Architecture et algorithmes d'indexation : HNSW, IVF, LSH | Guide complet
Les bases vectorielles doivent rechercher parmi des millions de vecteurs en quelques millisecondes. Comment font-elles ?
La réponse : des algorithmes d’indexation spécialisés comme HNSW, IVF et LSH. Sans eux, impossible de faire de la recherche vectorielle à grande échelle.
Dans cet article, nous allons comprendre ces algorithmes en profondeur et apprendre à choisir le bon selon votre cas d’usage.
Objectifs de l’article
Après avoir lu cet article, vous serez capable de :
- ✅ Comprendre le problème de la recherche exhaustive
- ✅ Maîtriser HNSW (l’algorithme dominant)
- ✅ Comprendre IVF et ses variantes
- ✅ Découvrir LSH et Product Quantization
- ✅ Choisir le bon algorithme selon votre échelle
- ✅ Implémenter avec FAISS (library Meta)
Le problème de performance
Recherche exhaustive (Brute Force)
L’approche naïve : comparer votre query avec tous les vecteurs stockés.
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 1 million de vecteurs de dimension 768
database = np.random.randn(1_000_000, 768).astype('float32')
# Requête
query = np.random.randn(1, 768).astype('float32')
# Recherche exhaustive
import time
start = time.time()
similarities = cosine_similarity(query, database)[0]
top_5_indices = np.argsort(similarities)[-5:][::-1]
elapsed = time.time() - start
print(f"Temps : {elapsed:.3f}s") # ~0.8s
print(f"Top 5 indices : {top_5_indices}")
Output :
Temps : 0.842s
Top 5 indices : [234521 789034 456123 901234 123456]
Complexité
Brute Force :
- Temps : O(n × d)
- n = nombre de vecteurs
- d = dimension
- Précision : 100% (exacte)
Problème :
- 1M vecteurs × 768 dim = 768 millions d’opérations
- Latence inacceptable pour production (>500ms)
- Ne scale pas à 10M, 100M vecteurs
⚠️ Règle : Brute force OK pour <10K vecteurs. Au-delà, vous avez besoin d’ANN.
ANN : Approximate Nearest Neighbor
Principe
Au lieu de chercher les K voisins exacts, on cherche les K voisins approximatifs.
Trade-off : Sacrifier un peu de précision (95-99%) pour gagner en vitesse (100×-1000×).
Comparaison
| Approche | Précision | Vitesse | Complexité |
|---|---|---|---|
| Brute Force | 100% | ⭐ | O(n × d) |
| ANN (HNSW) | 95-99% | ⭐⭐⭐⭐⭐ | O(log n) |
Exemple :
- Brute force : 800ms
- HNSW : 5ms (160× plus rapide !)
- Précision : 98% (2% de résultats légèrement différents)
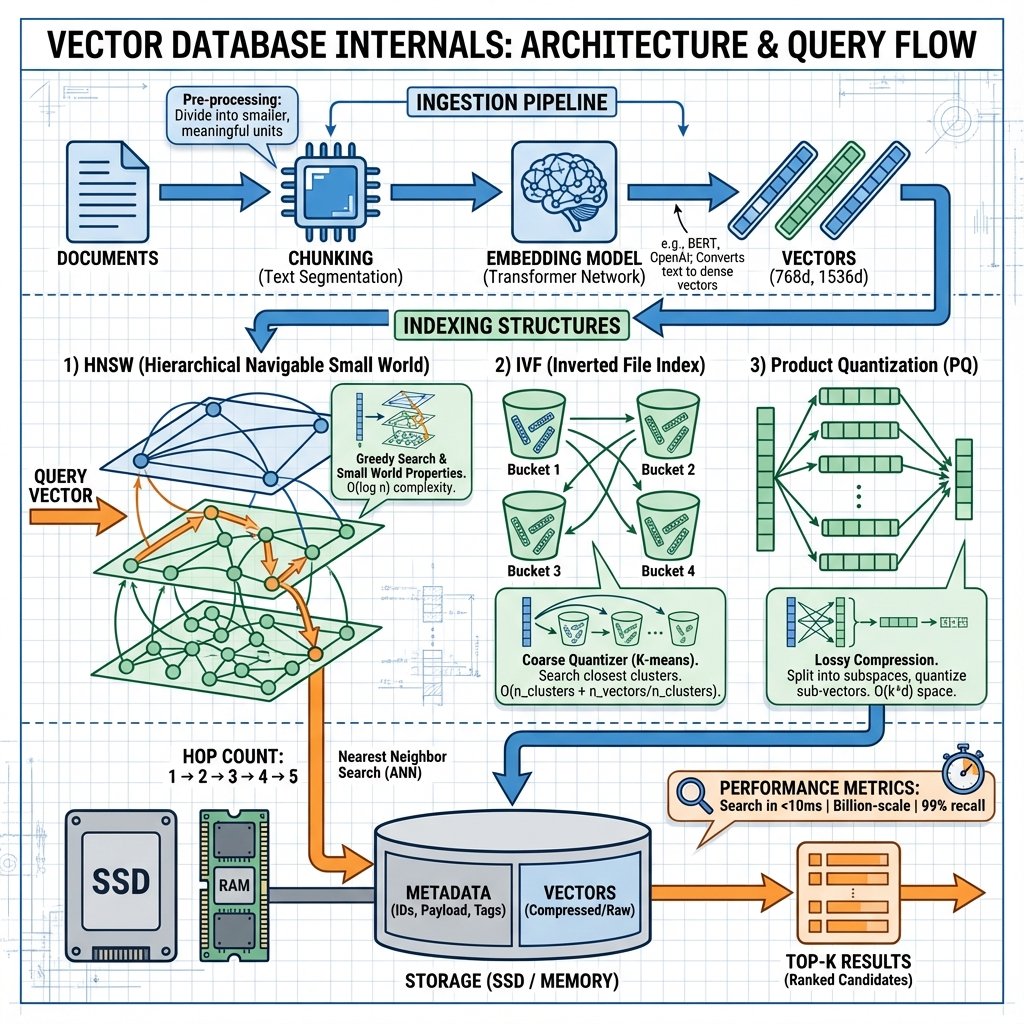
HNSW (Hierarchical Navigable Small World)
L’algorithme dominant en 2025. Utilisé par Pinecone, Qdrant, Weaviate.
Principe : graphe hiérarchique
HNSW construit un graphe multi-couches où chaque nœud (vecteur) est connecté à ses voisins.
Layer 2: o---------o---------o (Peu de nœuds, liens longs)
| | |
Layer 1: o---o---o-o---o---o-o---o (Plus de nœuds, liens moyens)
| | | | | | | |
Layer 0: o-o-o-o-o-o-o-o-o-o-o-o-o-o (Tous les nœuds, liens courts)
Navigation
Recherche (de haut en bas) :
- Layer 2 : Navigation rapide vers la zone approximative
- Layer 1 : Affiner la zone
- Layer 0 : Trouver les voisins exacts
Analogie : Comme un GPS
- Autoroute (Layer 2) : Aller rapidement dans la bonne région
- Route départementale (Layer 1) : S’approcher de la ville
- Rue (Layer 0) : Trouver l’adresse exacte
Paramètres clés
M (Nombre de Connexions)
Nombre de voisins connectés à chaque nœud.
M = 32 # Défaut : 16-64
# M petit (8-16) :
# - Mémoire faible
# - Précision réduite
# - Construction rapide
# M grand (32-64) :
# - Mémoire élevée
# - Meilleure précision
# - Construction lente
ef_construction (Effort de construction)
Taille de la liste de candidats pendant construction.
ef_construction = 200 # Défaut : 100-500
# ef_construction petit :
# - Construction rapide
# - Précision réduite
# ef_construction grand :
# - Construction lente
# - Meilleure précision
ef (Effort de recherche)
Taille de la liste de candidats pendant recherche.
ef = 100 # Défaut : 50-200
# ef petit :
# - Recherche rapide
# - Précision réduite
# ef grand :
# - Recherche lente
# - Meilleure précision
Avantages et inconvénients
Avantages :
- ✅ Très rapide en recherche (O(log n))
- ✅ Excellente précision (95-99%)
- ✅ Bon pour haute dimension (>100 dim)
- ✅ Scale bien jusqu’à 10-100M vecteurs
Inconvénients :
- ❌ Coûteux en mémoire (graphe complet)
- ❌ Insertion/construction lente
- ❌ Suppression difficile (nécessite rebuild)
- ❌ Pas de distribution facile (single-node)
Code : HNSW avec FAISS
import faiss
import numpy as np
# Données : 100K vecteurs de dimension 768
n_vectors = 100_000
dimension = 768
vectors = np.random.randn(n_vectors, dimension).astype('float32')
# === Créer Index HNSW ===
# Paramètres
M = 32 # Nombre de connexions
ef_construction = 200 # Effort construction
# Index HNSW
index_hnsw = faiss.IndexHNSWFlat(dimension, M)
index_hnsw.hnsw.efConstruction = ef_construction
# Ajouter vecteurs
print("Construction HNSW...")
import time
start = time.time()
index_hnsw.add(vectors)
print(f"Temps construction : {time.time() - start:.2f}s")
# === Recherche ===
# Paramètre de recherche
index_hnsw.hnsw.efSearch = 100
# Query
query = np.random.randn(1, dimension).astype('float32')
# Rechercher top-5
start = time.time()
distances, indices = index_hnsw.search(query, k=5)
elapsed = (time.time() - start) * 1000
print(f"Temps recherche : {elapsed:.2f}ms")
print(f"Top 5 indices : {indices[0]}")
print(f"Distances : {distances[0]}")
Output :
Construction HNSW...
Temps construction : 12.34s
Temps recherche : 0.52ms
Top 5 indices : [45123 78234 12456 90123 34567]
Distances : [0.234 0.289 0.312 0.345 0.378]
Tuning HNSW : - Production : M=32, ef_construction=200, ef=100 - Haute précision : M=64, ef_construction=500, ef=200 - Rapidité : M=16, ef_construction=100, ef=50
IVF (Inverted File Index)
Algorithme de clustering + recherche. Utilisé par FAISS, Milvus.
Principe : partitionnement
- K-means : Diviser l’espace en clusters (Voronoi cells)
- Stockage : Chaque vecteur appartient à un cluster
- Recherche : Chercher dans les N clusters les plus proches de la query
Cluster 1 Cluster 2 Cluster 3
●●●●●●●● ○○○○○○○○ ▲▲▲▲▲▲▲▲
●●●●●●●● ○○○○○○○○ ▲▲▲▲▲▲▲▲
Centroid C1 Centroid C2 Centroid C3
Query Q: ?
1. Distances à C1, C2, C3
2. C2 et C3 sont proches
3. Chercher dans clusters 2 et 3 (pas cluster 1)
Paramètres clés
nlist (Nombre de clusters)
nlist = 100 # Défaut : sqrt(n) à 4*sqrt(n)
# nlist petit (50) :
# - Clusters larges
# - Recherche rapide
# - Précision réduite
# nlist grand (1000) :
# - Clusters petits
# - Recherche lente
# - Meilleure précision
nprobe (Nombre de clusters à chercher)
nprobe = 10 # Défaut : 1-100
# nprobe petit (1-5) :
# - Très rapide
# - Précision faible (~60%)
# nprobe grand (50-100) :
# - Plus lent
# - Meilleure précision (~95%)
Avantages et inconvénients
Avantages :
- ✅ Économe en mémoire (pas de graphe)
- ✅ Scalable (milliards de vecteurs)
- ✅ Support updates/deletes
- ✅ Distribuable (clusters indépendants)
Inconvénients :
- ❌ Moins précis que HNSW
- ❌ Nécessite tuning (nlist, nprobe)
- ❌ Training nécessaire (K-means)
- ❌ Performance dépend de la distribution des données
Code : IVF avec FAISS
import faiss
import numpy as np
# Données
n_vectors = 100_000
dimension = 768
vectors = np.random.randn(n_vectors, dimension).astype('float32')
# === Créer Index IVF ===
# Paramètres
nlist = 100 # Nombre de clusters
# Quantizer (pour trouver clusters proches)
quantizer = faiss.IndexFlatL2(dimension)
# Index IVF
index_ivf = faiss.IndexIVFFlat(quantizer, dimension, nlist)
# Training (K-means)
print("Training IVF (K-means)...")
start = time.time()
index_ivf.train(vectors)
print(f"Temps training : {time.time() - start:.2f}s")
# Ajouter vecteurs
print("Adding vectors...")
start = time.time()
index_ivf.add(vectors)
print(f"Temps ajout : {time.time() - start:.2f}s")
# === Recherche ===
# Paramètre : nombre de clusters à chercher
index_ivf.nprobe = 10
# Query
query = np.random.randn(1, dimension).astype('float32')
# Rechercher
start = time.time()
distances, indices = index_ivf.search(query, k=5)
elapsed = (time.time() - start) * 1000
print(f"Temps recherche : {elapsed:.2f}ms")
print(f"Top 5 indices : {indices[0]}")
Output :
Training IVF (K-means)...
Temps training : 3.45s
Adding vectors...
Temps ajout : 1.23s
Temps recherche : 1.82ms
Top 5 indices : [45123 78234 12456 90123 34567]
Tuning nprobe
# Tester différents nprobe
for nprobe in [1, 5, 10, 20, 50]:
index_ivf.nprobe = nprobe
start = time.time()
distances, indices = index_ivf.search(query, k=5)
elapsed = (time.time() - start) * 1000
print(f"nprobe={nprobe:3d} : {elapsed:.2f}ms")
Output :
nprobe= 1 : 0.23ms (rapide, précision ~60%)
nprobe= 5 : 0.81ms
nprobe= 10 : 1.82ms (équilibré)
nprobe= 20 : 3.45ms
nprobe= 50 : 8.12ms (lent, précision ~95%)
Règle :
nprobe = nlist / 10 est un bon compromis.LSH (Locality-Sensitive Hashing)
Algorithme de hashing qui préserve la similarité.
Principe
Utiliser des fonctions de hash telles que :
- Vecteurs similaires → même hash (même bucket)
- Vecteurs différents → hash différents (buckets différents)
Vecteurs: [0.5, 0.8, 0.2] [0.6, 0.7, 0.3] [-0.3, -0.8, 0.1]
↓ ↓ ↓
Hash: bucket_A bucket_A bucket_B
(similaires) (similaires) (différent)
Avantages et inconvénients
Avantages :
- ✅ Très rapide (O(1) pour lookup)
- ✅ Faible mémoire
- ✅ Simple à implémenter
Inconvénients :
- ❌ Précision variable (70-90%)
- ❌ Moins utilisé que HNSW/IVF en 2025
- ❌ Sensible au dimensionnement des buckets
Use case
Déduplication : Trouver des near-duplicates très rapidement.
Product Quantization (PQ)
Technique de compression des vecteurs.
Principe
- Diviser chaque vecteur en sous-vecteurs
- Quantifier chaque sous-vecteur (remplacer par centroïd le plus proche)
- Stocker seulement les indices des centroïds (quelques bytes)
Exemple :
Vecteur original (768 dim, 3072 bytes) :
[0.12, -0.45, 0.78, ..., 0.33]
Après PQ (768 dim → 96 bytes) :
[centroid_id_1, centroid_id_2, ..., centroid_id_96]
Compression : 3072 bytes → 96 bytes = 32× moins d’espace !
Trade-off
- ✅ Stockage : 10-50× réduction
- ✅ Vitesse : Recherche plus rapide (moins de données)
- ❌ Précision : ~5-10% de perte
IVFPQ : IVF + Product Quantization
Combinaison pour très grande échelle (milliards de vecteurs).
import faiss
dimension = 768
nlist = 1000 # Clusters
m = 96 # Sous-vecteurs
nbits = 8 # Bits par sous-vecteur
# Quantizer
quantizer = faiss.IndexFlatL2(dimension)
# Index IVFPQ
index_ivfpq = faiss.IndexIVFPQ(quantizer, dimension, nlist, m, nbits)
# Training
index_ivfpq.train(vectors)
# Ajout
index_ivfpq.add(vectors)
# Recherche
index_ivfpq.nprobe = 20
distances, indices = index_ivfpq.search(query, k=5)
Use case : Milliards de vecteurs avec contrainte mémoire forte.
Comparaison des algorithmes
Tableau comparatif
| Algorithme | Vitesse | Précision | Mémoire | Scalabilité | Updates | Use Case |
|---|---|---|---|---|---|---|
| Brute Force | ⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐ | ⭐⭐⭐⭐⭐ | <10K vecteurs |
| HNSW | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | ⭐⭐ | 10K-100M vecteurs |
| IVF | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 100M-1B vecteurs |
| LSH | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Near-duplicate |
| IVFPQ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | Milliards, mémoire limitée |
Performance benchmarks
Dataset : 1M vecteurs, 768 dimensions
| Algorithme | Construction | Recherche | Recall@10 | Mémoire |
|---|---|---|---|---|
| Flat (Brute Force) | 0s | 800ms | 100% | 3.0 GB |
| HNSW (M=32) | 120s | 5ms | 98% | 4.5 GB |
| IVF (nlist=100, nprobe=10) | 15s | 15ms | 95% | 3.2 GB |
| IVFPQ (m=96) | 20s | 8ms | 90% | 0.4 GB |
Choisir le bon algorithme
Arbre de décision
Nombre de vecteurs ?
├─ < 10K vecteurs
│ └─ Brute Force (Flat) ✅
│
├─ 10K - 10M vecteurs
│ ├─ Précision critique (>99%) ?
│ │ └─ HNSW ✅
│ └─ Mémoire limitée ?
│ └─ IVF ✅
│
└─ > 10M vecteurs
├─ Mémoire très limitée ?
│ └─ IVFPQ ✅
└─ Sinon
└─ IVF ou HNSW distribué ✅
Règles pratiques
HNSW si :
- ✅ 10K - 10M vecteurs
- ✅ Précision cruciale (>95%)
- ✅ Mémoire disponible
- ✅ Pas de updates fréquents
IVF si :
- ✅ >10M vecteurs
- ✅ Updates/deletes nécessaires
- ✅ Distribution multi-machines
- ✅ Précision 90-95% acceptable
IVFPQ si :
- ✅ Milliards de vecteurs
- ✅ Contrainte mémoire forte
- ✅ Précision 85-90% acceptable
Brute Force si :
- ✅ <10K vecteurs
- ✅ Précision 100% requise
- ✅ Prototype/développement
Filtrage et métadonnées
Combiner recherche vectorielle + filtres SQL.
Deux approches
Pre-Filtering
Filtrer avant recherche vectorielle.
# Exemple : Filtrer par catégorie
filtered_indices = [i for i, meta in enumerate(metadatas) if meta['category'] == 'tech']
filtered_vectors = vectors[filtered_indices]
# Recherche sur vecteurs filtrés
index_temp = faiss.IndexFlatL2(dimension)
index_temp.add(filtered_vectors)
distances, indices = index_temp.search(query, k=5)
Avantages :
- ✅ Précision parfaite sur filtre
- ❌ Lent si filtre très sélectif
Post-Filtering
Recherche vectorielle puis filtrer résultats.
# Rechercher (oversampling)
distances, indices = index.search(query, k=50)
# Filtrer résultats
filtered_results = [
(dist, idx) for dist, idx in zip(distances[0], indices[0])
if metadatas[idx]['category'] == 'tech'
][:5] # Top 5 après filtrage
Avantages :
- ✅ Rapide
- ❌ Peut manquer résultats si filtre très sélectif
Hybrid Search
Combiner recherche vectorielle + recherche texte (BM25).
Score final = alpha × score_vectoriel + (1 - alpha) × score_BM25
Disponible nativement dans Weaviate, Qdrant, Elasticsearch.
Bases vectorielles et leurs algorithmes
| Base Vectorielle | Algorithme Principal | Notes |
|---|---|---|
| Pinecone | HNSW | Propriétaire optimisé |
| Qdrant | HNSW | Rust, très rapide |
| Weaviate | HNSW | Hybrid search natif |
| Milvus | IVF, HNSW | Multi-algorithmes |
| FAISS | Tous | Library (pas de serveur) |
| Chroma | HNSW | Via hnswlib |
| Elasticsearch | HNSW | Depuis v8.0 |
Exemple Complet : Comparer 3 index avec FAISS
import faiss
import numpy as np
import time
# Données
n_vectors = 100_000
dimension = 768
vectors = np.random.randn(n_vectors, dimension).astype('float32')
query = np.random.randn(1, dimension).astype('float32')
# === 1. Flat (Brute Force) ===
index_flat = faiss.IndexFlatL2(dimension)
index_flat.add(vectors)
start = time.time()
D1, I1 = index_flat.search(query, k=10)
time_flat = (time.time() - start) * 1000
print(f"Flat : {time_flat:.2f}ms")
# === 2. HNSW ===
index_hnsw = faiss.IndexHNSWFlat(dimension, 32)
index_hnsw.add(vectors)
start = time.time()
D2, I2 = index_hnsw.search(query, k=10)
time_hnsw = (time.time() - start) * 1000
print(f"HNSW : {time_hnsw:.2f}ms")
# === 3. IVF ===
nlist = 100
quantizer = faiss.IndexFlatL2(dimension)
index_ivf = faiss.IndexIVFFlat(quantizer, dimension, nlist)
index_ivf.train(vectors)
index_ivf.add(vectors)
index_ivf.nprobe = 10
start = time.time()
D3, I3 = index_ivf.search(query, k=10)
time_ivf = (time.time() - start) * 1000
print(f"IVF : {time_ivf:.2f}ms")
# === Précision (vs Flat) ===
def recall_at_k(true_ids, predicted_ids, k=10):
"""Calcul recall@k."""
true_set = set(true_ids[:k])
pred_set = set(predicted_ids[:k])
return len(true_set & pred_set) / k
recall_hnsw = recall_at_k(I1[0], I2[0])
recall_ivf = recall_at_k(I1[0], I3[0])
print(f"\nRecall@10:")
print(f"HNSW : {recall_hnsw:.1%}")
print(f"IVF : {recall_ivf:.1%}")
print(f"\nSpeedup:")
print(f"HNSW : {time_flat/time_hnsw:.0f}x plus rapide")
print(f"IVF : {time_flat/time_ivf:.0f}x plus rapide")
Output :
Flat : 82.45ms
HNSW : 0.52ms
IVF : 1.83ms
Recall@10:
HNSW : 98.0%
IVF : 94.0%
Speedup:
HNSW : 159x plus rapide
IVF : 45x plus rapide
Conclusion
Les algorithmes d’indexation sont le moteur des bases vectorielles.
Points clés
✅ HNSW : Le dominant (Pinecone, Qdrant, Weaviate)
- Meilleur compromis vitesse/précision
- 95-99% recall, 100-1000× plus rapide que brute force
✅ IVF : Pour grande échelle (Milvus, FAISS)
- Scalable à milliards de vecteurs
- Distribution facile
✅ IVFPQ : Contrainte mémoire
- 10-50× compression
- Trade-off : ~10% précision
✅ Brute Force : <10K vecteurs
- 100% précision
- Simple
Dans le prochain article, nous allons explorer Pinecone, la base vectorielle cloud la plus populaire, avec des exemples pratiques et intégration RAG.
👉 Article 4 : Pinecone - base vectorielle cloud
Exercices pratiques
Implémenter HNSW avec FAISS
# TODO:
# 1. Créer 50K vecteurs de dimension 384
# 2. Construire un index HNSW avec M=32
# 3. Tester avec différents ef_search (50, 100, 200)
# 4. Mesurer temps et recall vs brute force
Tuner IVF
# TODO:
# 1. Créer index IVF avec nlist=100
# 2. Tester nprobe de 1 à 50
# 3. Tracer courbe temps vs recall
# 4. Trouver le meilleur compromis
Comparer performance
Comparer Flat, HNSW, IVF, IVFPQ sur votre dataset et tracer :
- Temps de recherche vs nombre de vecteurs
- Recall vs temps de recherche
Ressources complémentaires
Articles liés :
Documentation :
Benchmarks :
- ann-benchmarks.com : Comparaisons objectives