Comparatif bases vectorielles : Qdrant, Milvus, FAISS, pgvector | Guide complet
Après avoir exploré Pinecone, Weaviate et Chroma, découvrons les autres solutions majeures : Qdrant, Milvus, FAISS, pgvector et LanceDB.
Cet article vous donnera un tableau comparatif complet et un arbre de décision pour choisir la bonne solution.
Objectifs de l’article
Après avoir lu cet article, vous serez capable de :
- ✅ Comprendre Qdrant, Milvus, FAISS, pgvector, LanceDB
- ✅ Comparer toutes les solutions sur critères objectifs
- ✅ Utiliser l’arbre de décision pour choisir
- ✅ Implémenter avec chaque solution (code)
- ✅ Éviter les erreurs de choix coûteuses
Qdrant : Performance et Rust
Présentation
Qdrant (prononcé “quadrant”) est une base vectorielle open source écrite en Rust. Réputée pour ses performances excellentes.
Points forts :
- 🦀 Rust : Performance et sécurité mémoire
- ⚡ Très rapide : Latence <5ms
- 🐳 Docker-first : Déploiement simple
- ☁️ Qdrant Cloud : Option managée
- 📊 Dashboard : UI web intuitive
- 🔧 Payload filtering : Filtres métadonnées puissants
Installation Docker
docker run -p 6333:6333 qdrant/qdrant
Code Python
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
# Client
client = QdrantClient("localhost", port=6333)
# Créer collection
client.create_collection(
collection_name="articles",
vectors_config=VectorParams(size=384, distance=Distance.COSINE)
)
# Ajouter vecteurs
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
documents = [
"Les bases vectorielles sont essentielles.",
"Qdrant est très performant."
]
embeddings = model.encode(documents)
client.upsert(
collection_name="articles",
points=[
PointStruct(
id=1,
vector=embeddings[0].tolist(),
payload={"text": documents[0], "category": "tech"}
),
PointStruct(
id=2,
vector=embeddings[1].tolist(),
payload={"text": documents[1], "category": "tech"}
)
]
)
# Rechercher
query_embedding = model.encode(["bases de données"])[0]
results = client.search(
collection_name="articles",
query_vector=query_embedding.tolist(),
limit=2
)
for result in results:
print(f"Score: {result.score:.4f}")
print(f"Text: {result.payload['text']}")
Avantages et inconvénients
Avantages :
- ✅ Performance exceptionnelle (Rust)
- ✅ API intuitive (REST + Python + Go)
- ✅ Dashboard web inclus
- ✅ Payload filtering avancé
- ✅ Snapshots et backups
- ✅ Cloud option (Qdrant Cloud)
Inconvénients :
- ❌ Moins de documentation que Pinecone
- ❌ Communauté plus petite
- ❌ Features avancées récentes (en développement)
Quand utiliser
- ✅ Performance critique
- ✅ Self-hosting préféré
- ✅ Budget limité (vs Pinecone)
- ✅ 100K - 10M vecteurs
Milvus : Scalabilité massive
Présentation
Milvus est une base vectorielle open source conçue pour très grande échelle (milliards de vecteurs).
Points forts :
- 🏢 Enterprise-grade : LF AI Foundation
- 📈 Scalabilité : Milliards de vecteurs
- 🔧 Architecture distribuée : Kubernetes native
- ☁️ Zilliz Cloud : Version managée
- 🎯 Multi-index : HNSW, IVF, DiskANN
Architecture
┌─────────────┐
│ Clients │
└──────┬──────┘
│
┌────────▼────────┐
│ Load Balancer │
└────────┬────────┘
│
┌───────────────┼───────────────┐
│ │ │
┌────▼────┐ ┌────▼────┐ ┌────▼────┐
│ Query │ │ Query │ │ Query │
│ Node 1 │ │ Node 2 │ │ Node 3 │
└────┬────┘ └────┬────┘ └────┬────┘
│ │ │
└───────────────┼───────────────┘
│
┌────────▼────────┐
│ Data Nodes │
│ (Distributed) │
└─────────────────┘
Installation
# Docker Compose (simplifié)
docker-compose up -d
Code Python
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType
# Connexion
connections.connect("default", host="localhost", port="19530")
# Définir schéma
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=384),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=1000)
]
schema = CollectionSchema(fields, description="Articles")
# Créer collection
collection = Collection("articles", schema)
# Index (HNSW)
index_params = {
"index_type": "HNSW",
"metric_type": "COSINE",
"params": {"M": 16, "efConstruction": 200}
}
collection.create_index(field_name="embedding", index_params=index_params)
# Insérer
data = [
[1, 2, 3], # IDs
[embedding1, embedding2, embedding3], # Embeddings
["text1", "text2", "text3"] # Textes
]
collection.insert(data)
collection.load() # Charger en mémoire
# Rechercher
search_params = {"metric_type": "COSINE", "params": {"ef": 100}}
results = collection.search(
data=[query_embedding],
anns_field="embedding",
param=search_params,
limit=5,
output_fields=["text"]
)
for hit in results[0]:
print(f"ID: {hit.id}, Score: {hit.score}, Text: {hit.entity.get('text')}")
Avantages et inconvénients
Avantages :
- ✅ Scalabilité massive (milliards)
- ✅ Architecture distribuée
- ✅ Multi-index (choix algorithme)
- ✅ Enterprise support (Zilliz)
- ✅ Kubernetes native
Inconvénients :
- ❌ Complexité élevée
- ❌ Setup laborieux
- ❌ Overhead pour petites échelles
- ❌ Courbe d’apprentissage forte
Quand utiliser
- ✅ >10M vecteurs (idéalement >100M)
- ✅ Besoin de distribution
- ✅ Équipe DevOps expérimentée
- ✅ Budget et ressources
FAISS : Library meta
Présentation
FAISS (Facebook AI Similarity Search) est une library (pas une base de données) créée par Meta pour recherche vectorielle.
Points forts :
- 🚀 Très rapide : Optimisé C++
- 📚 Library : Pas de serveur
- 🎯 Multi-algorithmes : HNSW, IVF, PQ, etc.
- 🐍 Python bindings : Facile à utiliser
- 🆓 Gratuit : MIT license
Installation
pip install faiss-cpu # CPU
# ou
pip install faiss-gpu # GPU (CUDA)
Code
import faiss
import numpy as np
# Données
dimension = 384
n_vectors = 10000
vectors = np.random.randn(n_vectors, dimension).astype('float32')
# === Index Flat (Brute Force) ===
index_flat = faiss.IndexFlatL2(dimension)
index_flat.add(vectors)
# === Index HNSW ===
index_hnsw = faiss.IndexHNSWFlat(dimension, 32) # M=32
index_hnsw.add(vectors)
# === Index IVF ===
nlist = 100
quantizer = faiss.IndexFlatL2(dimension)
index_ivf = faiss.IndexIVFFlat(quantizer, dimension, nlist)
index_ivf.train(vectors) # Training nécessaire
index_ivf.add(vectors)
index_ivf.nprobe = 10
# === Recherche ===
query = np.random.randn(1, dimension).astype('float32')
D, I = index_hnsw.search(query, k=5) # Top 5
print(f"Indices: {I[0]}")
print(f"Distances: {D[0]}")
# === Sauvegarder Index ===
faiss.write_index(index_hnsw, "vectors.index")
# Charger
index_loaded = faiss.read_index("vectors.index")
Avantages et inconvénients
Avantages :
- ✅ Extrêmement rapide (C++ optimisé)
- ✅ Tous les algorithmes disponibles
- ✅ GPU support (10x+ speedup)
- ✅ Pas de serveur (library simple)
- ✅ Gratuit et open source
Inconvénients :
- ❌ Pas de métadonnées natives (juste vecteurs)
- ❌ Pas de serveur (faut construire soi-même)
- ❌ Pas de features base de données
- ❌ Gestion manuelle
Quand utiliser
- ✅ Recherche locale (pas de serveur)
- ✅ Intégration dans application existante
- ✅ Performance critique + contrôle total
- ✅ Prototypes et benchmarks
- ❌ Pas pour production complète (juste recherche)
pgvector : Extension PostgreSQL
Présentation
pgvector est une extension PostgreSQL qui ajoute le support des vecteurs.
Points forts :
- 🐘 PostgreSQL : Combine SQL + vecteurs
- 📊 Données existantes : Pas de migration nécessaire
- 🔧 Transactions : ACID compliance
- 🆓 Gratuit : Open source
Installation
-- PostgreSQL
CREATE EXTENSION vector;
Code SQL
-- Créer table avec vecteurs
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
title TEXT,
content TEXT,
embedding vector(384), -- 384 dimensions
category TEXT,
created_at TIMESTAMP DEFAULT NOW()
);
-- Créer index HNSW
CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops);
-- Insérer
INSERT INTO documents (title, content, embedding, category)
VALUES (
'Article 1',
'Contenu...',
'[0.1, 0.2, ..., 0.5]', -- 384 floats
'tech'
);
-- Recherche par similarité
SELECT
id,
title,
1 - (embedding <=> '[0.2, 0.3, ..., 0.6]') AS similarity
FROM documents
WHERE category = 'tech'
ORDER BY embedding <=> '[0.2, 0.3, ..., 0.6]'
LIMIT 5;
Code Python
import psycopg2
from pgvector.psycopg2 import register_vector
# Connexion
conn = psycopg2.connect("postgresql://user:pass@localhost/db")
register_vector(conn)
cur = conn.cursor()
# Créer table
cur.execute("""
CREATE TABLE IF NOT EXISTS documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(384)
)
""")
# Insérer
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
text = "Les bases vectorielles sont essentielles."
embedding = model.encode(text)
cur.execute(
"INSERT INTO documents (content, embedding) VALUES (%s, %s)",
(text, embedding)
)
conn.commit()
# Rechercher
query = "bases de données"
query_embedding = model.encode(query)
cur.execute(
"""
SELECT content, 1 - (embedding <=> %s) AS similarity
FROM documents
ORDER BY embedding <=> %s
LIMIT 3
""",
(query_embedding, query_embedding)
)
results = cur.fetchall()
for content, similarity in results:
print(f"{similarity:.4f}: {content}")
Avantages et inconvénients
Avantages :
- ✅ PostgreSQL = familier, mature
- ✅ Combine données SQL + vecteurs
- ✅ Transactions ACID
- ✅ Pas de nouvelle infrastructure
- ✅ Gratuit
Inconvénients :
- ❌ Performance limitée (>100K vecteurs)
- ❌ Pas optimisé pour vecteurs (vs bases dédiées)
- ❌ Scaling difficile
- ❌ Pas de features avancées
Quand utiliser
- ✅ Déjà sur PostgreSQL
- ✅ <100K vecteurs
- ✅ Combine données SQL + recherche vectorielle
- ✅ Pas de budget pour solution dédiée
- ❌ Pas pour grande échelle
LanceDB : Data Science Friendly
Présentation
LanceDB est une base vectorielle embedded avec focus data science.
Points forts :
- 📊 Format Lance : Columnar format
- 🐼 Pandas/Arrow : Intégration native
- 🆓 Open source : Apache 2.0
- 💻 Embedded : Comme Chroma
Code
import lancedb
import pandas as pd
# Créer DB
db = lancedb.connect("./lancedb")
# Créer table
data = pd.DataFrame({
"text": ["Doc 1", "Doc 2", "Doc 3"],
"category": ["tech", "ai", "tech"]
})
# Générer embeddings
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
data["vector"] = list(model.encode(data["text"]))
# Créer table
table = db.create_table("documents", data)
# Rechercher
query = "technologie"
query_vector = model.encode(query)
results = table.search(query_vector).limit(2).to_pandas()
print(results)
Quand utiliser
- ✅ Data science workflows (Pandas, Arrow)
- ✅ Notebooks Jupyter
- ✅ Embedded database
- ✅ Format columnar nécessaire
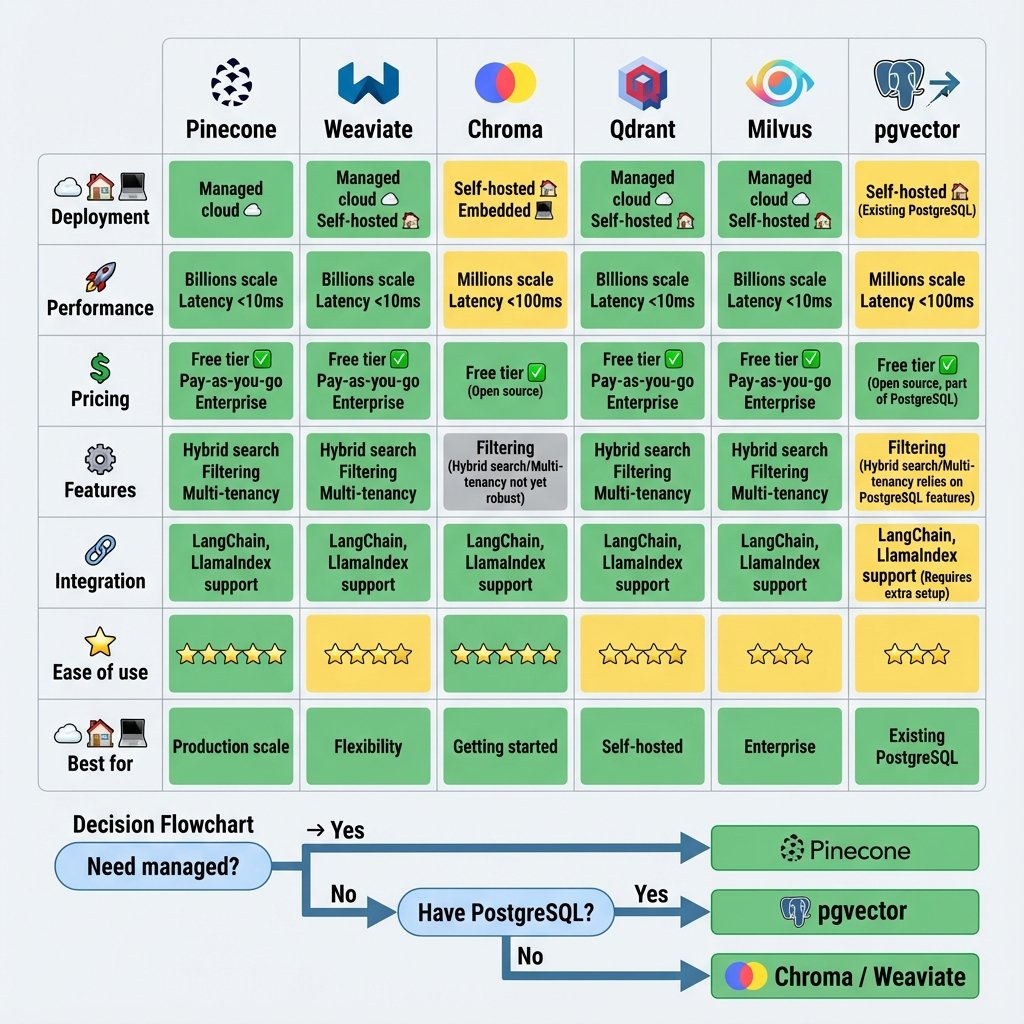
Tableau comparatif complet
| Caractéristique | Pinecone | Weaviate | Chroma | Qdrant | Milvus | FAISS | pgvector | LanceDB |
|---|---|---|---|---|---|---|---|---|
| Type | Cloud | Hybrid | Embedded | Self/Cloud | Distributed | Library | Extension | Embedded |
| Hosting | Cloud only | Both | Local/Server | Both | Self/Cloud | Local | Self | Local |
| Performance | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| Scalabilité | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| Simplicité | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Hybrid search | ✅ | ✅✅ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ |
| Metadata filtering | ✅✅ | ✅✅ | ✅ | ✅✅ | ✅ | ❌ | ✅✅ | ✅ |
| Auto-embedding | ❌ | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
| LangChain | ✅ | ✅ | ✅✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Coût | $$$ | $ | Free | $ | $$ | Free | Free | Free |
| Use Case | Prod rapide | Hybrid | Dev/Proto | Performance | Très grande échelle | Recherche locale | SQL+vectors | Data science |
| Taille idéale | 10K-100M | 10K-50M | <100K | 100K-10M | >10M | Any | <100K | <1M |
Légende
- ⭐ : 1-5 étoiles (plus = mieux)
- ✅✅ : Excellent support
- ✅ : Bon support
- ❌ : Non supporté
- $ : Gratuit ou très peu cher
- $$ : Modéré
- $$$ : Cher
Arbre de décision
Quel est votre cas d'usage ?
├─ 🚀 Démarrer rapidement, prototype
│ └─ **Chroma** (le plus simple)
│
├─ 💼 Production sans gestion infra
│ └─ **Pinecone** (cloud managé)
│
├─ 🔍 Hybrid search (vectoriel + BM25) nécessaire ?
│ └─ **Weaviate** (meilleur hybrid search)
│
├─ 📊 Déjà sur PostgreSQL + <100K vecteurs ?
│ └─ **pgvector** (intégrer dans DB existante)
│
├─ ⚡ Performance critique + self-hosting ?
│ └─ **Qdrant** (Rust, très rapide)
│
├─ 📈 Très grande échelle (>10M vecteurs) ?
│ ├─ Distribution nécessaire ?
│ │ └─ **Milvus** (architecture distribuée)
│ └─ Single-node suffisant ?
│ └─ **Qdrant** ou **Weaviate**
│
├─ 🔬 Juste recherche (pas de DB) + contrôle total ?
│ └─ **FAISS** (library, intégrer vous-même)
│
└─ 📓 Data science workflows (Pandas, notebooks) ?
└─ **LanceDB** (columnar, data-friendly)
Matrice de décision par critères
Par budget
| Budget | Solutions |
|---|---|
| Gratuit | Chroma, FAISS, pgvector, LanceDB, Qdrant/Weaviate (self-hosted) |
| <$100/mois | Pinecone Starter, Weaviate Cloud, Qdrant Cloud |
| >$100/mois | Pinecone Standard, Milvus (Zilliz), setup custom |
Par taille dataset
| Vecteurs | Solutions |
|---|---|
| <10K | Chroma, FAISS, pgvector |
| 10K-100K | Chroma, Qdrant, Weaviate, pgvector |
| 100K-1M | Pinecone, Qdrant, Weaviate |
| 1M-10M | Pinecone, Qdrant, Weaviate, Milvus |
| >10M | Pinecone Enterprise, Milvus, Qdrant (sharding) |
Par équipe
| Équipe | Solutions |
|---|---|
| Solo dev | Chroma, FAISS, LanceDB |
| Petite équipe (2-5) | Chroma (server), Qdrant, Weaviate |
| Startup tech | Pinecone, Qdrant Cloud, Weaviate Cloud |
| Équipe DevOps | Qdrant, Weaviate, Milvus (self-hosted) |
| Enterprise | Pinecone Enterprise, Milvus, Qdrant + infra |
Recommandations par profil
Débutant en IA
Chroma → Simple, gratuit, parfait pour apprendre
Startup MVP
Pinecone → Setup rapide, pas de DevOps, scalable
Équipe avec DevOps
Qdrant ou Weaviate → Self-hosting, contrôle, économies
Application enterprise
Milvus (grande échelle) ou Pinecone Enterprise
Besoin Hybrid Search
Weaviate → Le meilleur hybrid search natif
Déjà sur PostgreSQL
pgvector → Intégrer directement dans DB existante
Chercheur / Data Scientist
FAISS ou LanceDB → Contrôle total, notebooks-friendly
Conclusion
Il n’y a pas de meilleure solution universelle. Le choix dépend de :
✅ Budget (gratuit vs managé) ✅ Taille (10K vs 10M vs 100M vecteurs) ✅ Équipe (solo vs DevOps) ✅ Features (hybrid search, filtres, etc.) ✅ Hosting (cloud vs self-hosted)
Nos top picks
- Débuter : Chroma (simplicité)
- Production rapide : Pinecone (managé)
- Performance : Qdrant (Rust, rapide)
- Hybrid search : Weaviate (unique)
- Très grande échelle : Milvus (distribution)
- PostgreSQL : pgvector (intégration)
- Recherche locale : FAISS (library)
Dans le prochain article, nous aborderons le déploiement en production avec monitoring, scalabilité, et optimisations.
👉 Article 8 : Déploiement Production et Optimisation
Ressources Complémentaires
Articles liés :
Documentation :