sémantique de texte. C’est le standard de facto.
Bases vectorielles vs bases traditionnelles
Comparons avec SQL et NoSQL :
| Caractéristique | SQL (PostgreSQL) | NoSQL (MongoDB) | Vectorielle (Pinecone) |
|---|---|---|---|
| Type de données | Tables structurées | Documents JSON | Vecteurs + métadonnées |
| Recherche | Exacte (WHERE) | Texte/filtres | Similarité sémantique |
| Query | SELECT * WHERE | find({query}) | similarity_search(vector) |
| Index | B-tree, Hash | B-tree | HNSW, IVF |
| Use case | Transactions | Flexibilité | IA, ML, Recherche |
| Performance | O(log n) | O(log n) | O(log n) avec ANN |
| Exemple | E-commerce orders | User profiles | RAG, recommandation |
Pourquoi pas PostgreSQL + pgvector ?
PostgreSQL peut stocker des vecteurs avec l’extension pgvector :
CREATE EXTENSION vector;
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(384)
);
-- Recherche par similarité
SELECT * FROM documents
ORDER BY embedding <-> '[0.1, 0.2, ...]'
LIMIT 5;
Avantages :
- ✅ Combine données SQL + vecteurs
- ✅ Bon pour petite échelle (<100K vecteurs)
Inconvénients :
- ❌ Performance dégradée au-delà de 100K-1M vecteurs
- ❌ Pas d’algorithmes spécialisés (HNSW, IVF)
- ❌ Scaling difficile
Règle : pgvector pour prototypes ou petits datasets. Base vectorielle spécialisée pour production et grande échelle.
Cas d’usage principaux
RAG (Retrieval-Augmented Generation)
Problème : Les LLMs ont une connaissance limitée (date de coupure) et peuvent halluciner.
Solution : RAG = Récupérer des documents pertinents + les donner au LLM en contexte.
# Architecture RAG simplifiée
def rag_query(question: str):
# 1. Vectoriser la question
query_embedding = embedding_model.encode(question)
# 2. Rechercher documents similaires
results = vector_db.search(query_embedding, top_k=3)
# 3. Construire le contexte
context = "\n".join([doc.content for doc in results])
# 4. Demander au LLM
prompt = f"Contexte: {context}\n\nQuestion: {question}"
answer = llm.generate(prompt)
return answer
Exemple concret : Chatbot entreprise qui répond avec vos documents internes.
Recherche sémantique
E-commerce : “robe d’été légère” trouve aussi “robe estivale”, “robe fleurie”
Documentation : Recherche d’articles similaires par sens, pas par mots-clés
Systèmes de recommandation
Netflix : Films similaires basés sur le synopsis vectorisé
Spotify : Musiques proches par style, ambiance, tempo
Détection d’anomalies
Sécurité : Comportements inhabituels (vecteur très différent de la normale)
Fraud detection : Transactions suspectes
Recherche d’images
Google Images : “Trouve des images similaires à celle-ci”
Pinterest : Produits visuellement similaires
L’écosystème des bases vectorielles
Le paysage est riche avec 20+ solutions. Voici les principales :
Cloud/managed (sans gestion d’infrastructure)
| Solution | Points Forts | Pricing |
|---|---|---|
| Pinecone | 🥇 Le plus simple, excellent support | $70/mois (starter) |
| Weaviate Cloud | Hybrid search natif | $25/mois (sandbox) |
| Qdrant Cloud | Performant, Rust | Pay-as-you-go |
Open source (self-hosted)
| Solution | Points Forts | Complexité |
|---|---|---|
| Weaviate | Hybrid search, modules | ⭐⭐⭐ Moyenne |
| Qdrant | Très rapide, Rust | ⭐⭐ Facile |
| Milvus | Scalabilité massive | ⭐⭐⭐⭐ Élevée |
Embedded/locale (pour développement)
| Solution | Points Forts | Use Case |
|---|---|---|
| Chroma | Le plus simple | Prototypes, dev local |
| LanceDB | Integration Pandas/Arrow | Data science |
| FAISS | Library Meta, très rapide | Recherche locale |
Extensions SQL
| Solution | Points Forts | Limite |
|---|---|---|
| pgvector | Extension PostgreSQL | <100K vecteurs |
| MySQL Vector | MySQL 9.0+ | Nouveau, peu mature |
Notre recommandation : - Débuter : Chroma (gratuit, local, simple) - Production petite échelle : Qdrant (open source, performant) - Production sans infra : Pinecone (managed, simple) - Très grande échelle : Milvus (distributif)
Architecture typique d’une application RAG
Voici comment les bases vectorielles s’intègrent dans un système complet :
┌─────────────────┐
│ User Query │
└────────┬────────┘
│
┌────────▼────────┐
│ Embedding Model │ ← OpenAI, Sentence-BERT
│ (vectorisation) │
└────────┬────────┘
│
Vector (1536 dim)
│
┌────────▼────────┐
│ Base Vectorielle│ ← Pinecone, Weaviate, Chroma
│ (search top-K) │
└────────┬────────┘
│
Documents pertinents (3-5)
│
┌────────▼────────┐
│ LLM + Context │ ← GPT-4, Claude, Llama
│ (generation) │
└────────┬────────┘
│
┌────────▼────────┐
│ Réponse finale │
└─────────────────┘
Flux étape par étape :
- User query : “Quelle est la politique de retour ?”
- Embedding : Vectoriser la question →
[0.12, -0.45, ...] - Vector search : Trouver 3-5 documents les plus similaires
- Context : Combiner les documents trouvés
- LLM : Générer réponse basée sur le contexte
- Response : “Vous avez 30 jours pour retourner…”
Exemple concret : premier chatbot RAG
Créons un chatbot simple qui répond avec vos propres documents.
Installation
pip install chromadb sentence-transformers openai
Code complet
import chromadb
from sentence_transformers import SentenceTransformer
from openai import OpenAI
# === 1. Initialisation ===
# Base vectorielle locale
chroma_client = chromadb.Client()
collection = chroma_client.create_collection("knowledge_base")
# Modèle d'embedding
embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
# LLM
openai_client = OpenAI(api_key="sk-...")
# === 2. Indexer des Documents ===
documents = [
"Notre entreprise offre une garantie de 2 ans sur tous les produits électroniques.",
"Les retours sont acceptés dans les 30 jours avec le reçu original.",
"Le service client est disponible du lundi au vendredi de 9h à 18h.",
"Nous livrons gratuitement pour les commandes supérieures à 50€."
]
# Générer embeddings
embeddings = embedding_model.encode(documents).tolist()
# Stocker dans Chroma
collection.add(
documents=documents,
embeddings=embeddings,
ids=[f"doc{i}" for i in range(len(documents))],
metadatas=[{"source": "FAQ"} for _ in documents]
)
# === 3. Fonction RAG ===
def ask_question(question: str) -> str:
# Vectoriser la question
query_embedding = embedding_model.encode([question])[0].tolist()
# Rechercher documents similaires
results = collection.query(
query_embeddings=[query_embedding],
n_results=2 # Top 2 documents
)
# Construire le contexte
context = "\n".join(results['documents'][0])
# Demander au LLM
response = openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "Tu es un assistant qui répond uniquement avec le contexte fourni."},
{"role": "user", "content": f"Contexte:\n{context}\n\nQuestion: {question}"}
]
)
return response.choices[0].message.content
# === 4. Utilisation ===
questions = [
"Quelle est la durée de la garantie ?",
"Puis-je retourner un produit ?",
"Quand est ouvert le service client ?"
]
for q in questions:
print(f"\n❓ {q}")
print(f"💬 {ask_question(q)}")
Output :
❓ Quelle est la durée de la garantie ?
💬 Notre entreprise offre une garantie de 2 ans sur tous les produits électroniques.
❓ Puis-je retourner un produit ?
💬 Oui, les retours sont acceptés dans les 30 jours avec le reçu original.
❓ Quand est ouvert le service client ?
💬 Le service client est disponible du lundi au vendredi de 9h à 18h.
Concepts clés à retenir
Avant de passer au prochain article, assurez-vous de bien comprendre :
Embedding
Représentation vectorielle de données (texte, image, audio) qui capture le sens sémantique.
"chat" → [0.12, -0.45, 0.78, ...] # 384 ou 1536 nombres
Similarité
Mesure de proximité entre vecteurs. La cosine similarity est la plus utilisée.
cosine_similarity(vec1, vec2) # Valeur entre -1 et 1
ANN (Approximate Nearest Neighbor)
Algorithme de recherche rapide mais approximative (95-99% précision) pour trouver les vecteurs les plus proches.
Trade-off : Vitesse 🆚 Précision exacte
Dimension
Taille du vecteur (nombre de nombres). Exemples :
- 384 : Sentence-BERT mini
- 768 : Sentence-BERT base
- 1536 : OpenAI text-embedding-3-small
- 3072 : OpenAI text-embedding-3-large
Top-K
Nombre de résultats les plus similaires à retourner.
results = db.search(query, top_k=5) # Retourne 5 meilleurs résultats
Quand utiliser une base vectorielle ?
✅ Utilisez une base vectorielle si :
- Vous construisez un système RAG (chatbot avec vos données)
- Vous faites de la recherche sémantique (sens, pas mots exacts)
- Vous créez un système de recommandation
- Vous travaillez avec des embeddings (texte, image, audio)
- Vous avez besoin de trouver des similarités dans de grandes quantités de données
❌ N’utilisez PAS de base vectorielle si :
- Recherche exacte suffit (
WHERE name = 'John') - Données purement structurées sans sémantique
- Très petit dataset (<1000 documents)
- Pas de modèle d’embedding disponible pour votre type de données
Aperçu de la série
Cette introduction n’est que le début ! Voici ce qui vous attend :
Articles suivants
Article 2 : Embeddings et similarité
- Modèles d’embedding (OpenAI, Sentence-BERT, Cohere)
- Métriques de similarité en profondeur
- Optimisation de la qualité des embeddings
Article 3 : Architecture et indexation
- Algorithmes HNSW, IVF, LSH
- Choisir le bon algorithme selon votre échelle
Articles 4-7 : Comparatif des Solutions
- Pinecone (cloud managed)
- Weaviate (open source hybride)
- Chroma (simple et local)
- Qdrant, Milvus, FAISS (alternatives)
Articles 8-9 : Production et RAG Avancé
- Déploiement production-ready
- Monitoring, scalabilité, optimisations
- Techniques RAG avancées (hybrid search, reranking)
Exercices pratiques
Installer Chroma et créer une collection
pip install chromadb
import chromadb
# Client local
client = chromadb.Client()
# Créer une collection
collection = client.create_collection("test")
# Ajouter des documents
collection.add(
documents=["Doc 1", "Doc 2"],
ids=["id1", "id2"]
)
# Rechercher
results = collection.query(
query_texts=["recherche"],
n_results=1
)
print(results)
Vectoriser 10 phrases
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = [
"Les chats sont mignons",
"Les chiens sont fidèles",
# ... 8 autres phrases
]
embeddings = model.encode(sentences)
print(f"Shape: {embeddings.shape}") # (10, 384)
Recherche sémantique
Combinez les exercices 1 et 2 pour :
- Vectoriser 10 phrases
- Les stocker dans Chroma
- Faire une recherche avec une nouvelle phrase
- Analyser les résultats
Conclusion
Les bases de données vectorielles sont le pilier de l’IA moderne. Elles permettent :
✅ Recherche sémantique : Trouver par sens, pas par mots exacts
✅ RAG puissant : Donner de la connaissance aux LLMs
✅ Recommandations : Trouver des similarités dans vos données
✅ Scalabilité : Gérer des millions de vecteurs efficacement
Dans le prochain article, nous plongerons dans les embeddings et métriques de similarité pour comprendre comment optimiser la qualité de vos recherches.
👉 Article 2 : Embeddings et similarité
Ressources complémentaires
Articles liés :
- Qu’est-ce qu’un Embedding ?
- Qu’est-ce qu’un Vecteur ?
- RAG (Retrieval-Augmented Generation)
- LangChain : Framework pour LLMs
Documentation officielle :
Outils recommandés :
- Sentence-Transformers : Modèles d’embedding open source
- OpenAI Embeddings API : Embeddings de qualité