Embeddings et métriques de similarité | Guide complet
Les embeddings sont le cœur des bases de données vectorielles. Sans de bons embeddings, impossible d’avoir une bonne recherche sémantique.
Dans cet article, nous allons maîtriser les embeddings, comprendre les métriques de similarité, et apprendre à optimiser la qualité de vos recherches.
Objectifs de l’article
Après avoir lu cet article, vous serez capable de :
- ✅ Comprendre les différents types d’embeddings
- ✅ Choisir le bon modèle d’embedding selon votre cas d’usage
- ✅ Maîtriser les métriques de similarité (cosine, dot product, euclidean)
- ✅ Optimiser la qualité de vos embeddings (chunking, métadonnées)
- ✅ Fine-tuner un modèle d’embedding pour votre domaine
Tout part des embeddings
Règle d’or :
Les embeddings sont la traduction de vos données (texte, images, audio) en un format que les ordinateurs peuvent comprendre et comparer : des vecteurs de nombres.
Qu’est-ce qu’un embedding ?
Définition technique
Un embedding est une représentation numérique dense qui capture le sens sémantique d’une information.
Exemple :
# Texte original
text = "Le roi gouverne le royaume"
# Embedding (vecteur de 384 nombres)
embedding = [0.234, -0.512, 0.891, -0.342, 0.621, ...]
Propriétés mathématiques
Les bons embeddings ont des propriétés intéressantes :
1. Similarité sémantique = Proximité vectorielle
distance("roi", "reine") < distance("roi", "voiture")
2. Opérations algébriques
"roi" - "homme" + "femme" ≈ "reine"
3. Clustering naturel
Les mots/concepts similaires se regroupent dans l’espace vectoriel.
Dimensions des embeddings
La dimension est le nombre de nombres dans le vecteur.
Trade-off : précision vs vitesse vs stockage
| Dimension | Précision | Vitesse | Stockage | Use Case |
|---|---|---|---|---|
| 128-384 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 0.5 KB | Prototypes, faible latence |
| 768-1024 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 3-4 KB | Optimal (recommandé) |
| 1536 | ⭐⭐⭐⭐ | ⭐⭐⭐ | 6 KB | Production qualité |
| 3072+ | ⭐⭐⭐⭐⭐ | ⭐⭐ | 12+ KB | Qualité maximale, coût élevé |
Calcul de stockage :
# Pour 1 million de vecteurs
dimension = 1536
vectors = 1_000_000
storage_mb = (dimension * 4 bytes * vectors) / (1024 * 1024)
print(f"Stockage : {storage_mb:.0f} MB") # ~5,860 MB ≈ 6 GB
Recommandation : Commencez avec 768 dimensions (Sentence-BERT base). C’est le meilleur compromis.
Modèles d’embedding pour texte
Voici les modèles les plus utilisés en 2025 :
Tableau comparatif complet
| Modèle | Dimension | Type | Performance | Prix | Langues | Use Case |
|---|---|---|---|---|---|---|
| OpenAI text-embedding-3-small | 1536 | API | ⭐⭐⭐⭐ | $0.02/1M tokens | 100+ | Production, API |
| OpenAI text-embedding-3-large | 3072 | API | ⭐⭐⭐⭐⭐ | $0.13/1M tokens | 100+ | Qualité max |
| Sentence-BERT all-MiniLM-L6-v2 | 384 | Local | ⭐⭐⭐ | Gratuit | EN | Prototypes, rapide |
| Sentence-BERT all-mpnet-base-v2 | 768 | Local | ⭐⭐⭐⭐ | Gratuit | EN | Production locale |
| BGE-base-en-v1.5 | 768 | Local | ⭐⭐⭐⭐ | Gratuit | EN | SOTA open source |
| E5-large-v2 | 1024 | Local | ⭐⭐⭐⭐ | Gratuit | 100+ | Multilingue |
| Cohere embed-multilingual-v3 | 1024 | API | ⭐⭐⭐⭐ | $0.10/1M tokens | 100+ | Multilingue, 100+ langues |
| Jina embeddings-v2 | 768 | Local/API | ⭐⭐⭐⭐ | Gratuit/API | 100+ | Long context (8K tokens) |
OpenAI Embeddings (API, payant)
Le plus simple et de très bonne qualité.
from openai import OpenAI
client = OpenAI(api_key="sk-...")
# Générer un embedding
response = client.embeddings.create(
model="text-embedding-3-small",
input="Les bases de données vectorielles sont puissantes"
)
embedding = response.data[0].embedding
print(f"Dimension : {len(embedding)}") # 1536
print(f"Type : {type(embedding)}") # list
Avantages :
- ✅ Très bonne qualité out-of-the-box
- ✅ Multilingue (100+ langues)
- ✅ Pas de modèle à héberger
Inconvénients :
- ❌ Coût (mais raisonnable : $0.02/1M tokens)
- ❌ Dépendance API
- ❌ Latence réseau
Batch processing (important pour économies) :
# Embedder plusieurs textes en un appel (plus efficace)
texts = [
"Texte 1",
"Texte 2",
# ... jusqu'à 2048 textes par batch
]
response = client.embeddings.create(
model="text-embedding-3-small",
input=texts # Liste de textes
)
embeddings = [item.embedding for item in response.data]
print(f"Nombre d'embeddings : {len(embeddings)}")
Sentence-BERT (local, gratuit)
Open source, exécutable localement sans API.
from sentence_transformers import SentenceTransformer
# Charger le modèle (téléchargé localement)
model = SentenceTransformer('all-mpnet-base-v2')
# Générer embeddings
texts = [
"Les bases de données vectorielles sont essentielles",
"La recherche sémantique révolutionne l'IA"
]
embeddings = model.encode(texts)
print(f"Shape : {embeddings.shape}") # (2, 768)
print(f"Type : {type(embeddings)}") # numpy.ndarray
Modèles recommandés :
# Rapide et léger (bon pour prototypes)
model_mini = SentenceTransformer('all-MiniLM-L6-v2') # 384 dim, 80MB
# Optimal (recommandé pour production)
model_base = SentenceTransformer('all-mpnet-base-v2') # 768 dim, 420MB
# Multilingue
model_multi = SentenceTransformer('paraphrase-multilingual-mpnet-base-v2') # 768 dim
Avantages :
- ✅ Gratuit et open source
- ✅ Exécution locale (pas de latence réseau)
- ✅ Privacy (données restent locales)
- ✅ Nombreux modèles spécialisés
Inconvénients :
- ❌ Nécessite GPU pour grande échelle
- ❌ Qualité légèrement inférieure à OpenAI
- ❌ Modèle à héberger/maintenir
Cohere embeddings (API, multilingue)
Excellente alternative à OpenAI, spécialisé multilingue.
import cohere
co = cohere.Client(api_key="...")
# Générer embeddings
response = co.embed(
texts=["Texte en français", "Text in English"],
model="embed-multilingual-v3.0",
input_type="search_document" # ou "search_query"
)
embeddings = response.embeddings
print(f"Dimension : {len(embeddings[0])}") # 1024
Avantages :
- ✅ Multilingue (100+ langues) de qualité
- ✅ Distinction document vs query (important !)
- ✅ Bon rapport qualité/prix
Inconvénients :
- ❌ Payant (mais compétitif)
- ❌ Dépendance API
Batch processing pour performance
Erreur courante : Générer embeddings un par un dans une boucle.
python # ❌ LENT : Boucle (100x plus lent) embeddings = [model.encode(text) for text in texts] # ✅ RAPIDE : Batch embeddings = model.encode(texts, batch_size=32)Benchmark : 1000 textes
import time
texts = ["Texte exemple"] * 1000
# Méthode lente (boucle)
start = time.time()
embeddings_slow = [model.encode(text) for text in texts]
time_slow = time.time() - start
# Méthode rapide (batch)
start = time.time()
embeddings_fast = model.encode(texts, batch_size=32)
time_fast = time.time() - start
print(f"Lent : {time_slow:.2f}s") # ~45s
print(f"Rapide : {time_fast:.2f}s") # ~0.5s
print(f"Speedup : {time_slow/time_fast:.0f}x") # 90x plus rapide !
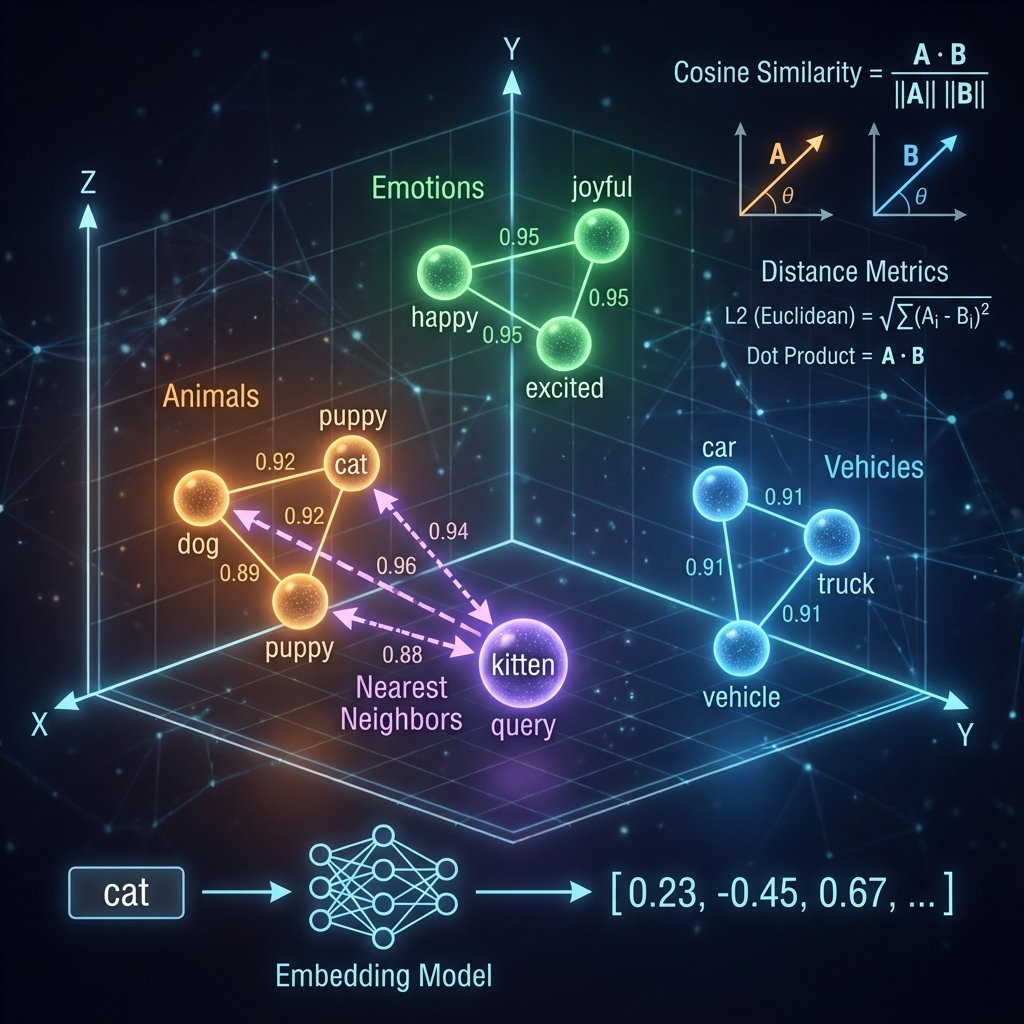
Métriques de similarité
Comment comparer deux vecteurs pour savoir s’ils sont similaires ?
Cosine Similarity (la plus utilisée)
Mesure l’angle entre deux vecteurs. Valeur entre -1 et 1.
Formule :
$$ \text{similarity} = \frac{A \cdot B}{||A|| \times ||B||} = \cos(\theta) $$
Code :
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# Deux vecteurs
vec1 = np.array([[0.5, 0.8, 0.2, 0.1]])
vec2 = np.array([[0.6, 0.7, 0.3, 0.2]])
similarity = cosine_similarity(vec1, vec2)[0][0]
print(f"Similarité : {similarity:.4f}") # Ex: 0.9823
Interprétation :
- 1.0 : Vecteurs identiques (même direction)
- 0.5 : Similaires (angle 60°)
- 0.0 : Orthogonaux (aucune relation)
- -1.0 : Opposés (180°)
Avantages :
- ✅ Invariant à la magnitude (norme)
- ✅ Très utilisé en NLP
- ✅ Intuitif (angle)
Inconvénients :
- ❌ Calcul légèrement plus lent que dot product
Dot Product
Produit scalaire simple.
Formule :
$$ \text{dot} = A \cdot B = \sum_{i=1}^{n} a_i \times b_i $$
Code :
import numpy as np
vec1 = np.array([0.5, 0.8, 0.2])
vec2 = np.array([0.6, 0.7, 0.3])
dot_product = np.dot(vec1, vec2)
print(f"Dot product : {dot_product:.4f}") # 0.92
Avantages :
- ✅ Très rapide à calculer
- ✅ Si vecteurs normalisés : dot product = cosine similarity
Inconvénients :
- ❌ Sensible à la magnitude
- ❌ Nécessite normalisation pour être équivalent à cosine
Normalisation :
from sklearn.preprocessing import normalize
# Normaliser (norme L2 = 1)
vec1_norm = normalize([vec1], norm='l2')[0]
vec2_norm = normalize([vec2], norm='l2')[0]
# Maintenant : dot product == cosine similarity
dot_normalized = np.dot(vec1_norm, vec2_norm)
cosine = cosine_similarity([vec1], [vec2])[0][0]
print(f"Dot (normalized) : {dot_normalized:.4f}")
print(f"Cosine : {cosine:.4f}")
# Identiques !
Euclidean distance
Distance géométrique classique.
Formule :
$$ \text{distance} = \sqrt{\sum_{i=1}^{n} (a_i - b_i)^2} $$
Code :
from scipy.spatial.distance import euclidean
vec1 = np.array([0.5, 0.8, 0.2])
vec2 = np.array([0.6, 0.7, 0.3])
distance = euclidean(vec1, vec2)
print(f"Distance : {distance:.4f}") # 0.1732
Interprétation :
- 0 : Vecteurs identiques
- Plus grand : Vecteurs plus différents
Avantages :
- ✅ Intuitif (distance géométrique)
- ✅ Utile pour clustering
Inconvénients :
- ❌ Sensible à la magnitude
- ❌ Moins utilisé que cosine en NLP
Manhattan Distance (L1)
Somme des différences absolues.
from scipy.spatial.distance import cityblock
distance_l1 = cityblock(vec1, vec2)
print(f"Manhattan distance : {distance_l1:.4f}")
Use case : Rarement utilisée en recherche sémantique.
Choisir la bonne métrique
| Use Case | Métrique Recommandée | Raison |
|---|---|---|
| Recherche sémantique texte | Cosine | Invariant à longueur |
| Recherche d’images | Cosine ou Dot | Selon normalisation |
| Recommandation | Cosine | Compare préférences |
| Clustering | Euclidean | Distances géométriques |
| Recherche vocale | Cosine | Invariant à volume |
| Performance critique | Dot (avec normalisation) | Le plus rapide |
Recommandation générale : Utilisez cosine similarity pour le texte. C’est le standard de facto.
Optimiser la qualité des embeddings
Chunking Intelligent
La taille des chunks (morceaux de texte) est cruciale.
Problème
Trop petit (50 tokens) :
- ❌ Perte de contexte
- ❌ Sens incomplet
Trop grand (1000+ tokens) :
- ❌ Dilution du sens
- ❌ Bruit informationnel
Solution : taille optimale
# Règle générale
OPTIMAL_CHUNK_SIZE = 300 # tokens (~200-500 selon cas)
CHUNK_OVERLAP = 50 # 10-20% overlap
Code : Chunking avec Overlap
def chunk_text(text: str, chunk_size: int = 300, overlap: int = 50) -> list[str]:
"""
Découper texte en chunks avec overlap.
Args:
text: Texte à découper
chunk_size: Taille en mots (approximation de tokens)
overlap: Overlap en mots
Returns:
Liste de chunks
"""
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunk = ' '.join(words[i:i + chunk_size])
if len(chunk.strip()) > 0:
chunks.append(chunk)
return chunks
# Exemple
long_text = "..." * 1000 # Texte long
chunks = chunk_text(long_text, chunk_size=300, overlap=50)
print(f"Nombre de chunks : {len(chunks)}")
print(f"Premier chunk : {chunks[0][:100]}...")
Chunking sémantique (avancé)
Découper par paragraphes ou phrases au lieu de taille fixe :
def semantic_chunk(text: str, max_tokens: int = 500) -> list[str]:
"""Découper par paragraphes avec limite de tokens."""
import re
# Découper par paragraphes
paragraphs = text.split('\n\n')
chunks = []
current_chunk = []
current_size = 0
for para in paragraphs:
para_size = len(para.split()) # Approximation tokens
if current_size + para_size > max_tokens and current_chunk:
# Sauvegarder chunk actuel
chunks.append('\n\n'.join(current_chunk))
current_chunk = [para]
current_size = para_size
else:
current_chunk.append(para)
current_size += para_size
# Dernier chunk
if current_chunk:
chunks.append('\n\n'.join(current_chunk))
return chunks
Enrichir avec métadonnées
Ajouter du contexte avant de générer l’embedding.
def enrich_text(text: str, metadata: dict) -> str:
"""
Enrichir texte avec métadonnées.
Args:
text: Texte original
metadata: Métadonnées (title, category, date, etc.)
Returns:
Texte enrichi
"""
parts = []
# Ajouter titre
if 'title' in metadata:
parts.append(f"Titre: {metadata['title']}")
# Ajouter catégorie
if 'category' in metadata:
parts.append(f"Catégorie: {metadata['category']}")
# Ajouter date
if 'date' in metadata:
parts.append(f"Date: {metadata['date']}")
# Texte original
parts.append(text)
return '\n'.join(parts)
# Exemple
text = "PyTorch est un framework de deep learning."
metadata = {
'title': "Introduction à PyTorch",
'category': "Deep Learning",
'date': "2025-01-15"
}
enriched = enrich_text(text, metadata)
print(enriched)
Output :
Titre: Introduction à PyTorch
Catégorie: Deep Learning
Date: 2025-01-15
PyTorch est un framework de deep learning.
Résultat : Embeddings plus riches et contextualisés !
Normalisation
Normaliser les vecteurs permet d’utiliser dot product au lieu de cosine similarity (plus rapide).
from sklearn.preprocessing import normalize
import numpy as np
# Embeddings originaux
embeddings = model.encode(texts) # (N, 768)
# Normaliser (norme L2 = 1)
embeddings_normalized = normalize(embeddings, norm='l2')
# Vérification
norms = np.linalg.norm(embeddings_normalized, axis=1)
print(f"Normes après normalisation : {norms[:5]}")
# [1. 1. 1. 1. 1.]
# Maintenant : dot product == cosine similarity !
similarity_cosine = cosine_similarity([embeddings[0]], [embeddings[1]])[0][0]
similarity_dot = np.dot(embeddings_normalized[0], embeddings_normalized[1])
print(f"Cosine : {similarity_cosine:.4f}")
print(f"Dot (normalized) : {similarity_dot:.4f}")
# Identiques !
Fine-tuning de modèles d’embedding
Pour améliorer la qualité sur votre domaine spécifique (médical, juridique, technique).
Fine-Tuner Sentence-BERT
from sentence_transformers import SentenceTransformer, InputExample, losses
from torch.utils.data import DataLoader
# 1. Charger modèle de base
model = SentenceTransformer('all-mpnet-base-v2')
# 2. Préparer données d'entraînement
# Format : paires (query, document positif)
train_examples = [
InputExample(
texts=['Symptômes COVID-19', 'Le COVID-19 provoque fièvre, toux et fatigue'],
label=1.0 # Similaires
),
InputExample(
texts=['Traitement diabète', 'Le diabète se traite avec insuline'],
label=1.0
),
# ... plus d'exemples
]
# 3. DataLoader
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)
# 4. Loss function
train_loss = losses.CosineSimilarityLoss(model)
# 5. Fine-tuning
model.fit(
train_objectives=[(train_dataloader, train_loss)],
epochs=3,
warmup_steps=100,
output_path='./model_finetuned'
)
# 6. Utiliser le modèle fine-tuné
model_custom = SentenceTransformer('./model_finetuned')
Amélioration attendue : +10-30% de pertinence sur votre domaine !
Évaluer la qualité des embeddings
Métriques clés
Recall@K
Pourcentage de documents pertinents trouvés dans les top-K résultats.
def recall_at_k(query_embedding, doc_embeddings, relevant_docs, k=5):
"""
Calculer Recall@K.
Args:
query_embedding: Vecteur de la requête
doc_embeddings: Vecteurs de tous les documents
relevant_docs: Liste des indices des documents pertinents
k: Nombre de résultats à considérer
Returns:
Recall@K (0.0 à 1.0)
"""
# Calculer similarités
similarities = cosine_similarity([query_embedding], doc_embeddings)[0]
# Top-K indices
top_k_indices = np.argsort(similarities)[-k:][::-1]
# Combien de pertinents dans top-K ?
relevant_found = sum(1 for idx in top_k_indices if idx in relevant_docs)
# Recall
recall = relevant_found / len(relevant_docs)
return recall
# Exemple
query_emb = embeddings[0]
doc_embs = embeddings[1:]
relevant = [2, 5, 8] # Indices des docs pertinents
recall_5 = recall_at_k(query_emb, doc_embs, relevant, k=5)
print(f"Recall@5 : {recall_5:.2%}") # Ex: 66.67%
MRR (Mean Reciprocal Rank)
Position du premier résultat pertinent.
def mrr(query_embedding, doc_embeddings, relevant_docs):
"""Calculer MRR."""
similarities = cosine_similarity([query_embedding], doc_embeddings)[0]
ranked_indices = np.argsort(similarities)[::-1]
# Trouver premier pertinent
for rank, idx in enumerate(ranked_indices, start=1):
if idx in relevant_docs:
return 1.0 / rank
return 0.0 # Aucun pertinent trouvé
Interprétation :
- 1.0 : Premier résultat est pertinent
- 0.5 : Premier pertinent est en 2ème position
- 0.1 : Premier pertinent est en 10ème position
Embeddings multilingues
Pour supporter plusieurs langues dans le même espace vectoriel.
Modèles recommandés
# Sentence-BERT multilingue
model_multi = SentenceTransformer('paraphrase-multilingual-mpnet-base-v2')
# Textes en différentes langues
texts = [
"Hello, how are you?", # English
"Bonjour, comment allez-vous ?", # Français
"Hola, ¿cómo estás?", # Español
]
embeddings = model_multi.encode(texts)
# Calculer similarités cross-lingues
sim_en_fr = cosine_similarity([embeddings[0]], [embeddings[1]])[0][0]
sim_en_es = cosine_similarity([embeddings[0]], [embeddings[2]])[0][0]
print(f"EN-FR : {sim_en_fr:.4f}") # ~0.85
print(f"EN-ES : {sim_en_es:.4f}") # ~0.83
Use case : Requête en français → résultats en anglais/espagnol !
Dimensionality Reduction (avancé)
Réduire la dimension pour économiser stockage et accélérer recherche.
PCA (Principal Component Analysis)
from sklearn.decomposition import PCA
# Embeddings originaux (1536 dim)
embeddings_original = model.encode(texts) # (N, 1536)
# Réduire à 256 dimensions
pca = PCA(n_components=256)
embeddings_reduced = pca.fit_transform(embeddings_original)
print(f"Original : {embeddings_original.shape}") # (N, 1536)
print(f"Reduced : {embeddings_reduced.shape}") # (N, 256)
# Variance expliquée
variance_ratio = pca.explained_variance_ratio_.sum()
print(f"Variance conservée : {variance_ratio:.2%}") # Ex: 92%
Trade-off :
- ✅ Stockage : 6× moins (1536 → 256)
- ✅ Vitesse : 6× plus rapide
- ❌ Qualité : ~8% de perte
Pièges à éviter
❌ Mélanger modèles d’embedding
# ❌ ERREUR : Comparer embeddings de modèles différents
embedding_openai = openai.embed("texte")
embedding_sbert = sbert_model.encode("texte")
similarity = cosine_similarity([embedding_openai], [embedding_sbert])
# ⚠️ Résultat non significatif !
Règle : Tous les embeddings doivent venir du même modèle.
❌ Oublier la normalisation
# ❌ Utiliser dot product sans normalisation
similarity = np.dot(vec1, vec2) # Sensible à magnitude
# ✅ Normaliser d'abord
vec1_norm = vec1 / np.linalg.norm(vec1)
vec2_norm = vec2 / np.linalg.norm(vec2)
similarity = np.dot(vec1_norm, vec2_norm) # OK
❌ Chunks trop grands/petits
Trop petits : Perte de contexte Trop grands : Dilution du sens
Optimal : 200-500 tokens avec 10-20% overlap
❌ Ignorer le contexte
# ❌ Texte brut sans contexte
embedding = model.encode("PyTorch est un framework")
# ✅ Enrichir avec métadonnées
enriched = "Titre: Introduction Deep Learning. Catégorie: IA. PyTorch est un framework"
embedding = model.encode(enriched)
Conclusion
Les embeddings sont le cœur des bases vectorielles. Leur qualité détermine directement la pertinence de vos recherches.
Points clés à retenir
✅ Choisir le bon modèle selon votre budget et besoins :
- OpenAI : Simple, qualité, payant
- Sentence-BERT : Gratuit, local, très bon
- Cohere : Multilingue, API, compétitif
✅ Utiliser cosine similarity pour recherche sémantique de texte
✅ Optimiser chunking : 200-500 tokens, 10-20% overlap
✅ Enrichir avec métadonnées pour plus de contexte
✅ Batch processing pour performance (90× plus rapide)
✅ Normaliser pour utiliser dot product (plus rapide)
Dans le prochain article, nous plongerons dans les algorithmes d’indexation (HNSW, IVF) qui rendent la recherche ultra-rapide.
👉 Article 3 : architecture et algorithmes d’indexation
Embeddings pour images
Au-delà du texte, les embeddings peuvent représenter des images.
CLIP (OpenAI)
CLIP (Contrastive Language-Image Pre-training) encode texte ET images dans le même espace vectoriel.
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import torch
# Charger modèle CLIP
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# Image
image = Image.open("chat.jpg")
# Textes à comparer
texts = ["un chat", "un chien", "une voiture"]
# Encoder image et textes
inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
# Similarités image-texte
logits_per_image = outputs.logits_per_image
probs = logits_per_image.softmax(dim=1)
print(f"Probabilités : {probs}")
# [[0.85, 0.10, 0.05]] -> "un chat" le plus probable
Use cases :
- Recherche d’images par texte
- Classification zero-shot
- Recherche visuelle sémantique
ResNet et Vision Transformers
Pour des embeddings purement visuels :
from transformers import ViTFeatureExtractor, ViTModel
from PIL import Image
# Charger Vision Transformer
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224')
model = ViTModel.from_pretrained('google/vit-base-patch16-224')
# Charger image
image = Image.open("photo.jpg")
# Extraire features
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
# Embedding de l'image (768 dimensions)
image_embedding = outputs.last_hidden_state[:, 0].detach().numpy()
print(f"Shape : {image_embedding.shape}") # (1, 768)
Modèles populaires :
- CLIP : Text + Image (512 dim)
- ViT (Vision Transformer) : Images (768 dim)
- ResNet-50 : Images (2048 dim)
- EfficientNet : Images (variable)
Embeddings pour audio
Whisper Embeddings
Utiliser Whisper (OpenAI) pour encoder de l’audio :
import whisper
import numpy as np
# Charger modèle Whisper
model = whisper.load_model("base")
# Charger audio
audio = whisper.load_audio("audio.mp3")
audio = whisper.pad_or_trim(audio)
# Générer mel spectrogram
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# Extraire embeddings
with torch.no_grad():
embeddings = model.embed_audio(mel)
print(f"Audio embedding shape : {embeddings.shape}")
Use cases :
- Recherche sémantique dans podcasts
- Détection de similarité audio
- Classification de sons
Audio Embeddings avec CLAP
CLAP (Contrastive Language-Audio Pretraining) : équivalent de CLIP pour l’audio.
from transformers import ClapModel, ClapProcessor
model = ClapModel.from_pretrained("laion/clap-htsat-unfused")
processor = ClapProcessor.from_pretrained("laion/clap-htsat-unfused")
# Texte décrivant l'audio
texts = ["bruit de pluie", "chien qui aboie", "guitare acoustique"]
# Audio
audio = load_audio("sample.wav")
# Encoder
inputs = processor(text=texts, audios=audio, return_tensors="pt", padding=True)
outputs = model(**inputs)
# Similarités audio-texte
logits_per_audio = outputs.logits_per_audio
probs = logits_per_audio.softmax(dim=1)
Caching et réutilisation des embeddings
Générer des embeddings est coûteux (temps + argent). Il faut les cacher !
Sauvegarder les embeddings
import numpy as np
import json
# Générer embeddings
texts = ["texte 1", "texte 2", "texte 3"]
embeddings = model.encode(texts)
# Sauvegarder en NumPy
np.save('embeddings.npy', embeddings)
# Sauvegarder métadonnées
metadata = {
'model': 'all-mpnet-base-v2',
'dimension': 768,
'count': len(texts),
'texts': texts
}
with open('metadata.json', 'w') as f:
json.dump(metadata, f)
print("✅ Embeddings sauvegardés")
Charger les embeddings
# Charger embeddings
embeddings = np.load('embeddings.npy')
# Charger métadonnées
with open('metadata.json', 'r') as f:
metadata = json.load(f)
print(f"Loaded {metadata['count']} embeddings")
print(f"Model : {metadata['model']}")
print(f"Dimension : {metadata['dimension']}")
Cache avec hash
Pour éviter de générer plusieurs fois le même embedding :
import hashlib
import pickle
from pathlib import Path
class EmbeddingCache:
def __init__(self, cache_dir='./embedding_cache'):
self.cache_dir = Path(cache_dir)
self.cache_dir.mkdir(exist_ok=True)
def _hash_text(self, text: str) -> str:
"""Générer hash MD5 du texte."""
return hashlib.md5(text.encode()).hexdigest()
def get(self, text: str):
"""Récupérer embedding du cache."""
hash_key = self._hash_text(text)
cache_file = self.cache_dir / f"{hash_key}.pkl"
if cache_file.exists():
with open(cache_file, 'rb') as f:
return pickle.load(f)
return None
def set(self, text: str, embedding):
"""Sauvegarder embedding dans cache."""
hash_key = self._hash_text(text)
cache_file = self.cache_dir / f"{hash_key}.pkl"
with open(cache_file, 'wb') as f:
pickle.dump(embedding, f)
def get_or_compute(self, text: str, model):
"""Récupérer du cache ou générer."""
embedding = self.get(text)
if embedding is None:
# Générer
embedding = model.encode(text)
# Cacher
self.set(text, embedding)
print(f"✨ Generated new embedding")
else:
print(f"✅ Loaded from cache")
return embedding
# Utilisation
cache = EmbeddingCache()
model = SentenceTransformer('all-mpnet-base-v2')
# Premier appel : génère
emb1 = cache.get_or_compute("Hello world", model) # ✨ Generated
# Deuxième appel : cache !
emb2 = cache.get_or_compute("Hello world", model) # ✅ Loaded from cache
Gains : 100× plus rapide pour textes déjà encodés !
Embeddings sparse vs dense
Il existe deux types d’embeddings : dense et sparse.
Dense Embeddings (ce qu’on a vu)
Vecteurs denses : tous les éléments ont une valeur.
# Dense embedding (768 dimensions)
dense = [0.234, -0.512, 0.891, -0.342, 0.621, ...]
# 768 valeurs, toutes non-nulles
Caractéristiques :
- ✅ Capture le sens sémantique
- ✅ Performant pour similarité
- ❌ Coûteux en stockage
- ❌ Nécessite modèle ML
Use case : Recherche sémantique, RAG, recommandation
Sparse embeddings
Vecteurs sparse : la plupart des éléments sont 0.
# Sparse embedding (ex: 30,000 dimensions)
sparse = {
145: 0.52, # "paris"
892: 0.31, # "france"
1203: 0.19, # "capitale"
# ... le reste est 0
}
Méthode classique : BM25 (Bag-of-Words amélioré)
Caractéristiques :
- ✅ Très efficace en stockage (format sparse)
- ✅ Pas besoin de modèle ML
- ✅ Recherche de mots-clés exacts
- ❌ Pas de compréhension sémantique
Use case : Recherche par mots-clés, filtrage lexical
Hybrid Search : Le meilleur des deux mondes
Combiner dense (sémantique) + sparse (mots-clés).
from rank_bm25 import BM25Okapi
from sentence_transformers import SentenceTransformer
import numpy as np
# Documents
docs = [
"Paris est la capitale de la France",
"Tokyo est la capitale du Japon",
"Berlin est la capitale de l'Allemagne"
]
# 1. Dense embeddings
model_dense = SentenceTransformer('all-mpnet-base-v2')
dense_embeddings = model_dense.encode(docs)
# 2. Sparse embeddings (BM25)
tokenized_docs = [doc.lower().split() for doc in docs]
bm25 = BM25Okapi(tokenized_docs)
# Requête
query = "capitale française"
# 3. Dense search
query_dense = model_dense.encode(query)
dense_scores = cosine_similarity([query_dense], dense_embeddings)[0]
# 4. Sparse search (BM25)
query_tokens = query.lower().split()
sparse_scores = bm25.get_scores(query_tokens)
# 5. Combiner les scores (weighted)
alpha = 0.7 # Poids pour dense
final_scores = alpha * dense_scores + (1 - alpha) * sparse_scores
# 6. Résultats
best_idx = np.argmax(final_scores)
print(f"Meilleur résultat : {docs[best_idx]}")
# "Paris est la capitale de la France"
Avantages Hybrid Search :
- ✅ Dense trouve “capitale française” → “Paris capitale France”
- ✅ Sparse trouve correspondances exactes de mots
- ✅ Meilleure précision globale
Implémentation dans bases vectorielles :
- Weaviate : Hybrid search natif
- Qdrant : Supporte sparse + dense
- Pinecone : Via metadata filtering + semantic
Comparaison détaillée des fournisseurs d’API
Tableau complet 2025
| Fournisseur | Modèle | Dimension | Prix (/1M tokens) | Langues | Context | Performance | Latence |
|---|---|---|---|---|---|---|---|
| OpenAI | text-embedding-3-small | 1536 | $0.020 | 100+ | 8191 | ⭐⭐⭐⭐ | ~200ms |
| OpenAI | text-embedding-3-large | 3072 | $0.130 | 100+ | 8191 | ⭐⭐⭐⭐⭐ | ~300ms |
| Cohere | embed-multilingual-v3 | 1024 | $0.100 | 100+ | 512 | ⭐⭐⭐⭐ | ~150ms |
| Cohere | embed-english-v3 | 1024 | $0.100 | EN | 512 | ⭐⭐⭐⭐ | ~150ms |
| Voyage AI | voyage-2 | 1024 | $0.100 | 100+ | 4000 | ⭐⭐⭐⭐ | ~180ms |
| Jina AI | jina-embeddings-v2 | 768 | $0.020 | 100+ | 8192 | ⭐⭐⭐⭐ | ~120ms |
| Mistral | mistral-embed | 1024 | $0.100 | FR/EN | 8000 | ⭐⭐⭐⭐ | ~250ms |
| textembedding-gecko | 768 | $0.025 | 100+ | 3072 | ⭐⭐⭐⭐ | ~200ms |
Recommandations par cas d’usage
Budget serré, bon volume : → OpenAI text-embedding-3-small ($0.02/1M)
Qualité maximale, budget flexible : → OpenAI text-embedding-3-large ($0.13/1M)
Multilingue, contexte long : → Jina AI jina-embeddings-v2 (8K context)
Français prioritaire : → Mistral mistral-embed (optimisé FR)
Gratuit, local, privacy : → Sentence-BERT all-mpnet-base-v2
Calcul du coût réel
def estimate_embedding_cost(
num_documents: int,
avg_tokens_per_doc: int,
model_price_per_1m: float
):
"""
Estimer le coût d'embedding.
Args:
num_documents: Nombre de documents
avg_tokens_per_doc: Tokens moyens par document
model_price_per_1m: Prix par 1M tokens
Returns:
Coût estimé en dollars
"""
total_tokens = num_documents * avg_tokens_per_doc
cost = (total_tokens / 1_000_000) * model_price_per_1m
return cost
# Exemple : 100K documents, 500 tokens/doc
cost_openai_small = estimate_embedding_cost(
num_documents=100_000,
avg_tokens_per_doc=500,
model_price_per_1m=0.02 # OpenAI small
)
cost_openai_large = estimate_embedding_cost(
num_documents=100_000,
avg_tokens_per_doc=500,
model_price_per_1m=0.13 # OpenAI large
)
print(f"OpenAI small : ${cost_openai_small:.2f}") # $1.00
print(f"OpenAI large : ${cost_openai_large:.2f}") # $6.50
print(f"Sentence-BERT : $0.00 (local)") # Gratuit !
Cas pratique complet : Système de recherche documentaire
Voici un exemple end-to-end complet.
Scénario
Créer un moteur de recherche pour une base de connaissance de 1000 articles.
Code complet
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
import json
from pathlib import Path
class DocumentSearchEngine:
def __init__(self, model_name='all-mpnet-base-v2'):
"""Initialiser le moteur de recherche."""
self.model = SentenceTransformer(model_name)
self.documents = []
self.embeddings = None
def add_documents(self, documents: list[dict]):
"""
Ajouter documents à l'index.
Args:
documents: Liste de dicts avec 'id', 'title', 'content', 'metadata'
"""
self.documents = documents
# Préparer textes pour embedding
texts_to_embed = []
for doc in documents:
# Enrichir avec métadonnées
text = f"Titre: {doc['title']}\n\n{doc['content']}"
texts_to_embed.append(text)
# Générer embeddings
print(f"Génération de {len(texts_to_embed)} embeddings...")
self.embeddings = self.model.encode(
texts_to_embed,
batch_size=32,
show_progress_bar=True
)
# Normaliser pour utiliser dot product
from sklearn.preprocessing import normalize
self.embeddings = normalize(self.embeddings, norm='l2')
print(f"✅ {len(self.embeddings)} embeddings générés")
def search(self, query: str, top_k: int = 5) -> list[dict]:
"""
Rechercher documents pertinents.
Args:
query: Requête de recherche
top_k: Nombre de résultats
Returns:
Liste de résultats avec scores
"""
# Encoder la requête
query_embedding = self.model.encode(query)
# Normaliser
from sklearn.preprocessing import normalize
query_embedding = normalize([query_embedding], norm='l2')[0]
# Calculer similarités (dot product car normalisé)
similarities = np.dot(self.embeddings, query_embedding)
# Top-K indices
top_indices = np.argsort(similarities)[-top_k:][::-1]
# Préparer résultats
results = []
for idx in top_indices:
results.append({
'document': self.documents[idx],
'score': float(similarities[idx]),
'rank': len(results) + 1
})
return results
def save(self, path: str):
"""Sauvegarder l'index."""
save_path = Path(path)
save_path.mkdir(exist_ok=True)
# Sauvegarder embeddings
np.save(save_path / 'embeddings.npy', self.embeddings)
# Sauvegarder documents
with open(save_path / 'documents.json', 'w', encoding='utf-8') as f:
json.dump(self.documents, f, ensure_ascii=False, indent=2)
print(f"✅ Index sauvegardé dans {path}")
def load(self, path: str):
"""Charger l'index."""
load_path = Path(path)
# Charger embeddings
self.embeddings = np.load(load_path / 'embeddings.npy')
# Charger documents
with open(load_path / 'documents.json', 'r', encoding='utf-8') as f:
self.documents = json.load(f)
print(f"✅ Index chargé : {len(self.documents)} documents")
# === UTILISATION ===
# 1. Créer des documents
documents = [
{
'id': 1,
'title': 'Introduction à PyTorch',
'content': 'PyTorch est un framework de deep learning développé par Meta...',
'metadata': {'category': 'Deep Learning', 'date': '2025-01-15'}
},
{
'id': 2,
'title': 'RAG avec LangChain',
'content': 'Le RAG (Retrieval-Augmented Generation) combine recherche et génération...',
'metadata': {'category': 'LLM', 'date': '2025-01-20'}
},
# ... plus de documents
]
# 2. Créer et indexer
engine = DocumentSearchEngine()
engine.add_documents(documents)
# 3. Rechercher
results = engine.search("comment utiliser pytorch pour deep learning", top_k=3)
# 4. Afficher résultats
for result in results:
print(f"\n📄 Rang {result['rank']} - Score: {result['score']:.4f}")
print(f" Titre: {result['document']['title']}")
print(f" Extrait: {result['document']['content'][:100]}...")
# 5. Sauvegarder pour réutilisation
engine.save('./search_index')
# 6. Charger plus tard
engine2 = DocumentSearchEngine()
engine2.load('./search_index')
Output exemple :
📄 Rang 1 - Score: 0.8721
Titre: Introduction à PyTorch
Extrait: PyTorch est un framework de deep learning développé par Meta...
📄 Rang 2 - Score: 0.6543
Titre: Guide TensorFlow
Extrait: TensorFlow est une alternative populaire pour le deep learning...
Embeddings contextuels vs statiques
Embeddings statiques (Word2Vec, GloVe)
Chaque mot a un seul vecteur, quel que soit le contexte.
# "bank" a toujours le même embedding
# → Problème : "river bank" vs "money bank"
Limites :
- ❌ Pas de gestion de polysémie
- ❌ Pas de contexte
Embeddings contextuels (BERT, GPT, modernes)
Chaque mot a un embedding différent selon le contexte.
from transformers import AutoTokenizer, AutoModel
import torch
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# Deux phrases avec "bank"
sentence1 = "I walked along the river bank"
sentence2 = "I went to the bank to withdraw money"
# Encoder
inputs1 = tokenizer(sentence1, return_tensors="pt")
inputs2 = tokenizer(sentence2, return_tensors="pt")
# Embeddings contextuels
with torch.no_grad():
outputs1 = model(**inputs1)
outputs2 = model(**inputs2)
# "bank" aura des embeddings DIFFÉRENTS !
# Car le contexte est différent
Avantages :
- ✅ Gestion de la polysémie
- ✅ Compréhension du contexte
- ✅ Plus précis
Tous les modèles modernes (Sentence-BERT, OpenAI, Cohere) sont contextuels.
Exercices pratiques
Comparer 3 modèles
Générez des embeddings pour le même texte avec 3 modèles différents et comparez les dimensions et performances.
Mesurer Recall@K
Créez un mini-dataset avec 100 documents et 10 requêtes. Mesurez Recall@5 et Recall@10.
Chunking intelligent
Implémentez une fonction de chunking qui :
- Découpe par paragraphes
- Respecte une limite de tokens
- Ajoute 15% d’overlap
FAQ : Questions fréquentes
Quelle est la différence entre un embedding et un vecteur ?
Un embedding est un type spécifique de vecteur : c’est une représentation numérique dense qui capture le sens sémantique d’une donnée (texte, image, audio).
Tous les embeddings sont des vecteurs, mais tous les vecteurs ne sont pas des embeddings sémantiques.
Puis-je utiliser des embeddings générés avec différents modèles ensemble ?
❌ NON ! C’est une erreur fréquente.
Les embeddings doivent toujours provenir du même modèle pour être comparables.
# ❌ ERREUR
emb_openai = openai.embed("texte")
emb_sbert = sbert.encode("texte")
similarity = cosine_similarity([emb_openai], [emb_sbert]) # Non significatif !
# ✅ CORRECT
emb1 = sbert.encode("texte 1")
emb2 = sbert.encode("texte 2")
similarity = cosine_similarity([emb1], [emb2]) # OK !
Quelle métrique de similarité choisir ?
Pour 99% des cas : Cosine Similarity !
Elle est invariante à la magnitude et parfaite pour le texte.
Combien coûte la génération d’embeddings ?
Exemples de coûts (100K documents, 500 tokens/doc) :
- OpenAI small : ~$1.00
- OpenAI large : ~$6.50
- Cohere : ~$5.00
- Sentence-BERT local : $0 (gratuit, mais coût serveur/GPU)
Quelle taille de chunk optimale ?
Recommandation générale : 300 tokens (environ 200-400 mots)
Avec 15-20% d’overlap entre chunks.
CHUNK_SIZE = 300 # tokens
OVERLAP = 50 # tokens (15-20%)
Dois-je normaliser mes embeddings ?
Ça dépend :
- Si vous utilisez cosine similarity : pas besoin
- Si vous utilisez dot product : OUI, normalisez (L2)
- Si vous utilisez une base vectorielle : vérifiez la documentation
Comment améliorer la qualité de mes embeddings ?
5 techniques :
- Chunking intelligent : 300 tokens, overlap 15%
- Enrichir avec métadonnées : ajouter titre, catégorie, date
- Fine-tuner le modèle sur votre domaine
- Utiliser un modèle plus puissant (ex: large vs small)
- Hybrid search : combiner dense + sparse (BM25)
Les embeddings sont-ils sensibles à la langue ?
Modèles monolingues : OUI
- Sentence-BERT
all-MiniLM-L6-v2: Anglais uniquement
Modèles multilingues : NON
- OpenAI
text-embedding-3-*: 100+ langues - Sentence-BERT
paraphrase-multilingual-*: 50+ langues
Vérifiez toujours la documentation du modèle !
Comment gérer les textes plus longs que la limite du modèle ?
3 stratégies :
- Chunking : découper en morceaux (recommandé)
- Truncation : couper à la limite (perte d’info)
- Summarization : résumer d’abord avec LLM, puis embedder
# Chunking recommandé
chunks = chunk_text(long_text, chunk_size=300, overlap=50)
embeddings = model.encode(chunks)
Puis-je réduire la dimension des embeddings ?
OUI, avec PCA ou UMAP :
from sklearn.decomposition import PCA
# Réduire 1536 → 256 dimensions
pca = PCA(n_components=256)
embeddings_reduced = pca.fit_transform(embeddings_original)
# Trade-off : ~85-95% de variance conservée
Trade-off :
- ✅ 6× moins de stockage
- ✅ 6× plus rapide
- ❌ ~5-15% de perte de qualité
Comment savoir si mes embeddings sont de bonne qualité ?
Métriques d’évaluation :
- Recall@K : % de documents pertinents dans top-K
- MRR (Mean Reciprocal Rank) : position du 1er pertinent
- NDCG : qualité du ranking
Test manuel :
- Cherchez des requêtes typiques
- Vérifiez les résultats
- Ajustez chunking/enrichissement
Est-ce que je dois régénérer les embeddings si je change de modèle ?
OUI ! Absolument.
Les embeddings sont spécifiques au modèle. Si vous changez de modèle, vous devez tout régénérer.
C’est pourquoi le choix du modèle est crucial dès le début.
Troubleshooting : Erreurs fréquentes
Erreur : “OutOfMemoryError” lors du batch encoding
Symptôme :
torch.cuda.OutOfMemoryError: CUDA out of memory
Cause : Batch trop grand pour la mémoire GPU
Solution : Réduire le batch size
# ❌ Batch trop grand
embeddings = model.encode(texts, batch_size=128) # OOM !
# ✅ Batch réduit
embeddings = model.encode(texts, batch_size=16) # OK
Erreur : Résultats de recherche non pertinents
Cause possible 1 : Chunks trop grands/petits
Solution :
# Ajuster la taille des chunks
CHUNK_SIZE = 300 # Essayer 200, 300, 500
Cause possible 2 : Pas assez de contexte
Solution : Enrichir avec métadonnées
enriched = f"Titre: {title}\nCatégorie: {category}\n\n{content}"
Cause possible 3 : Modèle inadapté
Solution : Tester un autre modèle (ex: all-mpnet-base-v2 → OpenAI)
Erreur : Similarités toujours très élevées (>0.9)
Cause : Vecteurs non normalisés + confusion métrique
Solution :
from sklearn.preprocessing import normalize
# Normaliser
embeddings = normalize(embeddings, norm='l2')
# Utiliser cosine similarity
similarity = cosine_similarity([emb1], [emb2])
Erreur : Performance lente lors de la recherche
Cause : Recherche linéaire sur grand dataset
Solutions :
- Normaliser et utiliser dot product (plus rapide)
embeddings_norm = normalize(embeddings, norm='l2')
scores = np.dot(embeddings_norm, query_norm) # Rapide !
- Utiliser une vraie base vectorielle (Pinecone, Weaviate, Qdrant)
- Algorithmes optimisés (HNSW, IVF)
- 100× - 1000× plus rapide
- Réduire les dimensions (PCA)
Erreur : Embeddings ne capturent pas le sens spécifique à mon domaine
Cause : Modèle généraliste pas adapté à votre domaine (médical, juridique, etc.)
Solution : Fine-tuner sur votre domaine
from sentence_transformers import SentenceTransformer, InputExample, losses
# Charger modèle base
model = SentenceTransformer('all-mpnet-base-v2')
# Préparer exemples de votre domaine
train_examples = [
InputExample(texts=['query domaine', 'document pertinent'], label=1.0),
# ... plus d'exemples
]
# Fine-tuner
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=3)
Erreur : Coûts API trop élevés
Solutions :
- Cache agressif : ne jamais régénérer le même embedding
- Batch processing : grouper les requêtes
- Modèle local : passer à Sentence-BERT (gratuit)
- Modèle plus petit : OpenAI small au lieu de large
# Cache pour économiser
cache = EmbeddingCache()
embedding = cache.get_or_compute(text, model) # Réutilise si existe
Erreur : Latence API trop élevée
Solutions :
- Async requests : paralléliser les appels API
- Batch API : 1 appel pour N textes
- Pre-compute : générer embeddings à l’avance (pas en temps réel)
- Modèle local : zéro latence réseau
import asyncio
from openai import AsyncOpenAI
async def embed_async(texts):
client = AsyncOpenAI()
tasks = [
client.embeddings.create(model="text-embedding-3-small", input=text)
for text in texts
]
return await asyncio.gather(*tasks)
Erreur : Recherche multilingue ne fonctionne pas
Cause : Modèle monolingue
Solution : Utiliser un modèle multilingue
# ❌ Monolingue (EN only)
model = SentenceTransformer('all-MiniLM-L6-v2')
# ✅ Multilingue
model = SentenceTransformer('paraphrase-multilingual-mpnet-base-v2')
# OU
# OpenAI text-embedding-3-* (100+ langues)
Checklist de démarrage
Avant de déployer votre système d’embeddings en production :
Choix du modèle
- Modèle choisi selon budget et besoins
- Testé sur échantillon représentatif
- Comparé 2-3 modèles différents
- Vérifié le support multilingue si nécessaire
Chunking et préparation
- Taille de chunk optimisée (300 tokens)
- Overlap configuré (15-20%)
- Métadonnées ajoutées (titre, catégorie)
- Textes nettoyés (HTML, caractères spéciaux)
Performance
- Batch processing implémenté (batch_size=32)
- Cache mis en place pour réutilisation
- Normalisation appliquée si nécessaire
- Métriques de qualité mesurées (Recall@K)
Stockage
- Embeddings sauvegardés (pas régénérés à chaque fois)
- Métadonnées stockées avec embeddings
- Backup en place
- Version du modèle documentée
Monitoring
- Logs de qualité (pertinence résultats)
- Logs de performance (latence)
- Logs de coûts (si API)
- Alertes configurées
Ressources complémentaires
Articles liés :
Documentation :
Benchmarks :
Outils pratiques :